What is an Indicator?
An indicator provides a measure of a concept, and is typically used in quantitative research.
It is useful to distinguish between an indicator and a measure:
Measures refer to things that can be relatively unambiguously counted, such as personal income, household income, age, number of children, or number of years spent at school. Measures, in other words, are quantities. If we are interested in some of the changes in personal income, the latter can be quantified in a reasonably direct way (assuming we have access to all the relevant data).
Sociologists use indicators to tap concepts that are less directly quantifiable, such as job satisfaction. If we are interested in the causes of variation of job satisfaction, we will need indicators that stand for the concept of ‘job satisfaction’. These indicators will allow the level of ‘job satisfaction’ to be measured, and we can treat the resulting quantitative information as if it were a measure.
An indicator, then, is something which is devised that is employed as though it were a measure of a concept.
Direct and Indirect indicators
Direct indicators are ones which are closely related to the concept being measured. For example questions about how much a person earns each much are direct indicators of personal income; but the same question would only be an indirect measurement of the concept of social class background.

Share this:
Leave a reply cancel reply.
This site uses Akismet to reduce spam. Learn how your comment data is processed .
Discover more from ReviseSociology
Frequently asked questions
What’s the difference between concepts, variables, and indicators.
In scientific research, concepts are the abstract ideas or phenomena that are being studied (e.g., educational achievement). Variables are properties or characteristics of the concept (e.g., performance at school), while indicators are ways of measuring or quantifying variables (e.g., yearly grade reports).
The process of turning abstract concepts into measurable variables and indicators is called operationalization .
Frequently asked questions: Methodology
Attrition refers to participants leaving a study. It always happens to some extent—for example, in randomized controlled trials for medical research.
Differential attrition occurs when attrition or dropout rates differ systematically between the intervention and the control group . As a result, the characteristics of the participants who drop out differ from the characteristics of those who stay in the study. Because of this, study results may be biased .
Action research is conducted in order to solve a particular issue immediately, while case studies are often conducted over a longer period of time and focus more on observing and analyzing a particular ongoing phenomenon.
Action research is focused on solving a problem or informing individual and community-based knowledge in a way that impacts teaching, learning, and other related processes. It is less focused on contributing theoretical input, instead producing actionable input.
Action research is particularly popular with educators as a form of systematic inquiry because it prioritizes reflection and bridges the gap between theory and practice. Educators are able to simultaneously investigate an issue as they solve it, and the method is very iterative and flexible.
A cycle of inquiry is another name for action research . It is usually visualized in a spiral shape following a series of steps, such as “planning → acting → observing → reflecting.”
To make quantitative observations , you need to use instruments that are capable of measuring the quantity you want to observe. For example, you might use a ruler to measure the length of an object or a thermometer to measure its temperature.
Criterion validity and construct validity are both types of measurement validity . In other words, they both show you how accurately a method measures something.
While construct validity is the degree to which a test or other measurement method measures what it claims to measure, criterion validity is the degree to which a test can predictively (in the future) or concurrently (in the present) measure something.
Construct validity is often considered the overarching type of measurement validity . You need to have face validity , content validity , and criterion validity in order to achieve construct validity.
Convergent validity and discriminant validity are both subtypes of construct validity . Together, they help you evaluate whether a test measures the concept it was designed to measure.
- Convergent validity indicates whether a test that is designed to measure a particular construct correlates with other tests that assess the same or similar construct.
- Discriminant validity indicates whether two tests that should not be highly related to each other are indeed not related. This type of validity is also called divergent validity .
You need to assess both in order to demonstrate construct validity. Neither one alone is sufficient for establishing construct validity.
- Discriminant validity indicates whether two tests that should not be highly related to each other are indeed not related
Content validity shows you how accurately a test or other measurement method taps into the various aspects of the specific construct you are researching.
In other words, it helps you answer the question: “does the test measure all aspects of the construct I want to measure?” If it does, then the test has high content validity.
The higher the content validity, the more accurate the measurement of the construct.
If the test fails to include parts of the construct, or irrelevant parts are included, the validity of the instrument is threatened, which brings your results into question.
Face validity and content validity are similar in that they both evaluate how suitable the content of a test is. The difference is that face validity is subjective, and assesses content at surface level.
When a test has strong face validity, anyone would agree that the test’s questions appear to measure what they are intended to measure.
For example, looking at a 4th grade math test consisting of problems in which students have to add and multiply, most people would agree that it has strong face validity (i.e., it looks like a math test).
On the other hand, content validity evaluates how well a test represents all the aspects of a topic. Assessing content validity is more systematic and relies on expert evaluation. of each question, analyzing whether each one covers the aspects that the test was designed to cover.
A 4th grade math test would have high content validity if it covered all the skills taught in that grade. Experts(in this case, math teachers), would have to evaluate the content validity by comparing the test to the learning objectives.
Snowball sampling is a non-probability sampling method . Unlike probability sampling (which involves some form of random selection ), the initial individuals selected to be studied are the ones who recruit new participants.
Because not every member of the target population has an equal chance of being recruited into the sample, selection in snowball sampling is non-random.
Snowball sampling is a non-probability sampling method , where there is not an equal chance for every member of the population to be included in the sample .
This means that you cannot use inferential statistics and make generalizations —often the goal of quantitative research . As such, a snowball sample is not representative of the target population and is usually a better fit for qualitative research .
Snowball sampling relies on the use of referrals. Here, the researcher recruits one or more initial participants, who then recruit the next ones.
Participants share similar characteristics and/or know each other. Because of this, not every member of the population has an equal chance of being included in the sample, giving rise to sampling bias .
Snowball sampling is best used in the following cases:
- If there is no sampling frame available (e.g., people with a rare disease)
- If the population of interest is hard to access or locate (e.g., people experiencing homelessness)
- If the research focuses on a sensitive topic (e.g., extramarital affairs)
The reproducibility and replicability of a study can be ensured by writing a transparent, detailed method section and using clear, unambiguous language.
Reproducibility and replicability are related terms.
- Reproducing research entails reanalyzing the existing data in the same manner.
- Replicating (or repeating ) the research entails reconducting the entire analysis, including the collection of new data .
- A successful reproduction shows that the data analyses were conducted in a fair and honest manner.
- A successful replication shows that the reliability of the results is high.
Stratified sampling and quota sampling both involve dividing the population into subgroups and selecting units from each subgroup. The purpose in both cases is to select a representative sample and/or to allow comparisons between subgroups.
The main difference is that in stratified sampling, you draw a random sample from each subgroup ( probability sampling ). In quota sampling you select a predetermined number or proportion of units, in a non-random manner ( non-probability sampling ).
Purposive and convenience sampling are both sampling methods that are typically used in qualitative data collection.
A convenience sample is drawn from a source that is conveniently accessible to the researcher. Convenience sampling does not distinguish characteristics among the participants. On the other hand, purposive sampling focuses on selecting participants possessing characteristics associated with the research study.
The findings of studies based on either convenience or purposive sampling can only be generalized to the (sub)population from which the sample is drawn, and not to the entire population.
Random sampling or probability sampling is based on random selection. This means that each unit has an equal chance (i.e., equal probability) of being included in the sample.
On the other hand, convenience sampling involves stopping people at random, which means that not everyone has an equal chance of being selected depending on the place, time, or day you are collecting your data.
Convenience sampling and quota sampling are both non-probability sampling methods. They both use non-random criteria like availability, geographical proximity, or expert knowledge to recruit study participants.
However, in convenience sampling, you continue to sample units or cases until you reach the required sample size.
In quota sampling, you first need to divide your population of interest into subgroups (strata) and estimate their proportions (quota) in the population. Then you can start your data collection, using convenience sampling to recruit participants, until the proportions in each subgroup coincide with the estimated proportions in the population.
A sampling frame is a list of every member in the entire population . It is important that the sampling frame is as complete as possible, so that your sample accurately reflects your population.
Stratified and cluster sampling may look similar, but bear in mind that groups created in cluster sampling are heterogeneous , so the individual characteristics in the cluster vary. In contrast, groups created in stratified sampling are homogeneous , as units share characteristics.
Relatedly, in cluster sampling you randomly select entire groups and include all units of each group in your sample. However, in stratified sampling, you select some units of all groups and include them in your sample. In this way, both methods can ensure that your sample is representative of the target population .
A systematic review is secondary research because it uses existing research. You don’t collect new data yourself.
The key difference between observational studies and experimental designs is that a well-done observational study does not influence the responses of participants, while experiments do have some sort of treatment condition applied to at least some participants by random assignment .
An observational study is a great choice for you if your research question is based purely on observations. If there are ethical, logistical, or practical concerns that prevent you from conducting a traditional experiment , an observational study may be a good choice. In an observational study, there is no interference or manipulation of the research subjects, as well as no control or treatment groups .
It’s often best to ask a variety of people to review your measurements. You can ask experts, such as other researchers, or laypeople, such as potential participants, to judge the face validity of tests.
While experts have a deep understanding of research methods , the people you’re studying can provide you with valuable insights you may have missed otherwise.
Face validity is important because it’s a simple first step to measuring the overall validity of a test or technique. It’s a relatively intuitive, quick, and easy way to start checking whether a new measure seems useful at first glance.
Good face validity means that anyone who reviews your measure says that it seems to be measuring what it’s supposed to. With poor face validity, someone reviewing your measure may be left confused about what you’re measuring and why you’re using this method.
Face validity is about whether a test appears to measure what it’s supposed to measure. This type of validity is concerned with whether a measure seems relevant and appropriate for what it’s assessing only on the surface.
Statistical analyses are often applied to test validity with data from your measures. You test convergent validity and discriminant validity with correlations to see if results from your test are positively or negatively related to those of other established tests.
You can also use regression analyses to assess whether your measure is actually predictive of outcomes that you expect it to predict theoretically. A regression analysis that supports your expectations strengthens your claim of construct validity .
When designing or evaluating a measure, construct validity helps you ensure you’re actually measuring the construct you’re interested in. If you don’t have construct validity, you may inadvertently measure unrelated or distinct constructs and lose precision in your research.
Construct validity is often considered the overarching type of measurement validity , because it covers all of the other types. You need to have face validity , content validity , and criterion validity to achieve construct validity.
Construct validity is about how well a test measures the concept it was designed to evaluate. It’s one of four types of measurement validity , which includes construct validity, face validity , and criterion validity.
There are two subtypes of construct validity.
- Convergent validity : The extent to which your measure corresponds to measures of related constructs
- Discriminant validity : The extent to which your measure is unrelated or negatively related to measures of distinct constructs
Naturalistic observation is a valuable tool because of its flexibility, external validity , and suitability for topics that can’t be studied in a lab setting.
The downsides of naturalistic observation include its lack of scientific control , ethical considerations , and potential for bias from observers and subjects.
Naturalistic observation is a qualitative research method where you record the behaviors of your research subjects in real world settings. You avoid interfering or influencing anything in a naturalistic observation.
You can think of naturalistic observation as “people watching” with a purpose.
A dependent variable is what changes as a result of the independent variable manipulation in experiments . It’s what you’re interested in measuring, and it “depends” on your independent variable.
In statistics, dependent variables are also called:
- Response variables (they respond to a change in another variable)
- Outcome variables (they represent the outcome you want to measure)
- Left-hand-side variables (they appear on the left-hand side of a regression equation)
An independent variable is the variable you manipulate, control, or vary in an experimental study to explore its effects. It’s called “independent” because it’s not influenced by any other variables in the study.
Independent variables are also called:
- Explanatory variables (they explain an event or outcome)
- Predictor variables (they can be used to predict the value of a dependent variable)
- Right-hand-side variables (they appear on the right-hand side of a regression equation).
As a rule of thumb, questions related to thoughts, beliefs, and feelings work well in focus groups. Take your time formulating strong questions, paying special attention to phrasing. Be careful to avoid leading questions , which can bias your responses.
Overall, your focus group questions should be:
- Open-ended and flexible
- Impossible to answer with “yes” or “no” (questions that start with “why” or “how” are often best)
- Unambiguous, getting straight to the point while still stimulating discussion
- Unbiased and neutral
A structured interview is a data collection method that relies on asking questions in a set order to collect data on a topic. They are often quantitative in nature. Structured interviews are best used when:
- You already have a very clear understanding of your topic. Perhaps significant research has already been conducted, or you have done some prior research yourself, but you already possess a baseline for designing strong structured questions.
- You are constrained in terms of time or resources and need to analyze your data quickly and efficiently.
- Your research question depends on strong parity between participants, with environmental conditions held constant.
More flexible interview options include semi-structured interviews , unstructured interviews , and focus groups .
Social desirability bias is the tendency for interview participants to give responses that will be viewed favorably by the interviewer or other participants. It occurs in all types of interviews and surveys , but is most common in semi-structured interviews , unstructured interviews , and focus groups .
Social desirability bias can be mitigated by ensuring participants feel at ease and comfortable sharing their views. Make sure to pay attention to your own body language and any physical or verbal cues, such as nodding or widening your eyes.
This type of bias can also occur in observations if the participants know they’re being observed. They might alter their behavior accordingly.
The interviewer effect is a type of bias that emerges when a characteristic of an interviewer (race, age, gender identity, etc.) influences the responses given by the interviewee.
There is a risk of an interviewer effect in all types of interviews , but it can be mitigated by writing really high-quality interview questions.
A semi-structured interview is a blend of structured and unstructured types of interviews. Semi-structured interviews are best used when:
- You have prior interview experience. Spontaneous questions are deceptively challenging, and it’s easy to accidentally ask a leading question or make a participant uncomfortable.
- Your research question is exploratory in nature. Participant answers can guide future research questions and help you develop a more robust knowledge base for future research.
An unstructured interview is the most flexible type of interview, but it is not always the best fit for your research topic.
Unstructured interviews are best used when:
- You are an experienced interviewer and have a very strong background in your research topic, since it is challenging to ask spontaneous, colloquial questions.
- Your research question is exploratory in nature. While you may have developed hypotheses, you are open to discovering new or shifting viewpoints through the interview process.
- You are seeking descriptive data, and are ready to ask questions that will deepen and contextualize your initial thoughts and hypotheses.
- Your research depends on forming connections with your participants and making them feel comfortable revealing deeper emotions, lived experiences, or thoughts.
The four most common types of interviews are:
- Structured interviews : The questions are predetermined in both topic and order.
- Semi-structured interviews : A few questions are predetermined, but other questions aren’t planned.
- Unstructured interviews : None of the questions are predetermined.
- Focus group interviews : The questions are presented to a group instead of one individual.
Deductive reasoning is commonly used in scientific research, and it’s especially associated with quantitative research .
In research, you might have come across something called the hypothetico-deductive method . It’s the scientific method of testing hypotheses to check whether your predictions are substantiated by real-world data.
Deductive reasoning is a logical approach where you progress from general ideas to specific conclusions. It’s often contrasted with inductive reasoning , where you start with specific observations and form general conclusions.
Deductive reasoning is also called deductive logic.
There are many different types of inductive reasoning that people use formally or informally.
Here are a few common types:
- Inductive generalization : You use observations about a sample to come to a conclusion about the population it came from.
- Statistical generalization: You use specific numbers about samples to make statements about populations.
- Causal reasoning: You make cause-and-effect links between different things.
- Sign reasoning: You make a conclusion about a correlational relationship between different things.
- Analogical reasoning: You make a conclusion about something based on its similarities to something else.
Inductive reasoning is a bottom-up approach, while deductive reasoning is top-down.
Inductive reasoning takes you from the specific to the general, while in deductive reasoning, you make inferences by going from general premises to specific conclusions.
In inductive research , you start by making observations or gathering data. Then, you take a broad scan of your data and search for patterns. Finally, you make general conclusions that you might incorporate into theories.
Inductive reasoning is a method of drawing conclusions by going from the specific to the general. It’s usually contrasted with deductive reasoning, where you proceed from general information to specific conclusions.
Inductive reasoning is also called inductive logic or bottom-up reasoning.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Triangulation can help:
- Reduce research bias that comes from using a single method, theory, or investigator
- Enhance validity by approaching the same topic with different tools
- Establish credibility by giving you a complete picture of the research problem
But triangulation can also pose problems:
- It’s time-consuming and labor-intensive, often involving an interdisciplinary team.
- Your results may be inconsistent or even contradictory.
There are four main types of triangulation :
- Data triangulation : Using data from different times, spaces, and people
- Investigator triangulation : Involving multiple researchers in collecting or analyzing data
- Theory triangulation : Using varying theoretical perspectives in your research
- Methodological triangulation : Using different methodologies to approach the same topic
Many academic fields use peer review , largely to determine whether a manuscript is suitable for publication. Peer review enhances the credibility of the published manuscript.
However, peer review is also common in non-academic settings. The United Nations, the European Union, and many individual nations use peer review to evaluate grant applications. It is also widely used in medical and health-related fields as a teaching or quality-of-care measure.
Peer assessment is often used in the classroom as a pedagogical tool. Both receiving feedback and providing it are thought to enhance the learning process, helping students think critically and collaboratively.
Peer review can stop obviously problematic, falsified, or otherwise untrustworthy research from being published. It also represents an excellent opportunity to get feedback from renowned experts in your field. It acts as a first defense, helping you ensure your argument is clear and that there are no gaps, vague terms, or unanswered questions for readers who weren’t involved in the research process.
Peer-reviewed articles are considered a highly credible source due to this stringent process they go through before publication.
In general, the peer review process follows the following steps:
- First, the author submits the manuscript to the editor.
- Reject the manuscript and send it back to author, or
- Send it onward to the selected peer reviewer(s)
- Next, the peer review process occurs. The reviewer provides feedback, addressing any major or minor issues with the manuscript, and gives their advice regarding what edits should be made.
- Lastly, the edited manuscript is sent back to the author. They input the edits, and resubmit it to the editor for publication.
Exploratory research is often used when the issue you’re studying is new or when the data collection process is challenging for some reason.
You can use exploratory research if you have a general idea or a specific question that you want to study but there is no preexisting knowledge or paradigm with which to study it.
Exploratory research is a methodology approach that explores research questions that have not previously been studied in depth. It is often used when the issue you’re studying is new, or the data collection process is challenging in some way.
Explanatory research is used to investigate how or why a phenomenon occurs. Therefore, this type of research is often one of the first stages in the research process , serving as a jumping-off point for future research.
Exploratory research aims to explore the main aspects of an under-researched problem, while explanatory research aims to explain the causes and consequences of a well-defined problem.
Explanatory research is a research method used to investigate how or why something occurs when only a small amount of information is available pertaining to that topic. It can help you increase your understanding of a given topic.
Clean data are valid, accurate, complete, consistent, unique, and uniform. Dirty data include inconsistencies and errors.
Dirty data can come from any part of the research process, including poor research design , inappropriate measurement materials, or flawed data entry.
Data cleaning takes place between data collection and data analyses. But you can use some methods even before collecting data.
For clean data, you should start by designing measures that collect valid data. Data validation at the time of data entry or collection helps you minimize the amount of data cleaning you’ll need to do.
After data collection, you can use data standardization and data transformation to clean your data. You’ll also deal with any missing values, outliers, and duplicate values.
Every dataset requires different techniques to clean dirty data , but you need to address these issues in a systematic way. You focus on finding and resolving data points that don’t agree or fit with the rest of your dataset.
These data might be missing values, outliers, duplicate values, incorrectly formatted, or irrelevant. You’ll start with screening and diagnosing your data. Then, you’ll often standardize and accept or remove data to make your dataset consistent and valid.
Data cleaning is necessary for valid and appropriate analyses. Dirty data contain inconsistencies or errors , but cleaning your data helps you minimize or resolve these.
Without data cleaning, you could end up with a Type I or II error in your conclusion. These types of erroneous conclusions can be practically significant with important consequences, because they lead to misplaced investments or missed opportunities.
Data cleaning involves spotting and resolving potential data inconsistencies or errors to improve your data quality. An error is any value (e.g., recorded weight) that doesn’t reflect the true value (e.g., actual weight) of something that’s being measured.
In this process, you review, analyze, detect, modify, or remove “dirty” data to make your dataset “clean.” Data cleaning is also called data cleansing or data scrubbing.
Research misconduct means making up or falsifying data, manipulating data analyses, or misrepresenting results in research reports. It’s a form of academic fraud.
These actions are committed intentionally and can have serious consequences; research misconduct is not a simple mistake or a point of disagreement but a serious ethical failure.
Anonymity means you don’t know who the participants are, while confidentiality means you know who they are but remove identifying information from your research report. Both are important ethical considerations .
You can only guarantee anonymity by not collecting any personally identifying information—for example, names, phone numbers, email addresses, IP addresses, physical characteristics, photos, or videos.
You can keep data confidential by using aggregate information in your research report, so that you only refer to groups of participants rather than individuals.
Research ethics matter for scientific integrity, human rights and dignity, and collaboration between science and society. These principles make sure that participation in studies is voluntary, informed, and safe.
Ethical considerations in research are a set of principles that guide your research designs and practices. These principles include voluntary participation, informed consent, anonymity, confidentiality, potential for harm, and results communication.
Scientists and researchers must always adhere to a certain code of conduct when collecting data from others .
These considerations protect the rights of research participants, enhance research validity , and maintain scientific integrity.
In multistage sampling , you can use probability or non-probability sampling methods .
For a probability sample, you have to conduct probability sampling at every stage.
You can mix it up by using simple random sampling , systematic sampling , or stratified sampling to select units at different stages, depending on what is applicable and relevant to your study.
Multistage sampling can simplify data collection when you have large, geographically spread samples, and you can obtain a probability sample without a complete sampling frame.
But multistage sampling may not lead to a representative sample, and larger samples are needed for multistage samples to achieve the statistical properties of simple random samples .
These are four of the most common mixed methods designs :
- Convergent parallel: Quantitative and qualitative data are collected at the same time and analyzed separately. After both analyses are complete, compare your results to draw overall conclusions.
- Embedded: Quantitative and qualitative data are collected at the same time, but within a larger quantitative or qualitative design. One type of data is secondary to the other.
- Explanatory sequential: Quantitative data is collected and analyzed first, followed by qualitative data. You can use this design if you think your qualitative data will explain and contextualize your quantitative findings.
- Exploratory sequential: Qualitative data is collected and analyzed first, followed by quantitative data. You can use this design if you think the quantitative data will confirm or validate your qualitative findings.
Triangulation in research means using multiple datasets, methods, theories and/or investigators to address a research question. It’s a research strategy that can help you enhance the validity and credibility of your findings.
Triangulation is mainly used in qualitative research , but it’s also commonly applied in quantitative research . Mixed methods research always uses triangulation.
In multistage sampling , or multistage cluster sampling, you draw a sample from a population using smaller and smaller groups at each stage.
This method is often used to collect data from a large, geographically spread group of people in national surveys, for example. You take advantage of hierarchical groupings (e.g., from state to city to neighborhood) to create a sample that’s less expensive and time-consuming to collect data from.
No, the steepness or slope of the line isn’t related to the correlation coefficient value. The correlation coefficient only tells you how closely your data fit on a line, so two datasets with the same correlation coefficient can have very different slopes.
To find the slope of the line, you’ll need to perform a regression analysis .
Correlation coefficients always range between -1 and 1.
The sign of the coefficient tells you the direction of the relationship: a positive value means the variables change together in the same direction, while a negative value means they change together in opposite directions.
The absolute value of a number is equal to the number without its sign. The absolute value of a correlation coefficient tells you the magnitude of the correlation: the greater the absolute value, the stronger the correlation.
These are the assumptions your data must meet if you want to use Pearson’s r :
- Both variables are on an interval or ratio level of measurement
- Data from both variables follow normal distributions
- Your data have no outliers
- Your data is from a random or representative sample
- You expect a linear relationship between the two variables
Quantitative research designs can be divided into two main categories:
- Correlational and descriptive designs are used to investigate characteristics, averages, trends, and associations between variables.
- Experimental and quasi-experimental designs are used to test causal relationships .
Qualitative research designs tend to be more flexible. Common types of qualitative design include case study , ethnography , and grounded theory designs.
A well-planned research design helps ensure that your methods match your research aims, that you collect high-quality data, and that you use the right kind of analysis to answer your questions, utilizing credible sources . This allows you to draw valid , trustworthy conclusions.
The priorities of a research design can vary depending on the field, but you usually have to specify:
- Your research questions and/or hypotheses
- Your overall approach (e.g., qualitative or quantitative )
- The type of design you’re using (e.g., a survey , experiment , or case study )
- Your sampling methods or criteria for selecting subjects
- Your data collection methods (e.g., questionnaires , observations)
- Your data collection procedures (e.g., operationalization , timing and data management)
- Your data analysis methods (e.g., statistical tests or thematic analysis )
A research design is a strategy for answering your research question . It defines your overall approach and determines how you will collect and analyze data.
Questionnaires can be self-administered or researcher-administered.
Self-administered questionnaires can be delivered online or in paper-and-pen formats, in person or through mail. All questions are standardized so that all respondents receive the same questions with identical wording.
Researcher-administered questionnaires are interviews that take place by phone, in-person, or online between researchers and respondents. You can gain deeper insights by clarifying questions for respondents or asking follow-up questions.
You can organize the questions logically, with a clear progression from simple to complex, or randomly between respondents. A logical flow helps respondents process the questionnaire easier and quicker, but it may lead to bias. Randomization can minimize the bias from order effects.
Closed-ended, or restricted-choice, questions offer respondents a fixed set of choices to select from. These questions are easier to answer quickly.
Open-ended or long-form questions allow respondents to answer in their own words. Because there are no restrictions on their choices, respondents can answer in ways that researchers may not have otherwise considered.
A questionnaire is a data collection tool or instrument, while a survey is an overarching research method that involves collecting and analyzing data from people using questionnaires.
The third variable and directionality problems are two main reasons why correlation isn’t causation .
The third variable problem means that a confounding variable affects both variables to make them seem causally related when they are not.
The directionality problem is when two variables correlate and might actually have a causal relationship, but it’s impossible to conclude which variable causes changes in the other.
Correlation describes an association between variables : when one variable changes, so does the other. A correlation is a statistical indicator of the relationship between variables.
Causation means that changes in one variable brings about changes in the other (i.e., there is a cause-and-effect relationship between variables). The two variables are correlated with each other, and there’s also a causal link between them.
While causation and correlation can exist simultaneously, correlation does not imply causation. In other words, correlation is simply a relationship where A relates to B—but A doesn’t necessarily cause B to happen (or vice versa). Mistaking correlation for causation is a common error and can lead to false cause fallacy .
Controlled experiments establish causality, whereas correlational studies only show associations between variables.
- In an experimental design , you manipulate an independent variable and measure its effect on a dependent variable. Other variables are controlled so they can’t impact the results.
- In a correlational design , you measure variables without manipulating any of them. You can test whether your variables change together, but you can’t be sure that one variable caused a change in another.
In general, correlational research is high in external validity while experimental research is high in internal validity .
A correlation is usually tested for two variables at a time, but you can test correlations between three or more variables.
A correlation coefficient is a single number that describes the strength and direction of the relationship between your variables.
Different types of correlation coefficients might be appropriate for your data based on their levels of measurement and distributions . The Pearson product-moment correlation coefficient (Pearson’s r ) is commonly used to assess a linear relationship between two quantitative variables.
A correlational research design investigates relationships between two variables (or more) without the researcher controlling or manipulating any of them. It’s a non-experimental type of quantitative research .
A correlation reflects the strength and/or direction of the association between two or more variables.
- A positive correlation means that both variables change in the same direction.
- A negative correlation means that the variables change in opposite directions.
- A zero correlation means there’s no relationship between the variables.
Random error is almost always present in scientific studies, even in highly controlled settings. While you can’t eradicate it completely, you can reduce random error by taking repeated measurements, using a large sample, and controlling extraneous variables .
You can avoid systematic error through careful design of your sampling , data collection , and analysis procedures. For example, use triangulation to measure your variables using multiple methods; regularly calibrate instruments or procedures; use random sampling and random assignment ; and apply masking (blinding) where possible.
Systematic error is generally a bigger problem in research.
With random error, multiple measurements will tend to cluster around the true value. When you’re collecting data from a large sample , the errors in different directions will cancel each other out.
Systematic errors are much more problematic because they can skew your data away from the true value. This can lead you to false conclusions ( Type I and II errors ) about the relationship between the variables you’re studying.
Random and systematic error are two types of measurement error.
Random error is a chance difference between the observed and true values of something (e.g., a researcher misreading a weighing scale records an incorrect measurement).
Systematic error is a consistent or proportional difference between the observed and true values of something (e.g., a miscalibrated scale consistently records weights as higher than they actually are).
On graphs, the explanatory variable is conventionally placed on the x-axis, while the response variable is placed on the y-axis.
- If you have quantitative variables , use a scatterplot or a line graph.
- If your response variable is categorical, use a scatterplot or a line graph.
- If your explanatory variable is categorical, use a bar graph.
The term “ explanatory variable ” is sometimes preferred over “ independent variable ” because, in real world contexts, independent variables are often influenced by other variables. This means they aren’t totally independent.
Multiple independent variables may also be correlated with each other, so “explanatory variables” is a more appropriate term.
The difference between explanatory and response variables is simple:
- An explanatory variable is the expected cause, and it explains the results.
- A response variable is the expected effect, and it responds to other variables.
In a controlled experiment , all extraneous variables are held constant so that they can’t influence the results. Controlled experiments require:
- A control group that receives a standard treatment, a fake treatment, or no treatment.
- Random assignment of participants to ensure the groups are equivalent.
Depending on your study topic, there are various other methods of controlling variables .
There are 4 main types of extraneous variables :
- Demand characteristics : environmental cues that encourage participants to conform to researchers’ expectations.
- Experimenter effects : unintentional actions by researchers that influence study outcomes.
- Situational variables : environmental variables that alter participants’ behaviors.
- Participant variables : any characteristic or aspect of a participant’s background that could affect study results.
An extraneous variable is any variable that you’re not investigating that can potentially affect the dependent variable of your research study.
A confounding variable is a type of extraneous variable that not only affects the dependent variable, but is also related to the independent variable.
In a factorial design, multiple independent variables are tested.
If you test two variables, each level of one independent variable is combined with each level of the other independent variable to create different conditions.
Within-subjects designs have many potential threats to internal validity , but they are also very statistically powerful .
Advantages:
- Only requires small samples
- Statistically powerful
- Removes the effects of individual differences on the outcomes
Disadvantages:
- Internal validity threats reduce the likelihood of establishing a direct relationship between variables
- Time-related effects, such as growth, can influence the outcomes
- Carryover effects mean that the specific order of different treatments affect the outcomes
While a between-subjects design has fewer threats to internal validity , it also requires more participants for high statistical power than a within-subjects design .
- Prevents carryover effects of learning and fatigue.
- Shorter study duration.
- Needs larger samples for high power.
- Uses more resources to recruit participants, administer sessions, cover costs, etc.
- Individual differences may be an alternative explanation for results.
Yes. Between-subjects and within-subjects designs can be combined in a single study when you have two or more independent variables (a factorial design). In a mixed factorial design, one variable is altered between subjects and another is altered within subjects.
In a between-subjects design , every participant experiences only one condition, and researchers assess group differences between participants in various conditions.
In a within-subjects design , each participant experiences all conditions, and researchers test the same participants repeatedly for differences between conditions.
The word “between” means that you’re comparing different conditions between groups, while the word “within” means you’re comparing different conditions within the same group.
Random assignment is used in experiments with a between-groups or independent measures design. In this research design, there’s usually a control group and one or more experimental groups. Random assignment helps ensure that the groups are comparable.
In general, you should always use random assignment in this type of experimental design when it is ethically possible and makes sense for your study topic.
To implement random assignment , assign a unique number to every member of your study’s sample .
Then, you can use a random number generator or a lottery method to randomly assign each number to a control or experimental group. You can also do so manually, by flipping a coin or rolling a dice to randomly assign participants to groups.
Random selection, or random sampling , is a way of selecting members of a population for your study’s sample.
In contrast, random assignment is a way of sorting the sample into control and experimental groups.
Random sampling enhances the external validity or generalizability of your results, while random assignment improves the internal validity of your study.
In experimental research, random assignment is a way of placing participants from your sample into different groups using randomization. With this method, every member of the sample has a known or equal chance of being placed in a control group or an experimental group.
“Controlling for a variable” means measuring extraneous variables and accounting for them statistically to remove their effects on other variables.
Researchers often model control variable data along with independent and dependent variable data in regression analyses and ANCOVAs . That way, you can isolate the control variable’s effects from the relationship between the variables of interest.
Control variables help you establish a correlational or causal relationship between variables by enhancing internal validity .
If you don’t control relevant extraneous variables , they may influence the outcomes of your study, and you may not be able to demonstrate that your results are really an effect of your independent variable .
A control variable is any variable that’s held constant in a research study. It’s not a variable of interest in the study, but it’s controlled because it could influence the outcomes.
Including mediators and moderators in your research helps you go beyond studying a simple relationship between two variables for a fuller picture of the real world. They are important to consider when studying complex correlational or causal relationships.
Mediators are part of the causal pathway of an effect, and they tell you how or why an effect takes place. Moderators usually help you judge the external validity of your study by identifying the limitations of when the relationship between variables holds.
If something is a mediating variable :
- It’s caused by the independent variable .
- It influences the dependent variable
- When it’s taken into account, the statistical correlation between the independent and dependent variables is higher than when it isn’t considered.
A confounder is a third variable that affects variables of interest and makes them seem related when they are not. In contrast, a mediator is the mechanism of a relationship between two variables: it explains the process by which they are related.
A mediator variable explains the process through which two variables are related, while a moderator variable affects the strength and direction of that relationship.
There are three key steps in systematic sampling :
- Define and list your population , ensuring that it is not ordered in a cyclical or periodic order.
- Decide on your sample size and calculate your interval, k , by dividing your population by your target sample size.
- Choose every k th member of the population as your sample.
Systematic sampling is a probability sampling method where researchers select members of the population at a regular interval – for example, by selecting every 15th person on a list of the population. If the population is in a random order, this can imitate the benefits of simple random sampling .
Yes, you can create a stratified sample using multiple characteristics, but you must ensure that every participant in your study belongs to one and only one subgroup. In this case, you multiply the numbers of subgroups for each characteristic to get the total number of groups.
For example, if you were stratifying by location with three subgroups (urban, rural, or suburban) and marital status with five subgroups (single, divorced, widowed, married, or partnered), you would have 3 x 5 = 15 subgroups.
You should use stratified sampling when your sample can be divided into mutually exclusive and exhaustive subgroups that you believe will take on different mean values for the variable that you’re studying.
Using stratified sampling will allow you to obtain more precise (with lower variance ) statistical estimates of whatever you are trying to measure.
For example, say you want to investigate how income differs based on educational attainment, but you know that this relationship can vary based on race. Using stratified sampling, you can ensure you obtain a large enough sample from each racial group, allowing you to draw more precise conclusions.
In stratified sampling , researchers divide subjects into subgroups called strata based on characteristics that they share (e.g., race, gender, educational attainment).
Once divided, each subgroup is randomly sampled using another probability sampling method.
Cluster sampling is more time- and cost-efficient than other probability sampling methods , particularly when it comes to large samples spread across a wide geographical area.
However, it provides less statistical certainty than other methods, such as simple random sampling , because it is difficult to ensure that your clusters properly represent the population as a whole.
There are three types of cluster sampling : single-stage, double-stage and multi-stage clustering. In all three types, you first divide the population into clusters, then randomly select clusters for use in your sample.
- In single-stage sampling , you collect data from every unit within the selected clusters.
- In double-stage sampling , you select a random sample of units from within the clusters.
- In multi-stage sampling , you repeat the procedure of randomly sampling elements from within the clusters until you have reached a manageable sample.
Cluster sampling is a probability sampling method in which you divide a population into clusters, such as districts or schools, and then randomly select some of these clusters as your sample.
The clusters should ideally each be mini-representations of the population as a whole.
If properly implemented, simple random sampling is usually the best sampling method for ensuring both internal and external validity . However, it can sometimes be impractical and expensive to implement, depending on the size of the population to be studied,
If you have a list of every member of the population and the ability to reach whichever members are selected, you can use simple random sampling.
The American Community Survey is an example of simple random sampling . In order to collect detailed data on the population of the US, the Census Bureau officials randomly select 3.5 million households per year and use a variety of methods to convince them to fill out the survey.
Simple random sampling is a type of probability sampling in which the researcher randomly selects a subset of participants from a population . Each member of the population has an equal chance of being selected. Data is then collected from as large a percentage as possible of this random subset.
Quasi-experimental design is most useful in situations where it would be unethical or impractical to run a true experiment .
Quasi-experiments have lower internal validity than true experiments, but they often have higher external validity as they can use real-world interventions instead of artificial laboratory settings.
A quasi-experiment is a type of research design that attempts to establish a cause-and-effect relationship. The main difference with a true experiment is that the groups are not randomly assigned.
Blinding is important to reduce research bias (e.g., observer bias , demand characteristics ) and ensure a study’s internal validity .
If participants know whether they are in a control or treatment group , they may adjust their behavior in ways that affect the outcome that researchers are trying to measure. If the people administering the treatment are aware of group assignment, they may treat participants differently and thus directly or indirectly influence the final results.
- In a single-blind study , only the participants are blinded.
- In a double-blind study , both participants and experimenters are blinded.
- In a triple-blind study , the assignment is hidden not only from participants and experimenters, but also from the researchers analyzing the data.
Blinding means hiding who is assigned to the treatment group and who is assigned to the control group in an experiment .
A true experiment (a.k.a. a controlled experiment) always includes at least one control group that doesn’t receive the experimental treatment.
However, some experiments use a within-subjects design to test treatments without a control group. In these designs, you usually compare one group’s outcomes before and after a treatment (instead of comparing outcomes between different groups).
For strong internal validity , it’s usually best to include a control group if possible. Without a control group, it’s harder to be certain that the outcome was caused by the experimental treatment and not by other variables.
An experimental group, also known as a treatment group, receives the treatment whose effect researchers wish to study, whereas a control group does not. They should be identical in all other ways.
Individual Likert-type questions are generally considered ordinal data , because the items have clear rank order, but don’t have an even distribution.
Overall Likert scale scores are sometimes treated as interval data. These scores are considered to have directionality and even spacing between them.
The type of data determines what statistical tests you should use to analyze your data.
A Likert scale is a rating scale that quantitatively assesses opinions, attitudes, or behaviors. It is made up of 4 or more questions that measure a single attitude or trait when response scores are combined.
To use a Likert scale in a survey , you present participants with Likert-type questions or statements, and a continuum of items, usually with 5 or 7 possible responses, to capture their degree of agreement.
There are various approaches to qualitative data analysis , but they all share five steps in common:
- Prepare and organize your data.
- Review and explore your data.
- Develop a data coding system.
- Assign codes to the data.
- Identify recurring themes.
The specifics of each step depend on the focus of the analysis. Some common approaches include textual analysis , thematic analysis , and discourse analysis .
There are five common approaches to qualitative research :
- Grounded theory involves collecting data in order to develop new theories.
- Ethnography involves immersing yourself in a group or organization to understand its culture.
- Narrative research involves interpreting stories to understand how people make sense of their experiences and perceptions.
- Phenomenological research involves investigating phenomena through people’s lived experiences.
- Action research links theory and practice in several cycles to drive innovative changes.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Operationalization means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioral avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalize the variables that you want to measure.
When conducting research, collecting original data has significant advantages:
- You can tailor data collection to your specific research aims (e.g. understanding the needs of your consumers or user testing your website)
- You can control and standardize the process for high reliability and validity (e.g. choosing appropriate measurements and sampling methods )
However, there are also some drawbacks: data collection can be time-consuming, labor-intensive and expensive. In some cases, it’s more efficient to use secondary data that has already been collected by someone else, but the data might be less reliable.
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organizations.
There are several methods you can use to decrease the impact of confounding variables on your research: restriction, matching, statistical control and randomization.
In restriction , you restrict your sample by only including certain subjects that have the same values of potential confounding variables.
In matching , you match each of the subjects in your treatment group with a counterpart in the comparison group. The matched subjects have the same values on any potential confounding variables, and only differ in the independent variable .
In statistical control , you include potential confounders as variables in your regression .
In randomization , you randomly assign the treatment (or independent variable) in your study to a sufficiently large number of subjects, which allows you to control for all potential confounding variables.
A confounding variable is closely related to both the independent and dependent variables in a study. An independent variable represents the supposed cause , while the dependent variable is the supposed effect . A confounding variable is a third variable that influences both the independent and dependent variables.
Failing to account for confounding variables can cause you to wrongly estimate the relationship between your independent and dependent variables.
To ensure the internal validity of your research, you must consider the impact of confounding variables. If you fail to account for them, you might over- or underestimate the causal relationship between your independent and dependent variables , or even find a causal relationship where none exists.
Yes, but including more than one of either type requires multiple research questions .
For example, if you are interested in the effect of a diet on health, you can use multiple measures of health: blood sugar, blood pressure, weight, pulse, and many more. Each of these is its own dependent variable with its own research question.
You could also choose to look at the effect of exercise levels as well as diet, or even the additional effect of the two combined. Each of these is a separate independent variable .
To ensure the internal validity of an experiment , you should only change one independent variable at a time.
No. The value of a dependent variable depends on an independent variable, so a variable cannot be both independent and dependent at the same time. It must be either the cause or the effect, not both!
You want to find out how blood sugar levels are affected by drinking diet soda and regular soda, so you conduct an experiment .
- The type of soda – diet or regular – is the independent variable .
- The level of blood sugar that you measure is the dependent variable – it changes depending on the type of soda.
Determining cause and effect is one of the most important parts of scientific research. It’s essential to know which is the cause – the independent variable – and which is the effect – the dependent variable.
In non-probability sampling , the sample is selected based on non-random criteria, and not every member of the population has a chance of being included.
Common non-probability sampling methods include convenience sampling , voluntary response sampling, purposive sampling , snowball sampling, and quota sampling .
Probability sampling means that every member of the target population has a known chance of being included in the sample.
Probability sampling methods include simple random sampling , systematic sampling , stratified sampling , and cluster sampling .
Using careful research design and sampling procedures can help you avoid sampling bias . Oversampling can be used to correct undercoverage bias .
Some common types of sampling bias include self-selection bias , nonresponse bias , undercoverage bias , survivorship bias , pre-screening or advertising bias, and healthy user bias.
Sampling bias is a threat to external validity – it limits the generalizability of your findings to a broader group of people.
A sampling error is the difference between a population parameter and a sample statistic .
A statistic refers to measures about the sample , while a parameter refers to measures about the population .
Populations are used when a research question requires data from every member of the population. This is usually only feasible when the population is small and easily accessible.
Samples are used to make inferences about populations . Samples are easier to collect data from because they are practical, cost-effective, convenient, and manageable.
There are seven threats to external validity : selection bias , history, experimenter effect, Hawthorne effect , testing effect, aptitude-treatment and situation effect.
The two types of external validity are population validity (whether you can generalize to other groups of people) and ecological validity (whether you can generalize to other situations and settings).
The external validity of a study is the extent to which you can generalize your findings to different groups of people, situations, and measures.
Cross-sectional studies cannot establish a cause-and-effect relationship or analyze behavior over a period of time. To investigate cause and effect, you need to do a longitudinal study or an experimental study .
Cross-sectional studies are less expensive and time-consuming than many other types of study. They can provide useful insights into a population’s characteristics and identify correlations for further research.
Sometimes only cross-sectional data is available for analysis; other times your research question may only require a cross-sectional study to answer it.
Longitudinal studies can last anywhere from weeks to decades, although they tend to be at least a year long.
The 1970 British Cohort Study , which has collected data on the lives of 17,000 Brits since their births in 1970, is one well-known example of a longitudinal study .
Longitudinal studies are better to establish the correct sequence of events, identify changes over time, and provide insight into cause-and-effect relationships, but they also tend to be more expensive and time-consuming than other types of studies.
Longitudinal studies and cross-sectional studies are two different types of research design . In a cross-sectional study you collect data from a population at a specific point in time; in a longitudinal study you repeatedly collect data from the same sample over an extended period of time.
| Longitudinal study | Cross-sectional study |
|---|---|
| observations | Observations at a in time |
| Observes the multiple times | Observes (a “cross-section”) in the population |
| Follows in participants over time | Provides of society at a given point |
There are eight threats to internal validity : history, maturation, instrumentation, testing, selection bias , regression to the mean, social interaction and attrition .
Internal validity is the extent to which you can be confident that a cause-and-effect relationship established in a study cannot be explained by other factors.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
The research methods you use depend on the type of data you need to answer your research question .
- If you want to measure something or test a hypothesis , use quantitative methods . If you want to explore ideas, thoughts and meanings, use qualitative methods .
- If you want to analyze a large amount of readily-available data, use secondary data. If you want data specific to your purposes with control over how it is generated, collect primary data.
- If you want to establish cause-and-effect relationships between variables , use experimental methods. If you want to understand the characteristics of a research subject, use descriptive methods.
A confounding variable , also called a confounder or confounding factor, is a third variable in a study examining a potential cause-and-effect relationship.
A confounding variable is related to both the supposed cause and the supposed effect of the study. It can be difficult to separate the true effect of the independent variable from the effect of the confounding variable.
In your research design , it’s important to identify potential confounding variables and plan how you will reduce their impact.
Discrete and continuous variables are two types of quantitative variables :
- Discrete variables represent counts (e.g. the number of objects in a collection).
- Continuous variables represent measurable amounts (e.g. water volume or weight).
Quantitative variables are any variables where the data represent amounts (e.g. height, weight, or age).
Categorical variables are any variables where the data represent groups. This includes rankings (e.g. finishing places in a race), classifications (e.g. brands of cereal), and binary outcomes (e.g. coin flips).
You need to know what type of variables you are working with to choose the right statistical test for your data and interpret your results .
You can think of independent and dependent variables in terms of cause and effect: an independent variable is the variable you think is the cause , while a dependent variable is the effect .
In an experiment, you manipulate the independent variable and measure the outcome in the dependent variable. For example, in an experiment about the effect of nutrients on crop growth:
- The independent variable is the amount of nutrients added to the crop field.
- The dependent variable is the biomass of the crops at harvest time.
Defining your variables, and deciding how you will manipulate and measure them, is an important part of experimental design .
Experimental design means planning a set of procedures to investigate a relationship between variables . To design a controlled experiment, you need:
- A testable hypothesis
- At least one independent variable that can be precisely manipulated
- At least one dependent variable that can be precisely measured
When designing the experiment, you decide:
- How you will manipulate the variable(s)
- How you will control for any potential confounding variables
- How many subjects or samples will be included in the study
- How subjects will be assigned to treatment levels
Experimental design is essential to the internal and external validity of your experiment.
I nternal validity is the degree of confidence that the causal relationship you are testing is not influenced by other factors or variables .
External validity is the extent to which your results can be generalized to other contexts.
The validity of your experiment depends on your experimental design .
Reliability and validity are both about how well a method measures something:
- Reliability refers to the consistency of a measure (whether the results can be reproduced under the same conditions).
- Validity refers to the accuracy of a measure (whether the results really do represent what they are supposed to measure).
If you are doing experimental research, you also have to consider the internal and external validity of your experiment.
A sample is a subset of individuals from a larger population . Sampling means selecting the group that you will actually collect data from in your research. For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
In statistics, sampling allows you to test a hypothesis about the characteristics of a population.
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to systematically measure variables and test hypotheses . Qualitative methods allow you to explore concepts and experiences in more detail.
Methodology refers to the overarching strategy and rationale of your research project . It involves studying the methods used in your field and the theories or principles behind them, in order to develop an approach that matches your objectives.
Methods are the specific tools and procedures you use to collect and analyze data (for example, experiments, surveys , and statistical tests ).
In shorter scientific papers, where the aim is to report the findings of a specific study, you might simply describe what you did in a methods section .
In a longer or more complex research project, such as a thesis or dissertation , you will probably include a methodology section , where you explain your approach to answering the research questions and cite relevant sources to support your choice of methods.
Ask our team
Want to contact us directly? No problem. We are always here for you.
- Email [email protected]
- Start live chat
- Call +1 (510) 822-8066
- WhatsApp +31 20 261 6040

Our team helps students graduate by offering:
- A world-class citation generator
- Plagiarism Checker software powered by Turnitin
- Innovative Citation Checker software
- Professional proofreading services
- Over 300 helpful articles about academic writing, citing sources, plagiarism, and more
Scribbr specializes in editing study-related documents . We proofread:
- PhD dissertations
- Research proposals
- Personal statements
- Admission essays
- Motivation letters
- Reflection papers
- Journal articles
- Capstone projects
Scribbr’s Plagiarism Checker is powered by elements of Turnitin’s Similarity Checker , namely the plagiarism detection software and the Internet Archive and Premium Scholarly Publications content databases .
The add-on AI detector is powered by Scribbr’s proprietary software.
The Scribbr Citation Generator is developed using the open-source Citation Style Language (CSL) project and Frank Bennett’s citeproc-js . It’s the same technology used by dozens of other popular citation tools, including Mendeley and Zotero.
You can find all the citation styles and locales used in the Scribbr Citation Generator in our publicly accessible repository on Github .

Capturing Change in Science, Technology, and Innovation: Improving Indicators to Inform Policy (2014)
Chapter: 2 concepts and uses of indicators.
2 Concepts and Uses of Indicators
The purpose of this chapter is to introduce the concept of “indicators” as distinct from raw data and basic science and engineering statistics. It is also useful for the reader to understand how the production of science, technology, and innovation (STI) indicators is informed by the precepts of conceptual or logic models that attempt to reflect the actors, actions, dynamics, systems, and resulting outcomes that analysts try to capture. Entailed in this process are assumptions, reasoned inferences, and a “black box” (see Rosenberg, 1982) where tangible and intangible inputs become measurable outputs.
One difficulty encountered in constructing the STI indicators users want is that users are not monolithic. The specific types of indicators users need depend on the types of decisions they must make and the networks to which they belong. User diversity was therefore an important consideration as the panel deliberated on which indicators the National Center for Science and Engineering Statistics (NCSES) should produce in the future. Also considered was the expected diversity of the future user base—for instance, the potential for more business users and more users who must make decisions in regional contexts within the United States and abroad.
At the same time, however, all users want reliable values and to varying degrees wish to have the “black box” mechanisms exposed and detailed to the extent possible. As discussed in Chapter 1 , users of STI indicators share the need for high-quality, accessible, and timely observations on the rapidly changing global STI system. In addition, they expect those measures to be based on fundamentals and not merely on ad hoc relationships.
After defining the term “indicators” for this volume, the main task of this chapter is to demonstrate the utility of STI indicators, specifying those that address specific policy issues. In the process, the chapter establishes the characteristics of and user priorities for these indicators, many of which are already satisfied by NCSES’s publications and data tables (as discussed in Chapter 3 ).
DESIRABLE ATTRIBUTES OF INDICATORS
Generally, indicators point toward or foreshadow trends, turning point patterns, expectations, and intentions. They are often things one should know about issues of interest to a variety of users. Indicators have analytical qualities such that they typically go beyond raw data. As a result, they are usually rough proxies for activities that are difficult to observe or measure directly. They are like baseball statistics: a single statistic is unlikely to tell the whole story; instead, users often rely on a collection or suite of indicators. Furthermore, indicators should not be used in isolation; they require contextual information to be useful. Indicators can be composite indices of other statistics, designed to smooth out volatility in contributing factors. Indicators also provide input for the construction of econometric models used to evaluate the key determinants in systems and guide policy development.
Most familiar indicators are related to the weather or the economy. For example, The Conference Board publishes leading, coincident, and lagging economic indicators. The index of leading economic indicators comprises 10 individual measures, each of which is a leading indicator. These leading indicators are designed to signal coming peaks and troughs in the economic business cycle. Leading indicators inform prospective analyses, while coincident and lagging indicators facilitate contemporaneous or retrospective analyses.
This report focuses specifically on statistical indicators of STI activities—their composition, uses, and limitations—and hence the statistical measurement of activities that fall within the mandate of NCSES. To discuss measurement, the report defines a statistical indicator as a statistic, or combination of statistics, providing information on some aspect of the state or trends of STI activities. International comparability of these indicators is an important quality because it provides a benchmark against which to judge the performance of one system relative to others. STI indicators often substitute for direct measures of knowledge creation, invention, innova-
tion, technological diffusion, and science and engineering talent, which would be difficult if not impossible to obtain. For example, economic growth in a given nation is linked to the ingenuity of residents in science and engineering sectors. Since it is difficult to measure ingenuity directly, proximate measures that are more readily observed are used, such as numbers of master’s or Ph.D. degrees produced in a given nation within a given time period. Following trends in the number of degrees also enables users of indicators to develop projections of future economic growth. Notably, these indicators do not precisely measure ingenuity, but they are arguably reasonable proxies. Techniques for obtaining data that directly measure innovation activities are improving, however, 1 and these data are already being used to complement indicators derived with traditional methods.
Some indicators—those derived from modeling—can answer certain policy questions. Indicators also can reveal potential issues that require exploring, for example, the impact and cost-effectiveness of research and development (R&D) tax credits in stimulating incremental business R&D. Moreover, indicators can help refine and perhaps usefully narrow the policy question being asked. For example, is it innovation by large businesses or small, young firms that yields faster and more lucrative breakthroughs?
A comprehensive review of the use of STI indicators for policy decisions is provided by Gault (2010), who outlines four ways indicators are used for policy purposes: monitoring, benchmarking, evaluating, and forecasting or “foresighting”: 2
- monitoring—the international innovation system, linkages within and between national innovation systems, regional innovation systems and industrial clusters, the implementation of national science and technology (S&T) projects, the selected quantitative indicators in the S&T development goals;
- benchmarking—international and interprovincial (or interstate) benchmarking;
- evaluating—the performance of public investment in S&T, the performance of government research institutes and national laboratories, national S&T programs, specialization of S&T fields, advantages versus disadvantages, emerging industries (e.g., information technology, biotechnology, energy, health, knowledge-based services); and
- forecasting—the latest data not available in gathered statistics.
These categories are widely accepted as functional characteristics of STI indicators. For instance, at the panel’s July 2011 workshop, Changlin Gao reported that they are being used by China to target its STI indicators program.
At the same workshop, several other presenters suggested attributes that NCSES should keep in mind as it develops new STI indicators and improves existing indicators. One such attribute is low sensitivity to manipulation. During the workshop, Hugo Hollanders of UNU-MERIT 3 stated that composite indices have both political and media appeal, 4 although caution is essential in interpreting such indices, which may be readily understood but may not be adequate for conveying complex information. Other desirable characteristics of indicators mentioned by workshop participants included being scientifically derived and evidence based, comparable across regions, powerful for communication, affordable, accessible, scalable, sustainable, and policy and analytically relevant. STI indicators also should be policy neutral, even though the particular indicators selected may reflect the preferences of the stakeholders who request them.
IN SEARCH OF A FRAMEWORK
During its deliberations, the panel encountered several challenges in seeking a single framework or model for the STI system.
First, all the known elements of the STI system are not necessarily measurable; some are “unknown knowns.” Because poor measurement often leads to poor decision making, recommending the development of new but perhaps mismeasured indicators could leave users worse off than they are now.
Second, although linkages among the elements in a representation of the STI system are important to measure, such linkages often are difficult to identify quantitatively. In these instances, case studies or qualitative representations may be preferable to indicators. Moreover, spillover effects—for example, when two or more elements in the system contribute to synergistic or configural outcomes—are difficult to disentangle, and developing indicators that measure such effects is therefore a difficult task. Thus, linkages and spillovers often are “unknown unknowns”; that is, developing reliable indicators of these important components of the STI
____________________
1 See Eurostat’s Community Innovation Statistics in European Commission (2010) and NCSES’s Business Research and Development and Innovation Survey statistics in U.S. Department of Commerce (2011).
2 Wehrmeyer and colleagues (2002) give extensive definitions of foresighting as the term is used differently in business consulting and in government decision-making practices. Citing Coates (1985, p. 30), Wehrmeyer and colleagues give the generic definition of foresighting as follows: “Foresighting is a process by which one comes to a fuller understanding of the forces shaping the long-term future which should be taken into account in policy formulation, planning and decision-making…. Foresight involves qualitative and quantitative means for monitoring clues and indicators of evolving trends and developments and is best and most useful when directly linked to the analysis of policy implications.”
3 UNU-MERIT—the United Nations University Maastricht Economic and Social Research Institute on Innovation and Technology—is a research and training center of the United Nations University and works in close collaboration with the University of Maastricht.
4 To clarify, the panel is not advocating that NCSES develop one composite indicator, or as it is often termed, a “headline indicator.” A suite of key STI indicators should be more informative for users.
system is difficult. For example, developing valid measures of intangible assets is problematic precisely because they are typically intermediate inputs with realized values that depend on the values of other outputs over some time horizon.
Third, models of the STI system or its components are plentiful and typically are shaped by the user’s goal (see, e.g., Cornell University, INSEAD, World Intellectual Property Organization, 2013, p. 6; Crépon et al., 1998; Department of Business Innovation and Skills, 2011, p. 30; European Union, 2013, p. 4; Griliches, 1998, pp. 17-45; Hall and Jaffe, 2012; Hall et al., 2010; National Science Board, 2012c, p. 3; OECD, 2011; Sampat and Lichtenberg, 2011; Shanks and Zheng, 2006, pp. 105 and 288; Tassey, 2011). For example, some models list elements that have been shown to matter, either alone or in combination with other elements, to generate new ideas, products, processes, and other outcomes of the STI system, while other models are functional, in that the stocks (boxes) and flows (arrows connecting the boxes) represent estimable elements. Many of these models identify the same key elements that should be measured (or at least assessed), while offering added dimensionality depending on the model’s utility.
Economists, policy analysts, information scientists, material scientists, physicists, statisticians, and geographers (all represented on the panel) have different predilections for how to develop a representative model of the STI system. The identification of one common model by the panel was unlikely and could have appeared to be ad hoc or arbitrary. Therefore, instead of choosing a single model for the STI system, the panel used aspects of several models to inform its decisions about which elements of the system are most important to assess. Box 2-1 shows seven of the “models” that informed the panel’s guiding framework of key STI indicators that NCSES should produce. Since its charge was to focus on identifying policy-relevant, internationally comparable STI indicators, the panel also decided to use a policy-driven approach. This approach was informed by the published work of leading academicians and practitioners who map the STI system, as well as experiences in the international S&T policy arena. The resulting policy-driven framework, depicted in Figure 2-1 , identifies key activities that should be measured, as well as the links among these activities and the actors and outcomes in the STI system.
A POLICY-DRIVEN FRAMEWORK
The panel’s policy-driven framework provides a useful rubric for identifying the key policy issues and the indicators that can support analysis of these issues. These issues can range from highly aggregate (e.g., What is the contribution of STI to growth?) to highly granular (e.g., What is the supply of individuals with science, technology, engineering, and mathematics [STEM] skills by gender and ethnicity?). The issues tend to change over time (e.g., geographic interest has shifted from Japan to China, while sectoral interest has shifted from space to nanotechnologies). In some cases, the indicators needed to examine these issues are quite advanced, in other cases they are being developed, and in still other cases they are still in an embryonic state and require that NCSES partner with other organizations in their development. In nearly all cases, indicators offer only partial insight into the issue; gaining insight into the key determinants often requires empirical analysis involving econometric or growth accounting techniques or qualitative analysis that makes use of stylized facts or case studies. In any event, high-quality, policy-relevant data are needed to construct the indicators, support the econometric analysis, and create the stylized facts.
Policy makers, policy analysts, and the greater user community have an almost inexhaustible supply of questions they would like to have indicators to inform. Statistical agencies therefore are challenged as they seek to address user demands within the practical limits of available resources and expertise. With this tension in mind, the panel sought to populate its framework with a set of policy questions it believes are enduring and can serve as part of a strategic plan going forward.
As shown in Figure 2-1 , the key question on which almost all users want bedrock statistics is: What are the social returns to public and private expenditures on STI activities? The follow-on question is: Given expenditures on STI activities, what is the impact on economic growth, competitiveness, 5 and jobs? These questions are nuanced in several ways. Users want to know the drivers of innovation that could be encouraged through funding mechanisms and creative organizational structures. For example, indicators are sought not only for static measures of stocks of human capital, but also for trends as to which countries will be generating the most scientific research that can be commercialized or which countries are likely to attract the most R&D investments in the near future. Users have questions about advances in science on the horizon or vulnerabilities in the innovation ecosystem that could impede the commercialization of new ideas. They want quantitative measures to inform these questions, but they also need stories or case studies to provide a full understanding of the issues. Users are interested in the most fertile organizational structures or networks that foster creativity and the transfer of technology from bench to market. They also are interested in the nature of cooperative relationships that foster collaboration while protecting intellectual property rights and downstream profits and mitigating risks. Distributional questions are
5 The term “competitiveness” as used here denotes relative standing. Users of STI indicators often want to know the U.S. position relative to other nations on factors that are critical to U.S. preeminence in STI outcomes. Users are also interested in the standing of certain demographic groups and economic regions vis-à-vis other groups and geographic regions, respectively. The term “competitiveness” here does not relate to low cost or high profitability (as it often does in economics), and it does not necessarily have a strategic basis (as it does in the business literature).
BOX 2-1 Conceptual and Functional Models of the Science, Technology, and Innovation System (Synthesized by the Panel to Create Figure 2-1 )
Innovation Systems : The National Science Board has used a systems model to illustrate what its data and statistics attempt to measure. The purpose of this diagram (see Figure Box 2-1A ) is to show key elements in the global innovation system and the relationships between elements in the system. As important as it is to measure variables in the boxes or to develop scenarios that explain those elements, it is as important to measure or explain the linkages (arrows) between the boxes. This diagram has several “black boxes” or “assumptions” that require further explanation, and government expenditures on research and development (R&D) at universities and firms, and public sector R&D are not explicitly shown in this diagram.

FIGURE BOX 2-1A SOURCE: National Science Board (2012b).
Knowledge Capital : With a focus on measuring innovation and knowledge assets, Cornell University, INSEAD, and the World Intellectual Property Organization collaborated on a representation of the innovation system (see Figure Box 2-1B ). The European Commission framework has similar elements, with human and financial capital inputs, linkages and employment outputs specifically identified (see Figure Box 2-1C ). Together these frameworks capture many important dimensions of the STI system.

FIGURE BOX 2-1B SOURCE: Cornell University, INSEAD, and World Intellectual Property Organization (2013).

FIGURE BOX 2-1C SOURCE: European Union (2013).
Return on Expenditure : Growth accounting models are also used to describe the STI indicators system. STI indicators are often used to relate knowledge inputs to outputs, outcomes, or impacts. At a very basic level, knowledge inputs include years of schooling, level of degree, and the amount of training an employee receives on the job. Outputs are specific products, processes, or services. Outcomes and impacts are the near-term and long-term effects and ramifications to the economy or society in which the technological ecosystem operates. Productivity and returns on expenditures are often used to measure economic outcomes of STI activities. Other social outcomes, such as improvements in health outcomes associated with cleaner water or more effective medical treatments, are important to assess. For example, scientific advancement in detecting and removal of pathogenic microorganisms leads to technological mechanisms that in turn lead to cleaner water, thereby increasing productivity (through a healthier workforce) and hence increasing inputs in the production of goods and services, as well as increased welfare of citizens. Indicators are relied on for both post-activity evaluations and analysis prior to an activity, although there are major limitations in using STI indicators for predictive exercises. [See Abramovitz (1956); Carson et al. (1994); Fraumeni and Okubo (2005); Jorgenson and Griliches (1967); Solow (1957).] Other models focus on returns to R&D, where the framework is similar to the traditional production function/total factor productivity model. It is important to note that the second diagram calls out obsolescence of knowledge, making it important to measure not only the depreciation of capital stock but also the depreciation of knowledge and human capital. [See Crépon et al. (1998), see Figure Box 2-1D below; David (2010); Furman et al. (2002); Griliches (1958, 1998); Hall-Jaffe (2012); OECD (2009); Jorgenson and Gollop (1992); Mairesse and Mohnen (2010); Nelson (1993); Rogoff (2012); Shanks and Zheng (2006), see Figure Box 2-1E below; Solow (1994); and Soete (2012).]

FIGURE BOX 2-1D SOURCE: Crépon et al. (1998).

FIGURE BOX 2-1E SOURCE: Shanks and Zheng (2006).
Specific Outcomes : There are models that look at specific outcomes of scientific and innovation activities, such as Acemoglu et al. (2012), David (1990), David et al. (2011), Mowery (2010), Popp (2010), Rogoff (2011), and Sampat (2011). Sampat’s logic model of publicly funding R&D shows the pathways to new medical products and eventually health outcomes resulting from initial R&D expenditures. This model (see Figure Box 2-1F ) shows the importance of measuring nodes and connections between nodes, which show the influence on health outcomes of various elements in the system.

FIGURE BOX 2-1F SOURCE: Sampat (2011).
Linkages : There are frameworks that identify specific relationships between actors in the STI system (see Figure Box 2-1G ). Tassey (2011) highlights the coexistence of government and private funding for technological development. The blue shows contributions from government agencies while the red shows funding from private firms and organizations. This is a relational model but not necessarily predictive.

FIGURE BOX 2-1G SOURCE: Tassey (2011).

FIGURE 2-1 A policy-driven framework for STI indicators. NOTE: R&D = research and development; S&T = science and technology; STI = science, technology, and innovation. SOURCE: Panel’s own work.
important in many areas, including geospatial hot spots for entrepreneurial activities; potential avenues for broadening the participation of women, minorities, and people with disabilities in STEM fields; contributions to S&T breakthroughs from the social and behavioral sciences; the uptake of ideas for innovation from consumers; and the inclusivity of growth for various rungs of society. All of these top-level issues—drivers, trends, advances, vulnerabilities, relationships, and distributions—have underlying metrics that users want. 6
At the panel’s June 2012 workshop, representatives of the OECD-National Experts on Science and Technology Indicators (NESTI) Working Group implicitly described the STI system. 7 A system consists of actors, engaged in activities, with linkages to other actors and activities, giving rise to short-term outcomes and long-term impacts. Actors are people who are observed individually or as collectives, such as teams or organizations. In a high-level analysis, the actors are governments, institutions of education and research, businesses, and others such as private nonprofit organizations. The activities in which the actors engage include research, invention, development, design and other engineering tasks, innovation, diffusion of technologies and practices, education and training, and capital investment. Examples of linkages are grants and contracts, collaboration, partnerships, codevelopment, copublication, and social networks.
Mapping the system, understanding it, and explaining it to policy makers—all themes that emerged in the workshop—require data linkage and microdata analysis. The result of addressing these themes would be new and better indicators on linkages in addition to existing indicators on activities such as R&D, trade in R&D services, and the production and mobility of highly qualified people. Workshop participants also stressed that a system exists in space and time, and looking in more detail at regions is important, as is providing policy-relevant indicators to policy makers in a more timely manner.
USER PRIORITIES 8
This section summarizes the priorities of two key groups of users of NCSES products: users of microdata and users of STI indicators.
6 A list of policy issues and related questions appears in Appendix B and is referenced in Chapters 4-6.
7 See Appendix D for the workshop agenda and the list of attendees. NCSES staff were represented at the workshop.
8 The panel was unable to obtain a full list of users from NCSES. Identifying its full customer base is difficult for NCSES because the vast majority obtain information anonymously via the World Wide Web. Therefore, the panel derived information about key users from NCSES, panel members who are experienced data users, and some of the users who were interviewed for this study.
Users of Microdata
Although data development and access were not the focus of this study, it is important to mention here the primary request of a significant number of data users. Academic researchers, as well as data analysts at government agencies and private organizations, uniformly requested greater access to microdata (in this case, disaggregated data from NCSES surveys), not just aggregates or other statistics derived from those data. This type of user relies on NCSES for expertly curated datasets. 9
Over the years, for example, NCSES has collected longitudinal data, 10 administering follow-up surveys to students after graduation from college. These data are useful to researchers who, for instance, want to determine the propensity of STEM-educated students to persist in STEM occupations. Another example relates to data from the Business Research and Development and Innovation Survey (BRDIS). Since the BRDIS pilot was conducted in 2008, NCSES has published only one InfoBrief reporting statistics on innovation based on that survey. The 2009, 2010, and 2011 BRDIS data were collected. Users of NCSES’s datasets are eager to analyze the data on innovation from these surveys. However, only researchers with access to U.S. census data at census research data centers can work with BRDIS data. Upon request, NCSES makes statistics derived from these data available in tabular form. 11 The tables include the incidence of innovation in the United States, measures of R&D expenditure, performance and employment domestically and worldwide, and measures of projected R&D costs and intellectual property (e.g., see Borousch, 2010, p. 5). 12
NCSES has long had means through which data users can gain access to microdata, with some stipulations. From time to time, the agency has invited proposals from researchers for use of its datasets, and in 2012 it revived its grants program under the title “Research on the Science and Technology Enterprise: Statistics and Surveys.” This program increases data access for academic and other researchers, potentially yielding dividends in improved S&T indicators, as well as improved methodologies for analyzing and disseminating data and statistics.
Abstracts from the NCSES research awards are given in Appendix E . They show a wide array of topics, including the impact of tax incentives on increasing R&D, factors that affect time to degree for doctoral students, the impact of firms’ economic activities on economic outcomes, differences in employment rates for women and other groups underrepresented in STEM, differences in promotion and retention rates for women and minority professors, experimental methods for assessing ways of mitigating the survey nonresponse problem, and experimental methods for improving recall accuracy on questionnaires. Just this small group of grants shows that NCSES data can be used effectively by researchers to (1) examine the questions the panel heard were critically important to users of STI indicators, especially those that indicators cannot fully address and therefore require analytical research; and (2) inform data extraction and statistical practices that could enhance NCSES’s survey development, its data collection and analysis activities, and ultimately its productivity. Compared with the contract vehicle used by NCSES to produce some of its analytical products, the grants program allows for greater breadth of content through an investigator-initiated research agenda.
RECOMMENDATION 2-1: The National Center for Science and Engineering Statistics should continue its Grants and Fellowships Program for using its datasets, maintaining the high National Science Foundation standards for peer-reviewed award decisions.
One additional issue raised by data users was the need for more up-to-date taxonomies. For example, there is some discrepancy between the Science and Engineering Indicators 2008 figures and those calculated by staff at the National Institutes of Health (NIH) on the number of postdoctoral employees in the medical sector. Several factors could account for this discrepancy, including differences in the data taxonomies used at NCSES and NIH.
A previous National Research Council study (National Research Council, 2005) sponsored by the National Science Foundation (NSF) identified the need for collaborative efforts among federal agencies to review ways in which multiple classifications of science and engineering fields could be reconciled. The study recommended that a follow-on data taxonomy study be conducted to produce consistent definitions of fields and occupations across the sciences,
9 Data curation is the active and ongoing management of data through their life cycle of interest and usefulness to scholarship, science, and education. Data curation enables data discovery and retrieval, maintains data quality, adds value, and provides for reuse over time through activities including authentication, archiving, management, preservation, and representation. (See http://www.lis.illinois.edu/academics/programs/specializations/data_curation [June 2013].)
10 The Survey of Doctorate Recipients (SDR) has been conducted every 2 to 3 years since 1973. It follows a sample of doctorate recipients in science, engineering, and health fields throughout their careers up to age 75. See National Science Foundation (2012c) for more detail on this dataset.
11 From the 2009 BRDIS Table Notes: “There are two types of tables in the table set. Most tables classify survey items by detailed industry, company size, or business code. Table 1 is a different kind of table. It contains aggregate totals for a variety of survey items that may not be tabulated at detailed levels. Since there is a large number of data items in BRDIS, tabulating all of them at a detailed level at this time is impractical and would unduly delay release of the statistics. Consequently, only selected items have been tabulated at the detailed industry, company size, or business code level. Most of the rest of the items are included in Table 1, but only at the aggregate (all industry) level. In the future, NSF intends to add more tables to cover some of the most requested data items that are not currently tabulated at the detailed level.”
12 The panel was able to obtain data tables from NCSES. Chapter 3 and Appendix F of this report provide more detail on NCSES’s datasets and comparable data at other organizations worldwide.
including the health sciences, the social sciences, and engineering. Specifically:
The panel recommends that it is now time for the U.S. Office of Management and Budget to initiate a review of the Classification of Fields of Science and Engineering, last published as Directive 16 in 1978. The panel suggests that OMB appoint the Science Resources Statistics office of the NSF to serve as the lead agency for an effort that must be conducted on a government-wide basis, since the field classifications impinge on the programs of many government agencies. The fields of science should be revised after this review in a process that is mindful of the need to maintain continuity of key data series to the extent possible (Recommendation 6-1). (National Research Council, 2005, p. 127)
Such consistency is particularly important if NCSES data are to be linked with data from other statistical agencies, as is recommended later in this report.
A subsequent NSF-funded NRC study (National Research Council, 2010) included extensive analysis on the issue of data taxonomies for science and engineering statistics. That study found a need for harmonization of data taxonomies on R&D across federal agencies. Below are two relevant excerpts from the report on that study:
The importance of updating the taxonomy to better incorporate interdisciplinary research is widely recognized by policy makers, funding agencies, professional organizations, and across academia. The growing role of research involving more than one discipline is a serious challenge to any taxonomy of fields and therefore to gathering, analyzing, and using federal funds data based on a single-field taxonomy. (National Research Council, 2010, p. 22)
… No single taxonomy will satisfy all. However, for purposes of collecting data on research and development statistics in a consistent manner across federal government agencies, it is necessary to establish a common taxonomy that will be useful to the largest number of data providers and users. In the longer term, a provision can be made for tailoring structures that meet the specific needs of providers and users by flexibly categorizing administrative records. (National Research Council, 2010, p. 32)
The panel that produced the 2010 NRC report did not recommend, however, an immediate broad updating of the science and engineering taxonomy because of concerns about breaks in time series and the difficulties of the task. It limited its formal recommendation to a call for NCSES to “in the near term … make the changes necessary to improve the comparability of the federal funds taxonomy and the taxonomy for the academic research and development expenditures survey” (National Research Council, 2010, Recommendation 3-1, p. 44).
Recognizing the problems of developing classifications that can satisfy a variety of user needs and the need for historical continuity to the extent possible, this panel nonetheless concludes, consistent with the 2005 NRC report, that a broader effort to revise the existing classifications for science and engineering fields and occupations is long overdue. Changes in the U.S. economy led to a government- and continent-wide effort to develop what became the North American Industry Classification System in 1997, which is regularly updated every 5 years and has enabled federal statistics to take cognizance of the growth of the service sector and other changes in the economy. So, too, is it important to update the science and engineering taxonomy, given the evolution of new areas of science and the growth of interdisciplinary research. Indeed, NCSES has undertaken some work along these lines, which it is important to continue and to step up to the extent feasible. It is also important for these efforts to include development of a process for performing updates as needed.
RECOMMENDATION 2-2: The National Center for Science and Engineering Statistics should engage with other statistical agencies, including but not limited to the Bureau of Labor Statistics, the U.S. Census Bureau, the National Center for Education Statistics, and the National Institutes of Health, to develop a consistent taxonomy of science and engineering fields and occupations (including the health and social sciences). There should also be an established process for performing updates of this taxonomy as needed.
Users of STI Indicators
Issue-driven requests for analytical measures are legion, and NCSES does not have the capacity to develop indicators for all issues. As discussed in Chapter 1 , moreover, indicators address but cannot fully answer most of the policy questions posed regarding the functioning of the STI system. Therefore, priorities need to be set regarding (1) which issues indicators can address, at least in part; (2) which users’ needs will be met; (3) where high-quality indicators will be obtained absent processing in house; and (4) where additional dollars will be spent and what will be produced less frequently or not at all should funds decrease. The remainder of this chapter focuses on the first two questions; the latter two relate to make-buy decisions for NCSES and strategic expenditures on activities within the agency, which the panel believes are for NSF staff to determine.
User-identified high-priority STI indicators are listed in Box 2-2 . The list is broken down by the categories in Figure 2-1 —STI activities, outputs and outcomes, and linkages; metrics related to actors and intermediate inputs in the system appear under activities and outcomes. Although the list is extensive, it represents only a subset of the measures users said they wanted to have, either specifically from NCSES or in general. The panel used its collective expertise to determine which indicators from that total set should be
deemed priorities for NCSES, focusing in particular on the utility of indicators in the policy context. The panel also considered other factors that could be used to prioritize STI indicators produced by NCSES, including ease of acquisition, cost, flexibility, and periodicity (see Figure 1-1 in Chapter 1 ). These factors often were difficult for the panel to ascertain. For example, the cost of producing any given indicator depends on the type of data (survey, unstructured, administrative) required, the need to link to other datasets that NCSES might have to acquire, the possibility that NCSES would have to invest in new skill sets in house to use new data acquisition and manipulation techniques, and so on. Therefore, the panel focused primarily on high-utility indicators; suggestions are offered later in the report on how to acquire new types of data and the skill sets needed to work with those data.
This report reflects the systems framework of STI activities shown earlier in Figure 2-1 . However, the lines between activities and outcomes (inputs and outputs) are imprecise, and attempts to draw them are imperfect. Therefore, linkages between various elements of the system are highlighted throughout the report to help the reader appreciate why a suite of indicators is important for a fuller understanding of drivers, trends, advances, and vulnerabilities in the global STI system.
International Comparability
Because one of the primary goals of this study was to determine how to improve the comparability of STI indicators in the United States and abroad, the panel discussed priorities for indicators with internationally known experts in the field during its two workshops. Several recurring themes emerged from these discussions.
First, mapping and understanding the innovation system (or system of systems) is important. However, priorities for indicator development are driven by policy makers’ queries.
Second, understanding and producing indicators on the commercialization of publicly funded knowledge is a priority. Linkage indicators need to show the flow of knowledge from public institutions to businesses and from businesses to the market, leading to social and economic impacts. This flow of knowledge includes highly qualified people as well as licenses for intellectual property and R&D services. Thus, it is important to have good measures of the STEM workforce and other talent employed in S&T sectors. In addition, measures of knowledge assets (including those considered intangible) and innovation are a high priority for improved measurement.
Third, the development of STI indicators at different geographic scales and for a variety of sectors is a priority. Other distributional elements of the STI system also are important, including characteristics of people—their gender, age, level of education and experience, and willingness to take risks and be entrepreneurial, as well as their employment and mobility. Measures of social capital that affect the development and diffusion of knowledge capital are important indicators of STEM talent. The characteristics of firms matter, too—their location, size, rate of employment and revenue growth, entrepreneurial characteristics, and complexity (multinational corporations are different from small and medium-sized firms).
Fourth, outcome measures are necessary but not well developed. It is important to have internationally comparable measures of innovation and of its social and economic impacts.
Finally, there is a need to measure innovation that is not the direct result of R&D expenditures. This class of indicators could begin to answer questions about what governments obtain in return for their funding and how their expenditures affect productivity, economic growth, and job creation.
Dahlman (2012) discusses the “changing geography of innovation,” with a focus on the engineered emergence of technological capabilities in Brazil, China, and India. In addition to measures of innovation activities that are used in the developed-country context, Dahlman presents several indicators that are particularly useful early warning signals of the potential for ascendency of a developing country in the international innovation system. These indicators include (1) human capital (enrollments in higher education outside the home country, number of back-expatriated citizens, number of top foreign scientists recruited by local universities and industry); (2) R&D expenditure (information-enabled service industries and knowledge services); (3) learning (investments from transnational corporations, including locations of research, development, and engineering functions; exports and imports with the rest of the world; technology licensing and S&T cooperative agreements at home and abroad); (4) institutions (regulations, including protection of property rights, trade restrictions at home and abroad); (5) intermediate and final outputs (share of total world R&D); 13 (6) domestic demand for high-technology products (including alternative energy technologies); 14 and (7) social outcomes (income inequality; measures of children’s access to education, health care, and food; programs that support product, process, and service innovations that address the needs of low-income populations).
NCSES publishes many STI indicators that are comparable to those available in OECD’s 2011 Science, Technology, and Industry Scoreboard; the Cornell-INSEAD-World Intellectual Property Organization (WIPO) Global Innovation Index 2013; and the European Union’s Innovation Union Scoreboard 2013. NCSES is most prolific in international
13 Dahlman (2012, p. 6) states that “….there has been concern about significant fraud and cheating in research and scientific publications and that many patents are of little value. The argument is that this activity has proliferated because promotions and salary increases in universities and research labs have been reoriented to be based on publications and patenting.”
14 “Domestic demand conditions” is one of Porter’s (1990) four determinants of national competitive advantage.
BOX 2-2 Key Indicators Suggested by Major Users of STI Indicators
Research and Development (R&D)
- National R&D expenditures
- Federal and state funds for basic research
- Public-sector R&D (focus on advanced manufacturing, green technologies, energy-related R&D, nanotechnology, agriculture, weapons)
- Public R&D spending as a share of gross domestic product (GDP)
- Business R&D spending
- Business R&D as a share of GDP
- Industry support for R&D in universities
- Social science R&D
- National R&D performance (by type of industry and source of funds)
- Trends in grant size to universities
- Number of R&D centers in the United States and other countries
- Direct measures of innovation (data similar to those from the Community Innovation Survey)
- Ratings for propensity to innovate
- Subject matter experts (SMEs) innovating in house as a share of SMEs
- Firms (<5, 5+, 10+, 20+ employees) introducing new or significantly improved products or processes as a share of all firms
- Firms (<5, 5+, 10+, 20+ employees) introducing new or significantly improved goods or services as a share of all firms
- Firms (<5, 5+, 10+, 20+ employees) introducing marketing or organizational innovations as a share of all firms
- Numbers and types of new products per year, by region ( Thomasnet.com )
- Drug and other approvals per year, by region
- Sale of new-to-market and new-to-firm innovations as a share of turnover
- Non-R&D expenditures on innovation activities and non-R&D innovation spending as a share of turnover
- Inclusive innovation for development (case studies)
- Capital expenditures related to the introduction of new processes
- Marketing expenditures related to new products
- Expenditures on design and technical specifications
- Expenditures on service-sector innovation
- Investment in new information and communication technology (ICT) hardware and software
- Innovation inhibitors (case studies)
Market Capital Investments
- Venture capital investments in science and technology (S&T) (early-stage, expansion, and replacement) and venture capital investments in S&T as a share of GDP
- Number of initial public offerings (IPOs) in S&T
- Number of S&T spinoffs
- Expenditures in later phases of development/testing that are not included in R&D
Outputs and Outcomes
Commercial Outputs and Outcomes
- Performance of high-growth small and large firms
- High-growth enterprises as a share of all enterprises
- Medium- and high-tech manufacturing exports as a share of total product exports
- Knowledge-intensive service exports as a share of total service exports
- Value added in manufacturing
- Value added in technical services
- Trade flows of S&T products and services
- ICT outputs and sales (intermediate and final)
- Other intermediate inputs
- Technology balance of trade (especially intellectual property)
- Contracts to S&T firms
- Advanced manufacturing outputs (information technology-based processes)
- Market diffusion activities
- Emerging industries (based on universities, government laboratories, firms, value chains, key occupations, and individuals)
- Help-wanted ads, “how to” books, and other derivative STI activities
- Use and planned use of general-purpose technologies
Knowledge Outputs
- U.S. receipts and royalty payments from foreign affiliates
- U.S. patent applications and grants by country, technology
- U.S. trademark applications and grants by country, technology
- Patent citations
- License and patent revenues from abroad as a share of GDP
- Triadic patent families by country
- Percentage of patent applications per billion GDP
- Percentage of patent applications related to societal challenges per billion GDP (e.g., climate change mitigation, health)
- Intangible assets
- Average length of a firm’s product life cycle or how often the firm usually introduces innovations
- Births and deaths of businesses linked to innovation outputs; firm dynamics by geography, industry, business size, and business age
- Knowledge depreciation
- Knowledge stocks and flows in specific sectors, including nanotechnology; information technology; biotechnology and agriculture research (local foods, organic foods, biofuels, environment, nutrition, health); oil and gas production; clean/green energy; space applications; weapons; health care technologies; educational technologies (massive open online courses [MOOCs]); and mining
Science, Technology, Engineering, and Mathematics (STEM) Education
- Expenditures, direct and indirect costs, investments, revenues, and financing for STEM education
- Percentage of faculty in nonteaching and nonresearch roles at universities
- Enrollment data by STEM field at various levels (e.g., associate’s, bachelor’s, master’s, doctorate) and for various types of institutions
- New degrees (e.g., associate’s, bachelor’s, master’s, doctorate); new doctoral graduates per 1,000 population aged 25-34
- Stock of degrees (e.g., associate’s, bachelor’s, master’s, doctorate)
- Share of population aged 30-34 having completed tertiary education
- Share of youth aged 20-24 having attained at least upper-secondary-level education
- Persistence and dropout rates in education, by geographic and demographic distinctions
- Number of high school students pursuing associate’s degrees and implications for the workforce and the cost of higher education
- Disciplines in which community colleges have a relative advantage
- Foreign-born STEM-educated individuals—country of birth, immigration visas, etc.
- Stay rates of foreign students
- Trends in online learning and MOOCs
STEM Workforce/Talent
- Postdoctoral levels and trends in various STEM fields, by country of birth and country of highest degree
- Number of postdoctorates in health, but specific fields
- STEM employment
- Labor mobility and workforce migration
- Demographic composition of people who would enter specific occupations (e.g., clean energy, ICT, biotechnology, health services)
- Fraction of STEM degree holders that hold STEM jobs
- Earnings by degree type and occupation
- Feeder fields in agricultural science
- On-the-job training activities in S&T, manufacturing, and services
- STEM demand
- Employment in knowledge-intensive activities (manufacturing and services) as a share of total employment
Socioeconomic Impacts/Well-Being
- Economic growth
- Productivity
- Other measures of impact on GDP and jobs
- Agricultural preparedness
- Energy preparedness
- Return on investment (ROI) on grants to universities, by type of S&T
- National security/defense
- Environment
- Geographic hot spots
Organizations/Institutions/Infrastructure
- Public-private copublications per million population
- University-industry research collaborations
- Number and value of international collaborations
- Business structure dynamics
- Technology transfer between academic institutions and businesses, including mechanisms
indicators of human capital stocks and flows, 15 and it has many essential indicators of firm activities in R&D, innovation, and knowledge-intensive services; financial expenditures; patent grants; and international trade in high-technology products. As discussed in Chapters 4 through 6 of this report, however, there are elements of innovation, knowledge generation, knowledge networks and flows, and even human capital for which NCSES should consider expanding its portfolio of indicators. Doing so would improve the comparability of STI indicators internationally, thereby improving the utility of these measures for a variety of users.
Subnational Statistics 16
Users want more disaggregated STI information on multiple levels. They want STI comparisons across U.S. regions and between U.S. and foreign regions. Cooke and
15 For example, NCSES’s InfoBriefs and the National Science Board’s Science and Engineering Indicators volume (for which NCSES provides statistical indicators) include the following statistics: enrollments in master’s and Ph.D. science and engineering programs in the United States by countries or economic regions of origin; baccalaureate origins of U.S.trained science and engineering doctorate recipients; number of science and engineering degrees earned in foreign countries; international mobility and employment characteristics of recent U.S. doctorates, including stay rates; employment in R&D activities worldwide, with specifics on R&D workers in multinational corporations; and international collaborations of scientists and engineers in the United States.
16 This report uses the term “subnational” instead of “regional” to denote geographic areas that are defined within a nation’s boundaries. While the term “regional” is used extensively in the literature to denote states or provinces, standard metropolitan statistical areas (SMSAs), or even well-defined industry clusters, the term is also used in reference to clusters of countries (e.g., the North American region or the Pacific Rim). Cooke and Memedovic (2003, p. 5) give useful criteria for defining a region or subnational area: “(1) a region must not have a determinate size, (2) it is homogeneous in terms of specific criteria, (3) it can be distinguished from bordering areas by a particular kind of association of related features, and (4) it possesses some kind of internal cohesion. It is also important to mention that the boundaries of regions are not fixed once for all; regions can change, new regions can emerge and old ones can perish.”
- Technology transfer (Manufacturing Extension Partnership [MEP])
- Technology transfer from national laboratories
- Bilateral S&T agreements (including international)
- Collaboratories
- Industry clusters
- Consortia (Defense Advanced Research Projects Agency [DARPA], Advanced Research Projects Agency-Energy [ARPA-E], Technology Innovation Program [TIP])
- Intellectual property rights and policies
- Market planning assistance (Department of Commerce [DoC], Bureau of Labor Statistics [BLS], Small Business Administration [SBA])
- Research and experimentation (R&E) tax credits (federal and state)
- Innovative SMEs collaborating with others as a share of SMEs
- Alumni contributions to R&D
- Communications linkages (including broadband)
- Public value of S&T
- Business climate
- Entrepreneurial activities
- Mappings of entrepreneurial density
- All establishments and firms with at least one employee, including start-ups, 1976 to the present
- All nonemployer firms and integrated-with-employer firms, 1994 to the present
- All employer-employee matches and transitions (hires, separations, job creation, and job destruction) 1990 to the present
- Information on innovation policy and its outcomes (contexts; national, regional, sectoral levels)
- Data on the existence of dealmakers and entrepreneurs and their connections in a given market
- Risk tolerance
- Social networks
- Social capital
Memedovic (2003, p. 31) surmise that “global economic forces have raised the profile of regions and regional governance not least because of the rise to prominence of regional and local business clusters as vehicles for global and national economic competitiveness.” Hollanders (2013, p. 79) states that “regions are increasingly becoming important engines of economic development.” Drawing on comparisons at the subnational level, Hollanders finds that understanding various components of the innovation system at this level yields useful insights into performance outcomes at the country level. A key caveat, however, is that subnational STI statistics are scarce relative to comparable national statistics. Furthermore, Hollanders asserts that comparing small countries (such as Bahrain and Cyprus) to large countries such as (China and India) clouds the ability to determine what he terms “best practices.” Hollanders (2013, p. 84) states:
Applying best practices from these large countries to smaller ones will be difficult because of the differences in scale. We need to be able to compare smaller countries with regions of larger countries that are similar to the smaller countries in size or in industrial structure. Such a comparison requires a breakdown of country-level statistics into regional statistics, where regions should not be defined as static administrative regions, … but rather as economic regions that can be distinguished from bordering regions and that should have a certain degree of internal cohesion. There are no guidelines for determining the “ideal” region, but large metropolitan areas seem to emerge as a natural category.
Research shows that innovation depends on many factors that together contribute to the success or failure of a given idea and therefore is highly local. The particular arrangement of R&D facilities, industry concentration, labor force skills, and labor mobility makes the local setting productive (see, e.g., Belleflamme et al., 2000; Braunerhjelm and Henrekson, 2013; Clark et al., 2003). A substantial body of evidence shows that these local settings have been highly influential in creating concentrations of innovation over the past century (see, e.g., Audretsch et al., 2005). For example, Route 128 around Boston saw the emergence of new industries and
relationships in the 1950s and 1960s characterized by a complex interaction among venture capital, real estate promoters, and major research universities; Silicon Valley subsequently emerged as the focal point for a range of new products and services (these two cases are considered in great detail by Saxenian [1996]; see also Gertler et al., 1995; Link and Scott, 2003). Some of the most successful clusters of innovation have far exceeded any original plans, arising from particular combinations that others have tried to replicate with varying degrees of success. State laws vary on postemployment covenants (also known as noncompete agreements), which can have differential effects on entrepreneurial outcomes (Marx and Fleming, 2012). Many cities have explicit policies for incubators, including some that have produced tangible results for the region and the economy as a whole (see, e.g., Tödtling and Trippl, 2005). Yet such policies are not panaceas and at times produce measured successes or failed outcomes. Therefore, it is critically important to have a variety of information, including subnational STI indicators that can inform judgment on whether such expenditures should continue and whether the portfolio of programs is optimal.
Countries other than the United States have more explicit regional strategies for fostering innovation, established over longer time frames (Cooke and Memedovic, 2003; Falck and Heblich, 2008). In recent years, for example, much of the funding for innovation in the European Union has been channeled through regional initiatives. The federal structure of the United States obscures some of the explicit regional strategies across states and in a complex collection of regional bodies, some spanning multiple states. Yet many U.S. policies that support innovation are at the local level, where industries are created and incubated.
Thus, local decision makers need indicators for their specific region in comparison with others; no single geographic subdivision scheme will serve all needs. Demographic statistics often are tabulated by legislated entities (e.g., states, counties, cities) because of the constitutional relationship to representation. These entities, though easily recognizable, may not well represent the economic realities of market areas and regional variation. Consider the vast commercial and demographic variability within some states, such as California, compared with the relative homogeneity of a state like Delaware. These two states are not at the same scale analytically, yet each needs indicators to manage its investments. A confounding factor is that economic information has another hierarchy—from the industry to firm to plant or establishment level. Only the finest level has a spatial expression, and therefore raises questions of subnational policy relevance. Some states, particularly those dependent on sales tax revenues and other highly cyclical sources, expend great effort in operating their own economic models at subnational scales. The decentralized way in which these local needs are being met makes it difficult to develop a national scheme for integrated information management.
During the panel’s July 2011 workshop, Robert Atkinson of the Information Technology and Innovation Foundation said subnational information would be particularly helpful for technology and innovation policy. Other workshop participants described subnational decompositions in several countries. Based on her extensive research on STI hot spots, Maryann Feldman of the University of North Carolina emphasized that economic growth does occur within these finer geographic units. She went on to stress that decision makers in the states and metropolitan areas need data on innovation activities at the subnational level. She suggested NCSES work with users to determine what statistics would be useful at this level and what some users have already created that could serve as useful inputs for NCSES’s subnational indicators.
At the workshop, representatives of the Association of Public and Land-grant Universities (APLU) David Winwood and Robert Samors presented an overview of the Commission on Innovation, Competitiveness, and Economic Prosperity (CICEP) project. They noted that APLU would like universities and other organizations to collect dozens of measures on a wide range of topics, especially numbers, types, and dollar amounts for research activities funded by private-sector entities (e.g., consortia, trade associations, companies); similar information for federal, state, or foundation sources of funding; numbers of students participating in work-related activities, regardless of whether they earn academic credit for those activities; numbers of full-time equivalent employees engaged in sponsored research-related activities; and equity investments in university technology development activities by graduates of the institutions, as well as other types of investors. 17
In summary, comparing the almost two dozen subnational measures requested by users at the panel’s workshop with the information from APLU’s questionnaire exercise and with findings in the literature on regional innovation systems (e.g., Cooke and Memedovic, 2003, p. 17; Hollanders, 2013, p. 80) reveals the following to be high-priority subnational STI indicators: (1) academic R&D expenditures; (2) federal R&D expenditures (some of which are directed to academic institutions and private firms); (3) industry expenditures on R&D, including support for academic research; (4) non-R&D innovation expenditures; (5) STI equity investments (from various sources, including venture capital); (6) sales of products new to the firm (noting distortions introduced by multiplant, multisector firms); (7) share of the population aged 26-64 with tertiary degrees or engaged in certificate training programs; (8) employment in knowledge-intensive manufacturing and services; (9) knowledge transfer and other linkages between academic institutions and industry (e.g., public-private scientific copublications per million
17 This information was circulated to participants at an APLU workshop in October 2012. APLU staff developed a list of 11 first-tier and 23 second-tier priority metrics from a pilot test of a questionnaire administered to its membership universities.
population); and (10) infrastructure investments (e.g., broadband access). These and many other indicators were requested at both the national and subnational levels and are included in Box 2-2 presented earlier. NCSES produces indicators in many of these categories at the state level. 18 However, users are interested in an expanded set of subnational indicators at finer geospatial scales. Although expenditures on STI activities are at times determined by state legislators, venture capital investments and some economic outcomes are better observed in metropolitan areas or in smaller economic clusters.
One should not presume, however, that arriving at national aggregates based on subnational data is at all straightforward. The panel was advised during the workshop that the pursuit of more subnational STI indicators at the state and even local levels is fraught with problems of distribution and aggregation.
CAUTIONS, POSSIBILITIES, AND LIMITATIONS
Although the production of indicators across many fields has an established history, at least three major cautions regarding their use are important to note.
First, indicators can send mixed signals that require expert judgment for interpretation. For example, it is commonly held that increased innovation—which is key to advancing living standards—enhances job creation, and policy makers discuss spurring innovation as a job creation tactic. However, innovation can lead to fewer jobs if the process or managerial expertise increases efficiency. On the other hand, short-term displacement of workers in one industry or sector can be counterbalanced in the longer term by the development of new products, services, and even sectors and by increased market demand if process efficiencies drive down prices (see Pianta, 2005; Van Reenen, 1997). One way to be cautious about mixed signals is to develop STI indicators that support analysis of time scales, sectors, and geographic locations.
Second, once a given metric becomes widely used, it may change the behavior of the people and practices it attempts to measure. The worst thing a metric can do is not only deliver a bad (i.e., misleading) answer but also incentivize bad practice—that is, decisions or policies that are counterproductive (see, e.g., West and Bergstrom, 2010). It is important that indicators not send distorted signals to users.
Third, not everything that counts can be counted, and not everything that can be counted counts. Some outcome measures that reflect the importance of R&D and innovation to society are elusive. For example, social well-being is difficult to measure, yet one of the key interests of policy makers is the return on investment of public funding for S&T for the good of society.
For this study, Bronwyn Hall and Adam Jaffe prepared a commissioned paper that in part takes up the notion of a policy-driven framework for STI indicators. As mentioned in Chapter 1 , Hall and Jaffe (2012, p. 39) give a balanced view of the extent to which users can rely on indicators to address key issues, making a strong case for the need for improved metrics that can be used for analytical purposes. Their observations are worth quoting at length here:
Overall level of public investment in R&D . Implicitly, the Congress and the President are continuously deciding what overall level of resources to invest in new knowledge creation through the R&D process. Ideally, this would be informed by data showing the marginal rate of return on these investments. But marginal rates of return are very difficult to measure. Economists and others have made estimates of the average rate of return to R&D investments (Hall et al., 2010). Within the model, the marginal rate of return declines with the intensity of R&D investment (R&D/GDP) other things equal, so a high average rate of return is a necessary but not sufficient condition to justify increased investment.
In the absence of explicit information, R&D intensity measures do provide some implicit evidence on the rate of return. Economic models typically presume that there are diminishing returns to increased R&D expenditure, so that the rate of return to R&D will fall as R&D/GDP rises. This means that if today’s U.S. R&D/GDP ratio is lower than at another point in time, we may be able to infer that the rate of return in the U.S. today is higher than it was at that point of time, assuming that nothing else has changed. The same argument applies when comparing R&D intensities across countries, although it is even more difficult to assume that other things are equal in that case. Thus if we have some reason to believe that the investment level was right at some point in time, then we might be able to infer that the implied high rate of return in the United States today justifies a higher level of investment (and vice versa if today’s U.S. R&D intensity is higher than at some other time or place). However, given all the uncertainties, it would probably be better to attempt to measure the return to R&D spending in this case.
Overall level of public investment in education and training . The issues with respect to the optimal level of investment in education and training are analogous to those related to R&D. We would, ideally, like to have measures of the rate of return; measures of the current ratio of investment to GDP may provide indirect evidence on the rate of return, at least relative to other times or places. In addition, public policy may view having an educated public as a desirable end in itself, over and above any return it may provide in terms of innovation and technology. If so, then data on years of schooling and degrees awarded are useful policy indicators independent of their indirect implications for the economic rate of return.
Education and training also take many forms and occur in
18 NCSES’s state-level indicators are available in the following areas: elementary, secondary, and tertiary education; workforce; financial R&D inputs; R&D outputs; and S&T in the state economy (including venture capital activity, Small Business Innovation Research awards, and high-technology business activity).
many different contexts. We have better data on what occurs in formal educational institutions than we have on training that occurs on the job, or is otherwise provided by firms without recourse to formal educational institutions.
Allocation of both of above by scientific/technical area or area of ultimate application . Even more than the overall determination of public investment, the government must continuously decide the allocation of public resources for R&D and education/training across scientific and technical fields, and across areas of application. Again, within the model the most relevant information for these decisions would be the marginal rates of return. And again, these are hard to measure, and measurements of average rates of return are incomplete as indicators of marginal rates. In addition, there are substantial spillovers across scientific fields (e.g., the importance of computer science for DNA analysis) so that localized rates of return may not capture the true importance of some fields.
The relevance of investment intensity measures as indirect indications of marginal rates of return is more complex in the context of allocation across fields or sectors. If the inherent technological opportunity is greater in a given sector, then its marginal returns are higher at any given level of investment. Thus it is possible, for example, that our much higher level of public investment in research in health sciences than in other fields represents an implicit belief that technological opportunity, and hence marginal returns, are higher in that area than in others. On the other hand, no other country in the world devotes such a large share of its public research investment to health sciences. Unless the variation of technological opportunity across fields is different in different countries, comparative benchmarking on sectoral allocations may provide indirect evidence on rates of return. As noted above, however, this is a particularly problematic sector due to the difficulty of measuring output properly and the fact that health improvements are not completely captured by national income accounts.
Allocation of federal R&D and training resources by types of institutions (e.g., intramural versus extramural or universities versus firms) . Allocation of public resources across different kinds of institutions raises the same issue of relative rates of return as allocation across sectors. In addition, different kinds of institutions play different roles in the STI system. Hence, indicators reflecting intermediate outputs of the research process, and flows of knowledge within the system, might be informative about imbalances within the system. It would also be useful to construct and publicize more detailed statistics on the demand for S&T skills in certain areas, including starting salaries, in a timely manner.
Science and technology policy choices other than spending . Many government policy choices explicitly or implicitly affect the STI system, including R&D subsidies (and other tax policies), intellectual property rules, and mechanisms for the transmittal of funds (e.g., basic research grants, contract research, prizes, etc.). It is not clear that indicators, as we normally think of them, shed light on the relative efficacy of different policy choices of this kind. But the data collected as the basis for indicators can also be used by social scientists to study the relative effectiveness of different mechanisms. In fact, these data are essential for this purpose.
Immigration policy (as applied to scientific/technical workers) . Indicators related to the number and fields of scientific and technical workers, combined with the level of investment in research, may be useful for informing the nature and extent of visa programs to allow more technically trained immigrants to work in the United States.
Indicators for use by university administrators or firm managers. Firm managers and university administrators face many of the same choices as governments: how much to spend and what to spend it on. Many of them rely to some extent on benchmarking, that is, observing the spending patterns of their immediate competitors. Therefore, the same kinds of data as described above can be useful, preferably broken down by sector and by geography.
This chapter has presented a long list of indicators that users want to have, mainly to address key STI policy issues. Users requested many more indicators, but these did not rise to the level of importance of those listed in this chapter. This chapter also has offered two recommendations, focused on (1) continuation of NCSES’s Grants and Fellowships Program and (2) collaboration between NCSES and other statistical agencies to develop a consistent taxonomy of science and engineering fields and occupations.
With the focus on NCSES’s decision-making challenges in the future, the panel took on the task of prioritizing the measures NCSES should produce in the near term and identifying the processes it should develop to satisfy users’ future demands. The results of this effort are presented in Chapters 3 and 8 , where the panel respectively identifies key policy-relevant STI indicators and strategic organizational principles for continuously developing those indicators as technology, economic, and policy environments change globally.
Since the 1950s, under congressional mandate, the U.S. National Science Foundation (NSF) - through its National Center for Science and Engineering Statistics (NCSES) and predecessor agencies - has produced regularly updated measures of research and development expenditures, employment and training in science and engineering, and other indicators of the state of U.S. science and technology. A more recent focus has been on measuring innovation in the corporate sector. NCSES collects its own data on science, technology, and innovation (STI) activities and also incorporates data from other agencies to produce indicators that are used for monitoring purposes - including comparisons among sectors, regions, and with other countries - and for identifying trends that may require policy attention and generate research needs. NCSES also provides extensive tabulations and microdata files for in-depth analysis.
Capturing Change in Science, Technology, and Innovation assesses and provides recommendations regarding the need for revised, refocused, and newly developed indicators of STI activities that would enable NCSES to respond to changing policy concerns. This report also identifies and assesses both existing and potential data resources and tools that NCSES could exploit to further develop its indicators program. Finally, the report considers strategic pathways for NCSES to move forward with an improved STI indicators program. The recommendations offered in Capturing Change in Science, Technology, and Innovation are intended to serve as the basis for a strategic program of work that will enhance NCSES's ability to produce indicators that capture change in science, technology, and innovation to inform policy and optimally meet the needs of its user community.
READ FREE ONLINE
Welcome to OpenBook!
You're looking at OpenBook, NAP.edu's online reading room since 1999. Based on feedback from you, our users, we've made some improvements that make it easier than ever to read thousands of publications on our website.
Do you want to take a quick tour of the OpenBook's features?
Show this book's table of contents , where you can jump to any chapter by name.
...or use these buttons to go back to the previous chapter or skip to the next one.
Jump up to the previous page or down to the next one. Also, you can type in a page number and press Enter to go directly to that page in the book.
Switch between the Original Pages , where you can read the report as it appeared in print, and Text Pages for the web version, where you can highlight and search the text.
To search the entire text of this book, type in your search term here and press Enter .
Share a link to this book page on your preferred social network or via email.
View our suggested citation for this chapter.
Ready to take your reading offline? Click here to buy this book in print or download it as a free PDF, if available.
Get Email Updates
Do you enjoy reading reports from the Academies online for free ? Sign up for email notifications and we'll let you know about new publications in your areas of interest when they're released.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Published: 22 April 2015
Bibliometrics: The Leiden Manifesto for research metrics
- Diana Hicks 1 ,
- Paul Wouters 2 ,
- Ludo Waltman 2 ,
- Sarah de Rijcke 2 &
- Ismael Rafols 3
Nature volume 520 , pages 429–431 ( 2015 ) Cite this article
64k Accesses
1270 Citations
2083 Altmetric
Metrics details
- Research management
Use these ten principles to guide research evaluation, urge Diana Hicks, Paul Wouters and colleagues.

Data are increasingly used to govern science. Research evaluations that were once bespoke and performed by peers are now routine and reliant on metrics 1 . The problem is that evaluation is now led by the data rather than by judgement. Metrics have proliferated: usually well intentioned, not always well informed, often ill applied. We risk damaging the system with the very tools designed to improve it, as evaluation is increasingly implemented by organizations without knowledge of, or advice on, good practice and interpretation.
Before 2000, there was the Science Citation Index on CD-ROM from the Institute for Scientific Information (ISI), used by experts for specialist analyses. In 2002, Thomson Reuters launched an integrated web platform, making the Web of Science database widely accessible. Competing citation indices were created: Elsevier's Scopus (released in 2004) and Google Scholar (beta version released in 2004). Web-based tools to easily compare institutional research productivity and impact were introduced, such as InCites (using the Web of Science) and SciVal (using Scopus), as well as software to analyse individual citation profiles using Google Scholar (Publish or Perish, released in 2007).
In 2005, Jorge Hirsch, a physicist at the University of California, San Diego, proposed the h -index, popularizing citation counting for individual researchers. Interest in the journal impact factor grew steadily after 1995 (see 'Impact-factor obsession').
Lately, metrics related to social usage and online comment have gained momentum — F1000Prime was established in 2002, Mendeley in 2008, and Altmetric.com (supported by Macmillan Science and Education, which owns Nature Publishing Group) in 2011.
As scientometricians, social scientists and research administrators, we have watched with increasing alarm the pervasive misapplication of indicators to the evaluation of scientific performance. The following are just a few of numerous examples. Across the world, universities have become obsessed with their position in global rankings (such as the Shanghai Ranking and Times Higher Education 's list), even when such lists are based on what are, in our view, inaccurate data and arbitrary indicators.
Some recruiters request h -index values for candidates. Several universities base promotion decisions on threshold h -index values and on the number of articles in 'high-impact' journals. Researchers' CVs have become opportunities to boast about these scores, notably in biomedicine. Everywhere, supervisors ask PhD students to publish in high-impact journals and acquire external funding before they are ready.
In Scandinavia and China, some universities allocate research funding or bonuses on the basis of a number: for example, by calculating individual impact scores to allocate 'performance resources' or by giving researchers a bonus for a publication in a journal with an impact factor higher than 15 (ref. 2 ).
In many cases, researchers and evaluators still exert balanced judgement. Yet the abuse of research metrics has become too widespread to ignore.
We therefore present the Leiden Manifesto, named after the conference at which it crystallized (see http://sti2014.cwts.nl ). Its ten principles are not news to scientometricians, although none of us would be able to recite them in their entirety because codification has been lacking until now. Luminaries in the field, such as Eugene Garfield (founder of the ISI), are on record stating some of these principles 3 , 4 . But they are not in the room when evaluators report back to university administrators who are not expert in the relevant methodology. Scientists searching for literature with which to contest an evaluation find the material scattered in what are, to them, obscure journals to which they lack access.
We offer this distillation of best practice in metrics-based research assessment so that researchers can hold evaluators to account, and evaluators can hold their indicators to account.
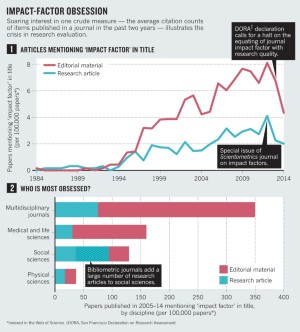
Ten principles
1) Quantitative evaluation should support qualitative, expert assessment. Quantitative metrics can challenge bias tendencies in peer review and facilitate deliberation. This should strengthen peer review, because making judgements about colleagues is difficult without a range of relevant information. However, assessors must not be tempted to cede decision-making to the numbers. Indicators must not substitute for informed judgement. Everyone retains responsibility for their assessments.
2) Measure performance against the research missions of the institution, group or researcher. Programme goals should be stated at the start, and the indicators used to evaluate performance should relate clearly to those goals. The choice of indicators, and the ways in which they are used, should take into account the wider socio-economic and cultural contexts. Scientists have diverse research missions. Research that advances the frontiers of academic knowledge differs from research that is focused on delivering solutions to societal problems. Review may be based on merits relevant to policy, industry or the public rather than on academic ideas of excellence. No single evaluation model applies to all contexts.
3) Protect excellence in locally relevant research. In many parts of the world, research excellence is equated with English-language publication. Spanish law, for example, states the desirability of Spanish scholars publishing in high-impact journals. The impact factor is calculated for journals indexed in the US-based and still mostly English-language Web of Science. These biases are particularly problematic in the social sciences and humanities, in which research is more regionally and nationally engaged. Many other fields have a national or regional dimension — for instance, HIV epidemiology in sub-Saharan Africa.
This pluralism and societal relevance tends to be suppressed to create papers of interest to the gatekeepers of high impact: English-language journals. The Spanish sociologists that are highly cited in the Web of Science have worked on abstract models or study US data. Lost is the specificity of sociologists in high-impact Spanish-language papers: topics such as local labour law, family health care for the elderly or immigrant employment 5 . Metrics built on high-quality non-English literature would serve to identify and reward excellence in locally relevant research.
4) Keep data collection and analytical processes open, transparent and simple. The construction of the databases required for evaluation should follow clearly stated rules, set before the research has been completed. This was common practice among the academic and commercial groups that built bibliometric evaluation methodology over several decades. Those groups referenced protocols published in the peer-reviewed literature. This transparency enabled scrutiny. For example, in 2010, public debate on the technical properties of an important indicator used by one of our groups (the Centre for Science and Technology Studies at Leiden University in the Netherlands) led to a revision in the calculation of this indicator 6 . Recent commercial entrants should be held to the same standards; no one should accept a black-box evaluation machine.
Simplicity is a virtue in an indicator because it enhances transparency. But simplistic metrics can distort the record (see principle 7). Evaluators must strive for balance — simple indicators true to the complexity of the research process.
Simplicity is a virtue in an indicator because it enhances transparency.
5) Allow those evaluated to verify data and analysis. To ensure data quality, all researchers included in bibliometric studies should be able to check that their outputs have been correctly identified. Everyone directing and managing evaluation processes should assure data accuracy, through self-verification or third-party audit. Universities could implement this in their research information systems and it should be a guiding principle in the selection of providers of these systems. Accurate, high-quality data take time and money to collate and process. Budget for it.
6) Account for variation by field in publication and citation practices. Best practice is to select a suite of possible indicators and allow fields to choose among them. A few years ago, a European group of historians received a relatively low rating in a national peer-review assessment because they wrote books rather than articles in journals indexed by the Web of Science. The historians had the misfortune to be part of a psychology department. Historians and social scientists require books and national-language literature to be included in their publication counts; computer scientists require conference papers be counted.
Citation rates vary by field: top-ranked journals in mathematics have impact factors of around 3; top-ranked journals in cell biology have impact factors of about 30. Normalized indicators are required, and the most robust normalization method is based on percentiles: each paper is weighted on the basis of the percentile to which it belongs in the citation distribution of its field (the top 1%, 10% or 20%, for example). A single highly cited publication slightly improves the position of a university in a ranking that is based on percentile indicators, but may propel the university from the middle to the top of a ranking built on citation averages 7 .
7) Base assessment of individual researchers on a qualitative judgement of their portfolio. The older you are, the higher your h -index, even in the absence of new papers. The h -index varies by field: life scientists top out at 200; physicists at 100 and social scientists at 20–30 (ref. 8 ). It is database dependent: there are researchers in computer science who have an h -index of around 10 in the Web of Science but of 20–30 in Google Scholar 9 . Reading and judging a researcher's work is much more appropriate than relying on one number. Even when comparing large numbers of researchers, an approach that considers more information about an individual's expertise, experience, activities and influence is best.
8) Avoid misplaced concreteness and false precision. Science and technology indicators are prone to conceptual ambiguity and uncertainty and require strong assumptions that are not universally accepted. The meaning of citation counts, for example, has long been debated. Thus, best practice uses multiple indicators to provide a more robust and pluralistic picture. If uncertainty and error can be quantified, for instance using error bars, this information should accompany published indicator values. If this is not possible, indicator producers should at least avoid false precision. For example, the journal impact factor is published to three decimal places to avoid ties. However, given the conceptual ambiguity and random variability of citation counts, it makes no sense to distinguish between journals on the basis of very small impact factor differences. Avoid false precision: only one decimal is warranted.
9) Recognize the systemic effects of assessment and indicators. Indicators change the system through the incentives they establish. These effects should be anticipated. This means that a suite of indicators is always preferable — a single one will invite gaming and goal displacement (in which the measurement becomes the goal). For example, in the 1990s, Australia funded university research using a formula based largely on the number of papers published by an institute. Universities could calculate the 'value' of a paper in a refereed journal; in 2000, it was Aus$800 (around US$480 in 2000) in research funding. Predictably, the number of papers published by Australian researchers went up, but they were in less-cited journals, suggesting that article quality fell 10 .
10) Scrutinize indicators regularly and update them. Research missions and the goals of assessment shift and the research system itself co-evolves. Once-useful metrics become inadequate; new ones emerge. Indicator systems have to be reviewed and perhaps modified. Realizing the effects of its simplistic formula, Australia in 2010 introduced its more complex Excellence in Research for Australia initiative, which emphasizes quality.
Abiding by these ten principles, research evaluation can play an important part in the development of science and its interactions with society. Research metrics can provide crucial information that would be difficult to gather or understand by means of individual expertise. But this quantitative information must not be allowed to morph from an instrument into the goal.
The best decisions are taken by combining robust statistics with sensitivity to the aim and nature of the research that is evaluated. Both quantitative and qualitative evidence are needed; each is objective in its own way. Decision-making about science must be based on high-quality processes that are informed by the highest quality data.
Wouters, P. in Beyond Bibliometrics: Harnessing Multidimensional Indicators of Scholarly Impact (eds Cronin, B. & Sugimoto, C.) 47–66 (MIT Press, 2014).
Google Scholar
Shao, J. & Shen, H. Learned Publ. 24 , 95–97 (2011).
Article Google Scholar
Seglen, P. O. Br. Med. J. 314 , 498–502 (1997).
Article CAS Google Scholar
Garfield, E. J. Am. Med. Assoc. 295 , 90–93 (2006).
López Piñeiro, C. & Hicks, D. Res. Eval. 24 , 78–89 (2015).
van Raan, A. F. J., van Leeuwen, T. N., Visser, M. S., van Eck, N. J. & Waltman, L. J. Informetrics 4 , 431–435 (2010).
Waltman, L. et al. J. Am. Soc. Inf. Sci. Technol. 63 , 2419–2432 (2012).
Hirsch, J. E. Proc. Natl Acad. Sci. USA 102 , 16569–16572 (2005).
Article ADS CAS Google Scholar
Bar-Ilan, J. Scientometrics 74 , 257–271 (2008).
Butler, L. Res. Policy 32 , 143–155 (2003).
Download references
Author information
Authors and affiliations.
Diana Hicks is professor of public policy at the Georgia Institute of Technology, Atlanta, Georgia, USA.,
Diana Hicks
Paul Wouters is professor of scientometrics and director, Ludo Waltman is a researcher, and Sarah de Rijcke is assistant professor, at the Centre for Science and Technology Studies, Leiden University, the Netherlands.,
Paul Wouters, Ludo Waltman & Sarah de Rijcke
Ismael Rafols is a science-policy researcher at the Spanish National Research Council and the Polytechnic University of Valencia, Spain.,
Ismael Rafols
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Diana Hicks .
Related links
Related links in nature research.
The focus on bibliometrics makes papers less useful 2015-Jan-13
Bibliometrics: Is your most cited work your best? 2014-Oct-29
Publishing: Open citations 2013-Oct-16
Referencing: The reuse factor 2013-Oct-16
Nature special: Science metrics
Nature special: Impact
Nature Outlook: Assessing science
Related external links
Spanish and Chinese translations of the Leiden Manifesto
Rights and permissions
Reprints and permissions
About this article
Cite this article.
Hicks, D., Wouters, P., Waltman, L. et al. Bibliometrics: The Leiden Manifesto for research metrics. Nature 520 , 429–431 (2015). https://doi.org/10.1038/520429a
Download citation
Published : 22 April 2015
Issue Date : 23 April 2015
DOI : https://doi.org/10.1038/520429a
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
A novel methodological approach to participant engagement and policy relevance for community-based primary medical care research during the covid-19 pandemic in australia and new zealand.
- Katelyn Barnes
- Sally Hall Dykgraaf
- Felicity Goodyear-Smith
Health Research Policy and Systems (2024)
Mapping the landscape of research on insulin resistance: a visualization analysis of randomized clinical trials
- Sa’ed H. Zyoud
Journal of Health, Population and Nutrition (2024)
More Transparency is Needed When Citing h-Indexes, Journal Impact Factors and CiteScores
- Graham Kendall
Publishing Research Quarterly (2024)
Rescaling the disruption index reveals the universality of disruption distributions in science
- Alex J. Yang
- Hongcun Gong
- Sanhong Deng
Scientometrics (2024)
Research assessment under debate: disentangling the interest around the DORA declaration on Twitter
- Enrique Orduña-Malea
- Núria Bautista-Puig
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.


Social Indicators Research
An International and Interdisciplinary Journal for Quality-of-Life Measurement
Founded in 1974, Social Indicators Research is a leading journal for research on quality of life. A long-standing focus is the measurement of well-being and quality of life (and related concepts), encompassing studies that offer insights via novel application of existing indicators as well as generation and validation of new approaches. The journal welcomes research that investigates people’s quality of life by identifying ‘factors’ (situations, initiatives, characteristics, processes, etc.) that contribute to higher or lower quality of life. The engagement with quality of life in a broad sense is complemented by interest in studies that consider well-being in various relevant domains (work, family, places/communities, politics, etc.), as well as proposals for new methods for analysis and measurement of social phenomena and their transformation in accordance with economic, political, and sociological theories.
This is a transformative journal , you may have access to funding.
- David Bartram

Latest issue
Volume 174, Issue 2
Latest articles
Where you sit is where you stand: perceived (in)equality and demand for democracy in africa.
- Thomas Isbell

An Extended Family Perspective on Intergenerational Human Capital Transmission in China

SDG Impact Index with Double Materiality Perspective: Evidence from OECD Commercial Bank Industry
- Ozlem Kutlu Furtuna
- Evrim Hacioglu Kazak

An Evaluation of the Impact of the Pension System on Income Inequality: USA, UK, Netherlands, Italy and Türkiye
- Can Verberi
- Muhittin Kaplan
Machine Learning-Facilitated Policy Intensity Analysis: A Proposed Procedure and Its Application

Journal updates
Towards the next fifty years of social indicators research: some guidance for authors.
Please refer to the recently published editorial by the Editors of Social Indicators Research highlighting their focus and detailed guidance on how they evaluate manuscripts: Towards the Next Fifty Years of Social Indicators Research: Some Guidance for Authors
Supporting the Sustainable Developmental Goals
Journal information
- Australian Business Deans Council (ABDC) Journal Quality List
- CAB Abstracts
- Current Contents/Social & Behavioral Sciences
- Engineering Village – GEOBASE
- Google Scholar
- OCLC WorldCat Discovery Service
- Research Papers in Economics (RePEc)
- Social Science Citation Index
- TD Net Discovery Service
- UGC-CARE List (India)
Rights and permissions
Editorial policies
© Springer Nature B.V.
- Find a journal
- Publish with us
- Track your research
- Search Menu
- Sign in through your institution
- Advance articles
- Author Guidelines
- Submission Site
- Open Access
- Why Publish?
- About Science and Public Policy
- Editorial Board
- Advertising and Corporate Services
- Journals Career Network
- Self-Archiving Policy
- Dispatch Dates
- Journals on Oxford Academic
- Books on Oxford Academic

Article Contents
1. introduction, 2. quantifying research excellence for policy purposes, 3. methodology, 4. meanings, metrics, processes, and reimagination, 5. discussion, 6. final remarks, acknowledgements.
- < Previous
Research excellence indicators: time to reimagine the ‘making of’?
- Article contents
- Figures & tables
- Supplementary Data
Federico Ferretti, Ângela Guimarães Pereira, Dániel Vértesy, Sjoerd Hardeman, Research excellence indicators: time to reimagine the ‘making of’?, Science and Public Policy , Volume 45, Issue 5, October 2018, Pages 731–741, https://doi.org/10.1093/scipol/scy007
- Permissions Icon Permissions
In the current parlance of evidence-based policy, indicators are increasingly called upon to inform policymakers, including in the research and innovation domain. However, few studies have scrutinized how such indicators come about in practice. We take as an example the development of an indicator by the European Commission, the Research Excellence in Science & Technology indicator. First, we outline tensions related to defining and measuring research excellence for policy using the notion of ‘essentially contested concept’. Second, we explore the construction and use of the aforementioned indicator through in-depth interviews with relevant actors and the co-production of indicators, that is the interplay of their making vis-à-vis academic practices and policy expectations. We find that although many respondents in our study feel uncomfortable with the current usage of notions of excellence as indicator of quality of research practices, few alternatives are suggested. We identify a number of challenges which may contribute to the debate of indicator development, suggesting that the making of current indicators for research policy in the EU may be in need of serious review.
When it comes to research policy, excellence is on top of the agenda. Yet, the meaning attributed to the notion of excellence differs markedly among both academics and policymakers alike.
There is an extensive scholarly debate around the breadth and depth of the meaning of excellence, its capacity to provide quantitative assessments of research activities and its potential to support policy choices. Yet, there is a considerable agreement that it strongly influences the conduction of science. The contentedness of the excellence concept can be derived from the discomfort it has evoked among scholars, leading some even to plea for an altogether rejection of the concept (Stilgoe 2015). The discomfort with the concept is higher whenever proposals are made to measure it. The critique of measuring excellence follows two lines. One is technical and emphasises the need for methodological rigour. While in principle not denying the need for and the possibility of designing science and technology indicators, this line of criticism stresses the shortcomings of methodological approaches used up until now (Grupp and Mogee 2004; Grupp and Schubert 2010 ). The other critique is more philosophical and, while not denying the theoretical and political relevance of excellence, it takes issue with the use of current metrics in assessing it ( Weingart 2005 ; Martin 2011 ; Sørensen et al. 2015 ). Notwithstanding these criticisms though, and especially given the period of science professionalization where policymaking finds itself in ( Elzinga 2012 ), these same metrics are frequently called upon to legitimate policy interventions (Wilsdon et al. 2015).
In addition, highly reflected shortcomings in the existing mechanisms for science’s quality control system, undermine trust in assessment practices around scientific excellence—in other words, if the peer review system is in crisis, what research outcomes are evaluated as excellent? (See Martin 2013 ; Sarewitz 2015 ; Saltelli and Funtowicz 2017 .)
The aspiration for an ‘evidence-based society’ ( Smith 1996 ) requests that policy makers and alike, especially those operating at the level of transnational governmental organisations, rely on information on the current state of research to identify policy priorities, or to allocate funds. Indicators are typically proposed as tools catering this need ( Saltelli et al. 2011 ). A main issue holds, however: how to come up with indicators of research excellence in the face of its often controversial underpinnings, as well as their situated nature?
At the Joint Research Centre of the European Commission, we have been actively involved in the design and construction of a country-level indicator of excellence, the Research Excellence Science & Technology indicator (RES&T) offered and used by the European Commission (cf. European Commission 2014 ; Hardeman et al. 2013 ). Hence we are in a unique position to critically reflect upon challenges of quantifying research excellence for policy purposes.
Here we adopt the notion of essentially contested concept as our theoretical work horse ( Gallie 1955 ; Collier et al. 2006 ) to discuss why the usefulness of research excellence for policy purposes is a subject of contention and what this means for its quantification. Essentially contested concepts are concepts ‘the proper use of which inevitably involves endless disputes about their proper uses on the part of their users’ ( Gallie 1955 : 169).
The work presented in this article revolves around two questions which evolved with the learning through the empirical material: First, we examine whether research excellence can be ‘institutionalised’ in the form of stable research excellence indicators, from the vantage point of Gallie’s notion of ‘essentially contested concept’. Second, whether the re-negotiation of meanings of research excellence that underpin current indicators revolves around the articulation of different imaginaries of excellence displayed by different actors. These initial questions were reframed with the progressive understanding of the authors that the focus in the practices were certainly relevant but larger questions emerged, such as whether ‘excellence’ alone was indeed the relevant descriptor to evaluate quality of research in the EU. Hence, this discussion is also offered vis-à-vis our findings throughout the research process.
The article starts by looking into the notion of excellence and its function as a proxy for scientific quality using the notion of essentially contested concept as well as elements of tension around its conceptualization (Section 2) as reported in the literature. It proceeds with describing briefly the development of the indicator that we are taking as an example to respond to the research questions described earlier. The second part of the article explains the methodology applied (Section 3) and the outcomes (Section 4) of the empirical research carried out to inform this article, which consisted of a number of in-depth interviews with relevant actors, that is developers of the RES&T indicator, EU policymakers, and academics. The interviews aimed at exploring meanings, challenges, and ways to reimagine the processes behind indicators development. In those interviews, we explore ‘re-imagination’ as a space for our interviewees to reflect further and discuss alternatives to current research indicators frameworks. These are offered in a discussion (Section 5) of current challenges to reimagine an indicator to qualify quality in science.
2.1 Measuring and quantifying indicators-for-policy
The appeal of numbers is especially compelling to bureaucratic officials who lack a mandate of popular election or divine right; scientific objectivity thus provides an answer to a moral demand for impartiality and fairness; is a way of making decisions without seeming to decide. (T. M. Porter 1995)
Indicators seek to put into numbers phenomena that are hard to measure ( Boulanger 2014 ; Porter 2015 ). Therewith, measuring is something else than quantifying ( Desrosieres 2015 ): while measuring is about putting into numbers something that already exists, quantifying is about putting into numbers something that requires an interpretative act. Indicators are often exemplary of quantifications. They are desirable because they offer narratives to simplify complex phenomena and therewith attempt to render them comprehensible ( Espeland 2015 ). Such simplifications are especially appealing whenever information is called for by policymakers operating at a distance from the real contexts that is, the actual purpose of their policy action. Simplification means that someone decides which aspects of complex phenomena are stripped away while others are taken on board. The (knowledge and values) grounds for that operation are not always visible. The risk is that, in stripping away some aspects (and focusing on others), a distorted view on the phenomenon of interest may arise, with potentially severe consequences for policy decisions derived from them. Lacking the opportunity to gather detailed information on each and every aspect of a phenomenon of concern, policymakers are nevertheless drawn to indicators offering them the information needed in the form of summary accounts ( Porter 2015 ).
Constructing an indicator on research excellence typically involves activities of quantification as research excellence has no physical substance in itself. For an indicator on research excellence to come into existence one first needs a meaning and understanding about what ‘research excellence’ is about before one can even start assigning numbers to the concept ( Barré 2001 ). We find that the notion of ‘co-production’ ( Jasanoff 2004 ) is relevant as it makes visible that indicators are not developed in a vacuum but respond and simultaneously normalise scientific practice and policy expectations.
2.2 Research excellence as an essentially contested concept
Research excellence could be straightforwardly defined as going beyond a superior standard in research ( Tijssen 2003 ). However, straightforward and intuitively appealing as this definition may seem, it merely shifts the issue of defining what is meant by research excellence towards what counts as ‘a superior standard in research’. For one thing, it remains unclear what should be counted as research to begin with, as well as how standards of superiority should be set, on which account and by whom. Overall, the notion of research excellence is potentially much more controversial than it might seem at first. In fact, whenever it comes to articulating what should count as excellent research and why this is so, scientific communities systematically strive for coming to an agreement ( Lamont 2009 ).
One way to conceive of research excellence then, is to think of it as an essentially contested concept . The notion of essentially contested concept was first introduced by Gallie (1955) to describe cases, that is ideas or phenomena that are widely appraised but controversial at the same time. In substantiating his view, Gallie (1955) listed five properties of essentially contested concepts (see also: Collier et al. 2006 ). Essentially contested concepts are (1) appraisive , (2) internally complex, (3) describable in multiple ways, (4) inherently open, and (5) recognized reciprocally among different parties ( Gallie 1955 ). Due to their complex, open and value-laden nature, essentially contested concepts cannot be defined in a single-best, fixed, and objective way from the outset. Hence, they are likely to produce endless debates on their interpretation and implications.
Research excellence might well serve as an instance of an essentially contested concept. First, research excellence, by its very appeal to superior standards, evokes a general sense of worth and, therewith, shareability . Although one can argue about its exact definition and the implications that such definitions could have, it is hard to be against excellence altogether (Stilgoe 2015). Second, research excellence is likely to be internally complex as it pertains to elements of the research enterprise that need not be additive in straightforward ways.
For example, research excellence can be about process as well as outcomes, whereby the former need not automatically transform into the latter ( Merton 1973 ). Third, it follows that research excellence can be described in multiple ways: while some might simply speak of research excellence with reference to science’s peer review system ( Tijssen 2003 ), others prefer to broaden the notion of research excellence beyond its internal value system to include science’s wider societal impact as well (Stilgoe 2015). Fourth, what counts as excellent research now might not necessary count as excellent research in the future, and any definition of research excellence might well be subject to revision. Finally, the fact that one can have a different view on what research excellence is or should be, is agreed upon by proponents of different definitions. Ultimately, proponents of a particular notion of research excellence could or could not be aware of alternative interpretations.
Recently, Sir Keith Bernett (2016) argued that a mechanical vision of academia is driving ‘mechanical and conventional ways we think about “excellence”. We measure a community of scholars in forms of published papers and league tables’ (Bernett 2016). Hence, what counts as excellence is entertained by the imagination of some about what ‘excellent research’ is; but what, political, social, and ethical commitments are built into the adopted notion and the choice of what needs to be quantified?
2.3 Quantifying research excellence for policy purposes: critical issues
Following the previous discussion, if one acknowledges research excellence as an essentially contested concept, the construction of indicators faces difficulties, which start with the mere act of attempting quantification, that is agreeing on a shared meaning of research excellence. In the 1970s Merton (1973 : 433–435) introduced three questions that need to be addressed to come to terms with the notion of research excellence (see also: Sorensen et al. 2015).
First, what is the basic unit of analysis to which research excellence pertains? Merton (1973) suggested that this could be everything ranging from a discovery, a paper, a painting, a building, a book, a sculpture, a symphony, a person’s life work, or an oeuvre. There is both a temporal, as well as a socio-spatial dimension to the identification of a unit for research excellence. Temporal in the sense that research excellence does not need to be attributable to a specific point in time only but might span across larger time periods. Also, though not so much discussed by Merton (1973) , a unit for research excellence also has a socio-spatial dimension. Research excellence might pertain to objects (books, papers, sculptures, etc.) or people. When it comes to the latter a major issue holds to whom excellence can be attributed (individuals, groups, organisations, territories) and how to draw appropriate boundaries among them (cf. Hardeman 2013 ). Expanding or restricting a unit’s range in time and/or space effects the quantification of research excellence accordingly.
Second, what qualities of research excellence are to be judged? Beyond the identification of an appropriate unit of analysis, the second issue raised by Merton (1973) points out several concerns. One is about the domain of research itself. As with disputes about science and non-science ( Gieryn 1983 ), demarcating research from non-research is more easily said than done. Yet, to attribute excellence to research, such boundary work needs to be done nevertheless. Should research excellence, as in the article Republic of Science (Polanyi 1962) be judged according to its own criteria? Or should research, in line with Weinberg’s (1962) emphasis on external criteria, be judged according to its contribution to society at large? To the same extent of setting the unit of excellence, setting the qualities in one way (and not another) produce certainly different outcomes for the policies derived therefrom. That said, focusing on a particular notion of excellence (i.e. using a particular set of qualities) might crowd out other—in principle equally valid—qualities ( Rafols et al. 2012 ; Sorensen et al. 2015).
Third, who shall judge? For example, a researcher working in a public lab might have a whole different idea on what counts as excellent research than one working in a private lab. This brings Stilgoe (2015) to argue that ‘“Excellence” tells us nothing about how important the science is and everything about who decides’. it is undoubtedly of eminent importance to determine the goals and interests that excellence serves. Likewise, and in line with Funtowicz and Ravetz’s (1990) focus on fit-for-purpose to describe the quality of a process or product, the quality of an indicator of research excellence crucially depends on its use. One concern here is that research excellence indicators might set the standard of research practices that do not conform to the underlying concept of excellence they seek to achieve ( Hicks 2012 ; Sorensen et al. 2015). For example, in Australia, in seeking to achieve excellence, the explicit focus on publication output indeed increased the number of papers produced but left the issue of the actual worth of those ‘unaddressed’ papers (Butler 2003). Interestingly, in 2009 a new excellence framework came into existence in Australia to replace the former quality framework. While the latter made use of a one-size-fits-all model, the new excellence based one presents a matrix approach in which entire sets of indicators, as well as the experts’ reviews coexist as measures of quality. Again, any definition of research excellence and its implications for quantification need to be positioned against the background of the goals and interests it serves.
2.4 The construction of the Research Excellence Indicator (RES&T) at the Joint Research Centre
The development of the Research Excellence Indicator (RES&T) at the Joint Research Centre of the European Commission (JRC) inspired this research. Its history, developments, and our privileged position of proximity to its developments motivate the basis from which we departed to conduct our inquiries.
In 2011, an expert group on the measurement of innovation set up by the European Commission’s Directorate-General Research and Innovation (DG-RTD) was requested ‘to reflect on the indicators which are the most relevant to describe the progress to excellence of European research’ ( Barré et al. 2011 : 3). At that point the whole notion of excellence was said to be ‘in a rather fuzzy state’ ( Barré et al. 2011 : 3). To overcome the conceptual confusion surrounding research excellence and to come up with a short list of indicators capable of grasping research excellence, the expert group proceeded in four steps. First, they defined and described types of activities eligible for being called excellent. Second, a set of potential indicators were identified. Third, from this set of potential indicators a short list of (actually available) indicators was recommended. And fourth, a process for interpreting research excellence as a whole at the level of countries was proposed.
This was followed by Vertesy and Tarantola (2012) proposing ways to aggregate the set of indicators identified by the expert group into a single composite index measuring research excellence. The index closely resembled the theoretical framework offered by the expert group while aiming for statistical soundness at the same time.
Presented at a workshop organised in Ispra (Italy) during fall 2012 by the European Commission and attended by both policymakers and academic scholars, the newly proposed composite indicator met with fierce criticism. A first critique raised was that the proposed composite indicator mixed up both inputs and outputs while research excellence, according to the critiques, should be about research outputs only. Whereas the outcomes of research and innovation activities are fundamentally uncertain, the nature and magnitude of research and innovation inputs say little to nothing about their outputs. A second critique raised during the workshop was that some of the indicators used, while certainly pertaining to research, need not say much about their excellent content. Focusing on outputs only, would largely exclude other dimensions that could refer to any kind of input (e.g. gross investment in R&D) or any kind of process organizing the translation of inputs into outputs (e.g. university–industry collaborations).
Taking these critiques on board, the research excellence indicator was further refined towards the finalization of the 2013 report ( Hardeman et al. 2013 ). First, the scope of the indicator was made explicit by limiting it to research in science and technology only. Second, following upon the critique strongly to distinguish inputs from outputs, it was put clear which among underlying indicators were primarily focused on outputs. Given that the underlying indicators were not available for all countries, the rankings presented in the 2013 Innovation Union Competitiveness Report was based on a single composite indicator aggregating either three (non-ERA countries) or four (ERA countries) underlying indicators (European Commission 2013).
In a subsequent report aimed at refining the indicator, Hardeman and Vertesy (2015) addressed a number of methodological choices, some of which were also pointed out by Sørensen et al. (2015) . These concerned the scope of coverage in terms of the number and kind of countries and the range of (consecutive) years, the variables included (both numerators and denominators), and the choice of weighting and aggregating components. The sensitivity and uncertainty analyses highlighted that some of the methodological choices were more influential than others. While these findings highlighted the importance of normative choices, such normative debates materialized only within a limited arena.
Based on our research and experience with the RES&T, we will discuss whether careful reconsideration of the processes by which these types of indicators are developed and applied is needed.
A qualitative social research methodology is adopted to gain insights from different actors’ vantage point on concepts, challenges, and practices that sustain the quantification of research excellence.
A series of in-depth interviews was carried out by two of the authors of this paper between March and May 2016. A first set of interviews was conducted with five people directly involved in the construction of the RES&T indicator from the policy and research spheres, or people that were identified through our review of relevant literature. This was followed by a second set of interviews partially suggested by the interviewees in the first set. Hence, eleven telephone semi-structured in-depth interviews were conducted with experts, scholars, and users concerned with research indicators and metrics.
This was followed by a second set of interviews (six participants), partially suggested by the interviewees in the first set. This second set was thus composed of senior managers and scholars of research centres with departments on scientometrics and bibliometrics, as well as policymakers.
Hence, the eleven interviewees included people that were either involved in different phases of the RES&T indicator development or were professionally close (in research or policy areas) to the topic of research indicators and metrics. Awareness of the RES&T indicator constituted a preferable requirement. The eleven telephone semi-structured in-depth interviews conducted with the experts, scholars, and users of indicators may seem numerically little; however, this pool offered relevant insights to shed light on the practices of research evaluation in the EU. So, the interviewees were the relevant actors for our work.
We performed coding as suggested by Clarke (2003) as soon as data were available and such an approach allowed us setting more focus on some aspects of the research that emerged as particularly important. The accuracy of our interpretations was checked through multiple blind comparisons of the coding generated by the authors of this paper. Often our codes have also explicitly been verified with the interviewees to check potential misalignments in the representativeness of our interpretations.
RES&T indicator developers (hereafter referred to as ‘developers’) The three interviewees of this group were all somehow involved in the design and implementation of the RES&T indicator. Among them, two senior and one retired researchers, all of them active in the areas of innovation and statistics. Given that we knew two of the interviewees before the interview, we paid particular attention to the influence of the interviewer–interviewee identities at the moment of data analysis, along the recommendations of Gunasekara (2007) .
Policy analysts (hereafter referred to as ‘users’) This group was composed of four senior experts, who are users of research indicators. They are active as policymakers at the European Commission; they all have been involved in various expert groups and at least two of them have also published own research.
Practitioners and scholars in relevant fields for our endeavour concerned with science and technology indicators and active at different levels in their conceptualization, use and construction (hereafter referred to as ‘practitioners’) This group was composed of four scholars (one senior researcher, one full professor, one department director, and one scientific journal editor in chief) who critically study statistical indicators.
Insights into meanings of excellence.
Critical overview of current metrics in general and processes and backstage dynamics in the development of the RES&T indicator (applicable if the interviewee was personally involved).
Reimagination of ways to assess and assure the quality of processes of indicators development, taking stock of transformations of knowledge production, knowledge governance, and policy needs (new narratives).
All interviews, which were in average one hour long, have been transcribed and data analysis was conducted according the principles of grounded theory, particularly as presented in Charmaz (2006) . The analysis of these interviews consisted of highlighting potential common viewpoints, identifying similar themes and patterns around the topics discussed with the interviewees, which will be discussed in the next sections of this article.
In this section, we attempt to make sense of the issues raised by our interviewees, summarising the main recurrent elements of the three main axes that were at the core of the questionnaire structure: (1) meanings of ‘excellence’, (2) challenges backstage processes of developing and using research excellence indicators, (3) ways to reimagine the process of indicator development to promote better quality frameworks to assess scientific quality.
4.1 On meanings of research excellence
Many of us are persuaded that we know what we mean by excellence and would prefer not to be asked to explain. We act as though we believe that close inspection of the idea of excellence will cause it to dissolve into nothing. ( Merton 1973 : 422)
Our starting question to all interviewees was ‘please, define research excellence’. To this question, our interviewees found themselves rather unprepared, which could suggest that either this expression is taken for granted and not in need of reflection or—as the literature review shows—no shared definition seems to exist, to which, in the end, our interviewees largely agree. Such unpreparedness seems somehow paradoxical as it implies an assumption that the definition of excellence is stable, in no need for reflection, whereas our interviewees’ responses seem to suggest rather the contrary. Excellence is referred to as ‘hard to define’, ‘complex’, ‘ambiguous’, ‘dynamic’, ‘dangerous’, ‘tricky’ as well as, a ‘contextual’ and ‘actor-dependent’ notion. The quotes below reflect different vantage points, indicating some agreement on its multidimensional, contested, distributed, situated, and contextual nature:
[…] this is a dangerous concept, because you have different starting positions . Developer 3 Clearly, excellence is multi-dimensional. Secondly, excellence ought to be considered in dynamic terms , and therefore excellence is also dynamics, movement and progress which can be labelled excellent. Third, excellence is not a natural notion in the absolute, but it is relative to objectives . Therefore, we immediately enter into a more complex notion of excellence I would say, which of course the policy makers do not like because it is more complicated. Developer 2 […] you need to see the concept of research excellence from different perspectives . For universities it might mean one thing, for a private company it might mean something completely different. Developer 1 You could say that excellence is an emergent property of the system and not so much an individual attribute of particular people or groups . Stakeholder 1
The quotes suggest agreement among the interviewees that research excellence is a multidimensional, complex, and value-laden concept which link well with the notion of essentially contested concept introduced earlier. While some experts simply think of highly cited publications as the main ingredient for a quantification of excellence, others tend to problematize the notion of excellence once they are invited to carefully reflect upon it, getting away from the initial official viewpoint. Indeed, the lack of consensus about meanings of excellence is highlighted by different interviewees, and, not surprisingly, seem to be a rather important issue at the level of institutional users and developers, who described it as an unavoidable limitation. For example:
It is extremely difficult to have a consensus and [therefore] it is impossible to have a perfect indicator. User 2 I do see that there was no clear understanding of the concept [of excellence] [since] the Lisbon agenda. This partly explains why [a] high level panel was brought together [by DG RTD], [whose] task was to define it and they gave a very broad definition, but I would not identify it as the Commission’s view . Developer 3
The way users and developers responded to this lack of consensus seems to be different though. Developers, on the one hand, do not seem to take any definition of research excellence for granted. It seems that, as a way out of the idea that research excellence constitutes an essentially contested concept, developers stick to a rather abstract notion of research excellence: specific dimensions, aggregation methods, and weights are not spelled out in detail. For example, when asked to define excellence, one developer responded:
I would say there is a natural or obvious standard language meaning , which is being in the first ranks of competition. Excellence is coming first. Now, we know that such a simple definition is not very relevant [for the task of indicators making]. Developer 2
The more concrete, and perhaps more relevant decisions are therewith avoided, as it is immediately acknowledged that research excellence constitutes an essentially contested concept. Users, on the other hand, seem to take for granted established definitions much easier. Here, one interviewee simply referred to the legal basis of Horizon 2020 in defining excellence:
I think I would stick to the definition of the legal basis : what is important is that the research that is funded is the top research. How is this defined? In general, it is what is talented, looking for future solutions, preparing for the next generation of science and technology, being able to make breakthroughs in society. 1 User 3
What both developers and users share is their insistence on the need for quantification of research excellence, albeit for different reasons. From the user-perspective, the call for a research excellence indicator seems to be grounded in a desire for evidence-based policy (EBP) making.
To our question on whether excellence is the right concept for assessing quality in science, interviewees responded saying that the call for EBP all costs surely plays a fundamental role in the mechanisms of promotion of excellence measures and therefrom indicators development:
There is a huge debate on what the real impact of that is in investment and we need to have a more scientific and evidence-based approach to measure this impact , both to justify the expense and the impact of reform, but also to better allocate spending. User 2
Notwithstanding the difficulty involved in operationalizing a notion of excellence towards indicators, what comes upfront is that no single agreed-upon solution is to be expected from academia when it comes to defining excellence for quantification purposes. This seems to be acknowledged by one of the developers, commenting on the composition of the high-level expert panel that:
You have a bunch of researchers who have a very different understanding of what research excellence would be, and some were selected for this high level panel. I am not aware of any reasoning why specific researchers or professors were selected while others were not. I am sure that if there was a different group, there would have been a different outcome , but this is a tricky thing. Developer 3
As such, similar considerations seem to confirm that the processes behind indicators development, such as the involvement of certain academic communities, potentially influence further conceptualisations of research excellence. These aspects will be discussed in the last section of this article.
4.2 Metrics and processes of research excellence
… the whole indicator activity is a social process, a socio-political process; it is not just a technical process. Developer 2
Indicators and metrics respond and correspond to social and political needs and are not mere technical processes, and this is made visible by different types of tensions identified by our interviewees.
First, the process of quantification of research excellence requires an agreement on its definition. Any definition is neither definitive nor stable, not least because of its contextual dependencies. In the above section, it emerged that what needs to be quantified is substantially contested. However, our interviews show that other at least equally contested dimensions exist, such as methodological (quantification practices), social (involved actors), normative (scientific and policy practices).
In the remainder of this section, we explore through our interviews the production of indicators vis-a-vis their processes and outcomes.
4.2.1 Normativity: who is involved in the design of an indicator?
Indicators clearly require political choices to be made. What needs to be quantified and who decides remains an important question. The normativity aspects remit always to definition issues, social actors of concern and institutional dependencies.
The observation of one of the practitioners resonates with Jack Stillgoe’s provocation that ‘excellence tells us nothing about how important the science is and everything about who decides’. 2
Who decides what excellence is? Is it policy makers, is it the citizen, is it the researchers themselves? Is it absolute or does it depend on the conditions? Does it depend on the discipline? Does it depend on the kind of institution concerned? You see what I mean. Developer 2
A practitioner suggests that the level of satisfaction, and therefore acceptance, of an indicator is primarily defined by its usage:
Who will decide when an indicator is good enough and to what extent? […] The short answer is the users, the people out there who use indicators and also whose careers are affected by indicators, they decide whether it’s good enough. Practitioner 3
These quotes raise different questions related to what we here call ‘normativity’ and ideas of co-production, both in terms of indicators development and usage: first, what are power relations between the actors involved and how can they influence the processes behind indicators? Second, to what extent can these kinds of quantification be deemed unsatisfactory and, ultimately rejected and by whom? Third, in the idiom of co-production, how does research excellence metrics influence research practices in both mainstream knowledge production systems and other emerging systems of knowledge production (namely what is designated as ‘DIY science’, ‘citizen science’, ‘the maker movement’, etc.)?
4.2.2 Inescapable simplifications?
Simplification seems to be an inescapable avenue in any attempt to represent complex concepts with just one number; as it implies inclusion and exclusion of dimensions, it begs the question of responsibility and accountability. In the end of the day, complex systems of knowledge production are evaluated through very limited information. Although we do not want to expand this discussion herein, it is important to point out that when using these scientific tools in realms that will have major implications on systems of knowledge production and governance, the ‘who’ and ‘to whom’ necessarily need careful consideration.
At some point, you need to reduce the complexity of reality . Otherwise you cannot move on. We tend to be in favour of something. The problem is that we have far too many possibilities for indicators […]. In general, we need to take decisions on the basis of a limited amount of information . Practitioner 4 What is the limitation of the index? These were the main issues and dimensions that it was not able to address. I do not know what the most problematic things were. I have seen many questions, which address for instance the choice of a certain indicator, data or denominator and the exclusion or inclusion of an index. I do not know which ones were more important than the others. We ran a number of sensitivity tests, which showed that some of the choices had a more substantial impact on country rankings. You could put the ranks upside down. Developer 3
Different interviewees deem that quantification practices ought to be robust to deviations due to different theoretical assumptions therefrom when specific variables, time periods, weights, and aggregation schemes are varied.
With regards to the RES&T, one user remarked purposeful correction as an issue of major concern for the quantification of research excellence:
Part of [the] alignment [of the RES&T indicator] led to counter-intuitive results, like a very low performance from Denmark, and then we reinstated the previous definition because it led to slightly better results. The definition of results is also important for political acceptance. User 4
As reported in the literature and also emerged throughout our interviews, excellence has been contended as the relevant policy concept to tackle major challenges of measuring impacts of science in society. The two quotes below stress the importance of aiming for indicators that go beyond the mere scientific outputs, suggesting that frameworks of assessment should also encompass other critical issues related to process (e.g. research ethics):
It is OK to measure publications, but not just the number . For instance, also how a certain topic has been developed in a specific domain or has been taken into a wider issue, or any more specific issues, these needs to be tracked as well. User 3 Let’s imagine two research groups: one does not do animal testing, and obtain mediocre results, the other does animal testing and have better results and more publications. How those two very different ethical approaches can be accounted? We should correct excellence by ethics! Developer 1
Our material illustrates several facets of different types of reductionism: first, the loss of multidimensionality as an inevitable consequence of reducing complexity; second, rankings following from indicators sometimes work as drivers and specifications for the production of the indicators themselves; finally, volatility in the results is expected to become an issue of major concern specifically along ever-changing systems of knowledge production (see e.g. Hessels and van Lente 2008 ).
4.2.3 Backstage negotiations
Indicators largely depend on negotiations among actors seeking to implement their own vision and interest. From such a view, research indicators redefine reputation and prioritise funding. This process is depicted as an embedded and inevitable dynamic within indicators production:
[When developing an indicator] you will always have a negotiation process . You will always discuss ‘what you will do in this case’; ‘you would not include that’ or ‘you would do that’; ‘this does not cover it all’. You will always have imperfect and to a certain extent wrong data in whatever indicator you will have . User 1 [Developers] mainly do methodological work. The political decisions on the indicator are taken a bit higher up. Practitioner 3 Many politicians have a very poor view of what actually goes into knowledge production. This is what we have experienced in Europe, The Netherlands and the UK. Give me one number and one A4 with a half page summary and I can take decisions. We need to have some condensation and summarisation, and you cannot expect politicians to deal with all the complexities. At the same time, they must be aware that too poor a view of what knowledge production is, kills the chicken that lays the eggs. Practitioner 1
These quotes seem to suggest that there are ‘clear’ separate roles for those who participate in the production of the indicator and those who are empowered to decide what the final product may look like. In the case of the development of the RES&T indicator, the process of revision and validation of the indicator included a workshop organised by EC policymakers, in which developers and academics were invited to review the indicator’s proposed theoretical framework. The publication of the feasibility study by Barré et al. (2011) was the main input of this workshop; one of the developers that we interviewed remarked the following:
I find it interesting that [at the workshop] also policymakers had their own idea of what it [the indicator] should be. Developer 3
In other words, even if roles seem to be rather defined, in the end of the day indicators respond to predefined political requests. On the other hand, it is interesting to note how this workshop worked as a space for clarifying positions and what the relevant expertise is.
Workshops are interesting in showing the controversies , and even if that is not the case for all indicators, the excellence one has gone through a certain level of peer review, revision and criticism . Even when you want to have an open underpinning, as a commissioning policy body, you’re in a difficult position: how do you select experts? User 2 Although the aim was reviewing and validating, people came up with another set of variables [different from the one proposed by the EG] that should have been taken into consideration. People make a difference and that is clear . Developer 3
Hence, these quotes seem to suggest that indicators are based on selected ‘facts’ of the selected ‘experts’ that are called upon to perform the exercise. The call for evidence-based policy needs to acknowledge this context and carefully examine ‘factual’ promises that cannot be accomplished, which put unnecessary pressures on developers, as well:
You have to understand, we had to consider the request … . They [DG RTD] just wanted a ranking of member states in terms of this kind of excellence concept. This is what they want; this is what we had to deliver within the project. Developer 1
We found two elements intrinsic to negotiation processes behind indicators development: first, different actors (developers vs. policymakers) move in different arenas (academic vs. political) and are moved by different interests; second, power relationships set what needs to be measured which make indicators not much more than mere political devices, coherent with a performative function.
4.3 Reimagining what?
Our interviewees explored practical strategies to deal with the policy need for research quality assessments. As researchers, we had assumed that because of many controversies and expressed discontent, there would be a lot of ideas about novel ways to look into the quality of research. Yet, our empirical material shows that there are no clear alternative proposals to either measuring ‘excellent research’ or to enhance the robustness of indicators, except for small variations. As frequently emerged throughout almost all the interviews, many actors highlighted the necessity of carefully interrogating the very use of excellence as the right proxy to research quality, as in this quote:
The norm of quality in research that you consider valid and others might not consider valid needs to be discussed as well. A debate is possible and is fundamental within indicators. Developer 2
Despite different positions about the controversial underpinnings of research excellence, widely discussed by the majority of interviewees from each of the three categories, none offered slight or indirect suggestions on how to go beyond the issue of quantification of research quality for policy purposes:
When you have evidence based policy, unfortunately, at the moment, almost the only thing that counts is quantitative data. Case studies and evaluation studies are only strong if they have quantitative data. Then you will get into indicators and it is very difficult to get away from it. User 1
This observation summarises an inevitable commitment to quantification: when asked about research excellence, different actors tend to digress around specific implementations and their implications but do not question in a strong manner the overall scope of the indicator as a means to map or ascertain scientific quality. But, quantifications fit the policy (and political) purpose they are meant to support, as suggested in this honest account by one user:
I think the reasoning is very simple. If we want an indicator that fits its purpose, which are political purposes , for policy makers and objective measures, we need to be very clear on what we measure and, as you say, to have the best matching and mismatching between purpose and reality. I think that is the first question. Then we have to deal with the nitty gritty and see how, sorry, nitty gritty is important, whether we can improve statistically what we have. User 2
Hence, in our interviews the narrative of ‘need for quantification’ inevitability persisted despite the recognition of its inherent limitations and misrepresentations. Interviewees focused on the possibility of improving indicators’ resonance with quality research, avoiding oversimplifications and limiting possible unwanted implications. This quote suggests that the limits of known imperfections of indicators can actually help with raising questions, and therefore we suggest that indicators could be viewed as the prompts to enquire further and not answering devices:
The point is that to take into account the fact that an indicator will never satisfy the totality of the issues concerned, my view is that an indicator is fine when it is built carefully, as long as it is then used not only to provide answers but to raise questions . […] for example, the indicator we are talking about is fine only as long as it goes along with the discussion of what it does not cover, of what it may hide or not consider with sufficient attention; or in what sense other types of institution or objectives can be taken into account. Developer 2
Along these lines, the importance of allowing for frequently (re)adjustments of evaluation exercises and practices that sustain research indicators is seen as a major improvement:
I am more interested in making sure that as someone involved in composite indicator development, I get the chance to revisit regularly an index which was developed. I can look around and have some kind of conceptual, methodological or statistical review, or see if it is reflecting the ongoing discussions. I can do this if I have the freedom to choose my research. This is not necessarily the case in settings where research is very politically or policy driven. Developer 1
The issue of data availability is quite relevant, not only because of the quality of the built indicators, but more interestingly because existing datasets determine what can be measured and ultimately give shape to the indicator itself, which is a normative issue tout court :
Many researchers or many users criticize existing indicators and say they are too conservative. [While they are] always criticized, it is difficult to come with new metrics and the traditional ones are very well grounded in statistics. We have a very good database on data metrics and patents, therefore these databases have some gravitational attraction, and people always go back to them. An indicator needs to be based on existing data. These data has to be acknowledged and there needs to be some experience of them and a bit of time lag between the coverage of new developments by data and then the use for developing indicators. User 4
Finally, excellence does not necessarily need to be a comparative concept, and indeed comparisons ultimately rely on a fair amount of de-contextualisation, which imply overlooking scientific (foremost disciplinary) differences of epistemic, ontological, and practical nature. This is recognised by many of our interviewees:
[Excellence] it is not so useful for comparing EU performance to non-European countries, to US and Japan, because they do not have the same components. They do not have ERC grants, for example! User 4 My suspicion is that [excellence] also depends on the discipline! Practitioner 2
Our quest for reimagination stayed mostly confined to discussing the processes of indicators development, with interviewees largely sharing stances on the apparent inevitability of quantification of research excellence for policy purposes. In fact, we are somehow disappointed that the discussion on other ways to describe and map quality in science did not really produce substantial alternatives. However, few points were raised as central to strengthen the robustness of existing indicators: first, evaluation exercises that deploy research indicators should be frequently checked upon and fine-tuned if necessary; second, what is possible to evaluate should not be constrained by existing datasets but other sources of information should be sought, created, and imagined. In any case, available sources of information are not sufficient when one considers the changing nature of current knowledge production and governance modes which today involve a wider range of societal actors and practices (e.g. knowledge production systems appearing outside mainstream institutions).
In this article, we explored the making of a particular ‘research excellence’ indicator, starting from its underlying concept and institutional framing. Below, we summarise our findings through five main points. Together, these may constitute departing points for future debates around alternative evaluation framings, descriptors, and frameworks to describe and map the quality of scientific research in the EU.
5.1 Research excellence: contested concept or misnomer?
Early in this article, we advanced the idea of excellence as an essentially contested concept, as articulated by Gallie (1955) . Our interviews seem to concur with the general idea that the definition of such a concept does not seem to be stable and that there are genuine difficulties (and actual unpreparedness) among interviewees even to come up with a working definition for ‘research excellence’. In most cases, interviewees seem to agree that research excellence is a multidimensional, complex, and value-laden concept whose quantification is likely to end in controversy. ‘Institutionalised’ definitions, which may not necessarily be subject of a thorough reflection, were often given by our interviewees; they repeatedly remarked that each definition depends very much on the actors involved in developing indicators. So, would more extended debate about the meanings and usefulness of the concept to assess and compare scientific research quality be helpful to address some of the current discussions?
5.2 Inescapability of quantification?
The majority of our interviewees had a hard time imagining the assessment of research that is not reliant on quantification . Yet, quantifying or not quantifying research excellence for policy purposes does not seem to be the question, the issue rather revolved around what really needs to be quantified. Is the number of published papers really an indication of excellence? Does paper citation really imply its actual reading? As with classifications ( Bowker and Star 1999 ), indicators of research excellence are both hard to live with and without. The question is how to make life with indicators acceptable while recognising their fallibility. Recognising that quantifying research excellence requires choices to be made, then the values and interests of such choices serve at the neglect of others becomes an important reflection. We would argue that quantifying research excellence is first and foremost a political and normative issue and as such, Merton’s (1973) pertinent question ‘who is to judge on research excellence?’ remains.
The need for quantification is encouraged by and responds to the trend of evidence-based policy. After all, this is a legacy of the ‘modern’ paradigm for policy making which needs to be based on scientific evidence and this, in turn, needs to be delivered in numbers. However, as Boden and Epstein, (2006) remarked, we might be in a situation of ‘policy based evidence’ instead, where scientific research is assessed and governed to meet policy imaginaries of scientific activity (e.g. focus on outcomes such as the number of publications, ‘one size fits all’ approaches to quantification across different scientific fields, etc.). The question then remains, that is, can ideas of qualifying quantifications be developed also in this case?
5.3 The lamppost
In Mulla Nasruddin’s story, the drunken man tries to find under the lamppost the keys he lost. Some of the interviewees suggested that the bottleneck for quantification is existing data. In other words, data availability influences what is possible to quantify: only those parameters for which there are already considerable data, that is those which are easy to count seem to be the ones taken into account. We argue that this type of a priori limitation needs to be reflected upon, not least because knowledge production and the ways in which researchers make visible their work to the public are not confined to academic formats only. Moreover, if one considers the processes by which scientific endeavour actually develops, then we might really need to see outside the lamppost’s light circle. Can we afford to describe and assess ‘excellent research’ exclusively relying on current parameters for which data are already available?
5.4 Drawing hands
In an introductory piece about the co-production idiom, Jasanoff (2004 : 2) says that ‘the ways in which we know and represent the world are inseparable from the ways we choose to live in it’. We concur with the idea that the construction of indicators is a sociopolitical practice. From such a perspective, it becomes clear that knowledge production practices are in turn conditioned by knowledge production assessment practices, exactly as depicted in artist M. C. Escher’s piece Drawing Hands . In other words, whichever ways (research excellence) indicators are constructed, their normative nature contributes to redefining scientific practices. We suggest that the construction of an indicator is a process in which both the concept (research excellence) and its measurements are mutually defined and are co-produced. If an indicator redefines reputation and eligibility for funding, researchers will necessarily adapt their conduct to meet such pre-established standards. However, this understanding is not shared by all interviewees, which suggests that future practice needs to raise awareness of the normativity inherent to the use of indicators.
5.5 One size does not fit all
Indicators necessarily de-contextualize information. Many of our interviewees suggested that other types of information would need to be captured by research indicators; to us this casts doubts about the appropriateness of the use of indicators alone as the relevant devices for assessing research with the purposes of designing policy. What do such indicators tell us about scientific practices across fields and different countries and institutions? The assumption that citation and publication practices are homogenous within different specialties and fields of science has been previously demonstrated as problematic ( Leydesdorff 2008 ), and it is specifically within the policy context that indicators need to be discussed (see e.g. Moed et al. 2004).
The STS literature offers us examples of cultures of scientific practice that warn us that indicators alone cannot be used to sustain policies, but they certainly are very useful to ask questions.
Nowotny (2007) and Paradeise and Thoenig (2013) argued that like many other economic indicators, ‘research excellence’ is promoted at the EU level as a ‘soft’ policy tool (i.e. it responds to benchmarks to compel Member States to meet agreed obligations). But the implied measurements and comparisons ‘at all costs’ cannot be considered ‘soft’ at all: they inevitably trigger unforeseen and indirect incentives in pursuing a specific kind of excellence (see e.g. Martin 2011 ) often based on varied, synthetic and implicit evaluations. In the interviews, stories were told to us, about purposeful retuning of indicators because some countries would not perform as expected when variations to the original indicators were introduced.
If going beyond quantification eventually turns out not being an option at all, at least we should aim for more transparency in the ‘participatory’ processes behind the construction of indicators. To cite Innes’ words ‘the most influential, valid, and reliable social indicators are constructed not just through the efforts of technicians, but also through the vision and understanding of the other participants in the policy process. Influential indicators reflect socially shared meanings and policy purposes, as well as respected technical methodology’ ( Innes 1990 ).
This work departed from the idea that the concept of research excellence is hard to be institutionalised in the form of stable research excellence indicators, because it inevitably involves endless disputes about its usage. Therefore, we expected to find alternative by other imaginaries and transformative ideas that could sustain potential changes. To test these ideas, we examined the RES&T indicator development and its quantification, highlighting that this indicator is developed in a context in which it simultaneously respond to and normalise both scientific practice and policy expectations. We also explored the difficulties of measuring a concept (research excellence) that lacks agreed meanings. The in-depth interviews conducted with relevant actors involved in the development of the RES&T research indicator suggest that, while respondents widely acknowledge intrinsic controversies in the concept and measurement, and are willing to discuss alternatives (what we called ‘re-imagination’), they did not find it easy to imagine alternatives to address research quality for policy purposes. Quantification is hard-wired into practices and tools to assess and assure the quality of scientific research that are further reinforced by the current blind and at-all-costs call for quantified evidence based policy to be applied in twenty-eight different EU Member States. However, suggestions were made to make reimagination a continuous stage of the process of developing excellence assessments, which reminds us of Barré’s agora model ( Barré 2004 ).
To conclude, more than a contested concept, our research lead us to wonder whether ‘research excellence’ could be a misnomer to assess the quality of scientific research in a world where processes, and not only outcomes, are increasingly subject of ethical and societal scrutiny? Or, what is the significance of excellence indicators when scientific research is a distributed endeavour that involves different actors and institutions often even outside mainstream circles?
Conflict of interest statement . The views expressed in the article are purely those of the writers and may not in any circumstances be regarded as stating an official position of the European Commission and Robobank.
The authors would like to thank the contribution of the interviewees, the comments and suggestions of two anonymous reviewers as well as the participants of the workshop on “Excellence Policies in Science” held in Leiden, 2016. The views expressed in the article are purely those of the authors and may not in any circumstances be regarded as stating an official position of the European Commission.
Barré R. ( 2001 ) ‘ Sense and Nonsense of S&T Productivity Indicators ’, Science and Public Policy , 28 / 4 : 259 – 66 .
Google Scholar
Barré R. , ( 2004 ) ‘S&T indicators for policy making in a changing science-society relationship’, in: Moed H. F. , Glänzel W. , Schmoch U. . (eds) Handbook of Quantitative Science and Technology Research: The Use of Publication and Patent Statistics in Studies of S&T Systems , pp. 115–131. Dordrecht : Springer .
Google Preview
Barré R. ( 2010 ) ‘ Towards Socially Robust S&T Indicators: Indicators as Debatable Devices, Enabling Collective Learning ’, Research Evaluation , 19 / 3 : 227 – 31 .
Barré R. , Hollanders H. , Salter A. ( 2011 ). Indicators of Research Excellence . Expert Group on the measurement of innovation.
Benett K. ( 2016 ) ‘Universities are Becoming Like Mechanical Nightingales’. Times Higher education. < https://www.timeshighereducation.com/blog/universities-are-becoming-mechanical-nightingales>
Boden R. , Epstein D. ( 2006 ) ‘ Managing the Research Imagination? Globalisation and Research in Higher Education ’, Globalisation, Societies and Education , 4 / 2 : 223 – 36 .
Boulanger P.-M. ( 2014 ) Elements for a Comprehensive Assessment of Public Indicators . JRC Scientific and Policy Reports, Luxembourg : Publications Office of the European Union .
Bowker G. C. , Star S. L. ( 1999 ) Sorting Things Out: Classification and its Consequences . Cambridge : MIT Press .
Butler L. ( 2003a ) ‘ Explaining Australia’s Increased Share of ISI Publications—the Effects of a Funding Formula Based On Publication Counts ’, Research Policy , 32 : 143 – 55 .
Charmaz K. ( 2006 ) Constructing Grounded Theory: A Practical Guide Through Qualitative Analysis , Vol. 10. http://doi.org/10.1016/j.lisr.2007.11.003
Clarke A. E. ( 2003 ) ‘ Situational Analyses ’, Symbolic Interaction , 26 / 4 : 553 – 76 .
Collier D. , Daniel Hidalgo F. , Olivia Maciuceanu A. ( 2006 ) ‘ Essentially Contested Concepts: Debates and Applications ’, Journal of Political Ideologies , 11 : 211 – 46 .
Desrosieres A. , ( 2015 ) ‘Retroaction: How Indicators Feed Back onto Quantified Actors’. In: Rottenburg . et al. (eds) The World of Indicators: The Making of Governmental Knowledge through Quantification . Cambridge : Cambridge University Press .
Elzinga A. ( 2012 ) ‘ Features of the Current Science Policy Regime: Viewed in Historical Perspective ’, Science and Public Policy , 39 / 4 : 416 – 28 .
European Commission ( 2014 ) Innovation Union Competitiveness Report 2013—Commission Staff Working Document, Directorate-General for Research and Innovation . Luxembourg : Publications Office of the European Union .
Espeland W. ( 2015 ) ‘Narating Numbers’. In: Rottenburg et al. (eds) The World of Indicators: The Making of Governmental Knowledge through Quantification . Cambridge, UK : Cambridge University Press .
Funtowicz S. O. , Ravetz J. R. ( 1990 ) Uncertainty and Quality in Science for Policy , 229 – 41 . Dordrecht : Kluwer Academic Publishers .
Gallie W. B. ( 1955 ) ‘ Essentially Contested Concepts ’, Proceedings of the Aristotelian Society , 56 : 167 – 98 .
Gieryn T. F. ( 1983 ) ‘ Boundary-Work and the Demarcation of Science from Non-science: Strains and Interests in Professional Ideologies of Scientists ’, American Sociological Review , 48 / 6 : 781 – 95 .
Grupp H. , Mogee M. ( 2014 ) ‘ Indicators for National Science and Technology Policy. How Robust are Composite Indicators? ’, Research Policy , 33 / 2004 : 1373 – 84 .
Grupp H. , Schubert T. ( 2010 ) ‘ Review and New Evidence on Composite Innovation Indicators for Evaluating National Performance ’, Research Policy , 39 / 1 : 67 – 78 .
Gunasekara C. ( 2007 ) ‘ Pivoting the Centre: Reflections on Undertaking Qualitative Interviewing in Academia ’, Qualitative Research , 7 : 461 – 75 .
Hardeman S. ( 2013 ) ‘ Organization Level Research in Scientometrics: A Plea for an Explicit Pragmatic Approach ’, Scientometrics , 94 / 3 : 1175 – 94 .
Hardeman S. , Van Roy V. , Vertesy D. ( 2013 ) An Analysis of National Research Systems (I): A Composite Indicator for Scientific and Technological Research Excellence . JRC Scientific and Policy Reports, Luxembourg : Publications Office of the European Union .
Hessels L. K. , van Lente H. ( 2008 ) ‘ Re-thinking New Knowledge Production: A Literature Review and a Research Agenda ’, Research Policy , 37 / 4 : 740 – 60 .
Hicks D. ( 2012 ) ‘ Performance-based University Research Funding Systems ’, Research Policy , 41 / 2 : 251 – 61 .
Innes J. E. ( 1990 ) Knowledge and Public Policy. The Search for Meaningful Indicators . New Brunswick (USA) and London (UK ): Transaction Publishers .
Jasanoff S. (ed.) ( 2004 ) States of Knowledge: The Co-Production of Science and the Social Order . London : Routledge .
Lamont M. ( 2009 ) How Professors Think: Inside the Curious World of Academic Judgment . Cambridge/London : Harvard University Press .
Leydesdorff L. ( 2008 ) ‘ Caveats for the Use of Citation Indicators in Research and Journal Evaluations ’, Journal of the American Society for Information Science and Technology , 59 / 2 : 278 – 87 .
Martin B. R. ( 2011 ) ‘ The Research Excellence Framework and the ‘impact agenda’: are we Creating a Frankenstein Monster? ’, Research Evaluation , 20 / 3 : 247 – 54 .
Martin B. R. ( 2013 ) ‘ Whither Research Integrity? Plagiarism, Self-Plagiarism and Coercive Citation in an Age of Research Assessment ’, Research Policy , 42 / 5 : 1005 – 14 .
Merton R. K. ( 1973 ) ‘Recognition and Excellence: Instructive Ambiguities’. In: Merton R. K. (ed.) The Sociology of Science . Chicago : University of Chicago Press .
Mood H.F. , Glanzel W. , Schmoch U. (eds) ( 2004 ) Handbook of Quantitative Science and Technology Research. The Use of Publication and Patent Statistics in Studies of S&T Systems . Dordrecht : Kluwer .
Nowotny H. ( 2007 ) ‘ How Many Policy Rooms Are There? Evidence-Based and Other Kinds of Science Policies ’, Science, Technology & Human Values , 32 / 4 : 479 – 90 .
Paradeise C. , Thoenig J.-C. ( 2013 ) ‘ Organization Studies Orders and Global Standards ’, Organization Studies , 34 / 2 : 189 – 218 .
Polanyi M. ( 2000 ) ‘ The Republic of Science: Its Political and Economic Theory ’, Minerva , 38 / 1 : 1 – 21 .
Porter T. M. , ( 2015 ) The Flight of the Indicator. In: Rottenburg et al. (eds) The World of Indicators: The Making of Governmental Knowledge through Quantification . Cambridge : Cambridge University Press .
Rafols I. , Leydesdorff L. , O’Hare A. et al. ( 2012 ) ‘ How Journal Rankings Can Suppress Interdisciplinary Research: A Comparison Between Innovation Studies and Business & management ’, Research Policy , 41 / 7 : 1262 – 82 .
Saltelli A. , D’Hombres B. , Jesinghaus J. et al. ( 2011 ) ‘ Indicators for European Union Policies. Business as Usual? ’, Social Indicators Research , 102 / 2 : 197 – 207 .
Saltelli A. , Funtowicz S. ( 2017 ). ‘What is Science’s Crisis Really About?’ Futures —in press. < http://www.sciencedirect.com/science/article/pii/S0016328717301969> accessed July 2017.
Sarewitz D. ( 2015 ) ‘ Reproducibility Will Not Cure What Ails Science ’, Nature , 525 : 159.
Smith A. F. ( 1996 ) ‘ MAD Cows and Ecstasy: Chance and Choice in an Evidence-Based Society ’, Journal-Royal Statistical Society Series A , 159 : 367 – 84 .
Sørensen M. P. , Bloch C. , Young M. ( 2015 ) ‘ Excellence in the Knowledge-Based Economy: from Scientific to Research Excellence ’, European Journal of Higher Education , 1 – 21 .
Stilgoe J. ( 2014 ). ‘Against Excellence’. The Guardian , 19 December 2014.
Tijssen R. J. ( 2003 ) ‘ Scoreboards of Research Excellence ’, Research Evaluation , 12 / 2 : 91 – 103 .
Vertesy D. , Tarantola S. ( 2012 ). Composite Indicators of Research Excellence . JRC Scientific and Policy Reports. Luxembourg : Publications Office of the European Union .
Weinberg A. M. ( 2000 ) ‘ Criteria for Scientific Choice ’, Minerva , 38 / 3 : 253 – 66 .
Weingart P. ( 2005 ) ‘ Impact of Bibliometrics upon the Science System: Inadvertent Consequences? ’, Scientometrics , 62 / 1 : 117 – 31 .
Wilsdon J. ( 2015 ) ‘ We Need a Measured Approach to Metrics ’, Nature , 523 / 7559 : 129 .
The official Horizon2020 document defines that research excellence is about to “[] ensure a steady stream of world-class research to secure Europe's long-term competitiveness. It will support the best ideas, develop talent within Europe, provide researchers with access to priority research infrastructure, and make Europe an attractive location for the world's best researchers. ” (European Commission, 2011) (p.4).
From “Against Excellence”, the Guardian, 19 /12/2014 Retrieved at https://www.theguardian.com/science/political-science/2014/dec/19/against-excellence.
| Month: | Total Views: |
|---|---|
| February 2018 | 2,426 |
| March 2018 | 815 |
| April 2018 | 284 |
| May 2018 | 350 |
| June 2018 | 370 |
| July 2018 | 291 |
| August 2018 | 263 |
| September 2018 | 201 |
| October 2018 | 309 |
| November 2018 | 362 |
| December 2018 | 210 |
| January 2019 | 218 |
| February 2019 | 221 |
| March 2019 | 272 |
| April 2019 | 301 |
| May 2019 | 234 |
| June 2019 | 278 |
| July 2019 | 355 |
| August 2019 | 328 |
| September 2019 | 332 |
| October 2019 | 408 |
| November 2019 | 396 |
| December 2019 | 314 |
| January 2020 | 674 |
| February 2020 | 424 |
| March 2020 | 406 |
| April 2020 | 277 |
| May 2020 | 290 |
| June 2020 | 512 |
| July 2020 | 561 |
| August 2020 | 506 |
| September 2020 | 560 |
| October 2020 | 525 |
| November 2020 | 515 |
| December 2020 | 460 |
| January 2021 | 429 |
| February 2021 | 253 |
| March 2021 | 333 |
| April 2021 | 305 |
| May 2021 | 224 |
| June 2021 | 262 |
| July 2021 | 271 |
| August 2021 | 242 |
| September 2021 | 277 |
| October 2021 | 297 |
| November 2021 | 239 |
| December 2021 | 379 |
| January 2022 | 247 |
| February 2022 | 273 |
| March 2022 | 314 |
| April 2022 | 331 |
| May 2022 | 300 |
| June 2022 | 254 |
| July 2022 | 198 |
| August 2022 | 225 |
| September 2022 | 220 |
| October 2022 | 146 |
| November 2022 | 152 |
| December 2022 | 95 |
| January 2023 | 141 |
| February 2023 | 157 |
| March 2023 | 210 |
| April 2023 | 165 |
| May 2023 | 202 |
| June 2023 | 156 |
| July 2023 | 186 |
| August 2023 | 172 |
| September 2023 | 141 |
| October 2023 | 184 |
| November 2023 | 188 |
| December 2023 | 136 |
| January 2024 | 217 |
| February 2024 | 667 |
| March 2024 | 199 |
| April 2024 | 153 |
| May 2024 | 158 |
| June 2024 | 99 |
| July 2024 | 107 |
| August 2024 | 119 |
| September 2024 | 23 |
Email alerts
Citing articles via.
- Recommend to your Library
Affiliations
- Online ISSN 1471-5430
- Print ISSN 0302-3427
- Copyright © 2024 Oxford University Press
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
- Mailing List
- Get Started
- Editorial Services
- Editorial Packages
- Standard Editorial Package
- Scientific Editorial Package
- Premium Editorial Package
- Platinum Editorial Package
- Publishing Services
- Typesetting & Indexing
- Art/Graphic Management
- Data Conversion
- Open Access Publishing
- Business Enterprise Management System
- Frequently Asked Questions
- Job Opportunities
- Testimonials
What Are Research Indicators and How Do You Use Them?

In the past few years, the field of science policy has seen an increasing emphasis on the “societal value and value for money, performance-based funding and on globalization of academic research.” There has also been a notably growing need for research assessment internally and broad research information systems. During the shift to more dependence on research indicators, the computerization of the research process and moving to social media for academic communication have led to research assessment relying on data metrics. This involves the usage of citation indexes, electronic databases, the repositories of publications, the usage analytics of the publishers’ sites, and other metrics like Google Analytics ( Moed, 2017 ).
According to ASPIRE, a research performance scheme, here are four indicator categories that go into measuring one’s activity and quality of research. The indicator categories include: research income, which measures the monetary value amount in terms of grants and research income, whether private or public; research training, which measures the activity of the research in terms of supervised doctoral completions and supervised master’s research completions, along with measuring the quality of the research in terms of timely supervised doctoral completions (four years or less) and timely supervised master’s research completions (two years or less); research outputs that measure the research activity based on the number of publications (books, book chapters, journal articles, conference papers) and the number of creative works, such as live performances or exhibitions and events (The quality of the research is measured based on the number of ERA-listed citation databases and high-quality creative works determined by an internal peer review process.); and research engagement, which measures the research activity by the number of accepted invention disclosures, granted patents and commercialization income. This indicator measures the quality of the research based on external co-authored or created outputs and external collaboration grants ( Edith Cowan University, 2016 ).

Due to the increasing usage of such indicators, there have been many different measures developed to better understand a research’s impact. For example, one way to look into indicators is by measuring outcomes, such as dollars saved, lives saved, and crashes avoided, and combining them with other outputs. This is the method included in the Research Performance Measures System ( National Academies of Sciences, Engineering, and Medicine, 2008 ).
When deciding what measurement system you would want to go with, there are a few things to consider to make sure you are not depending on the wrong indicators. There are more critiques now of the way indicators are used in assessing research, since indicators may be biased and come short of measuring what they are expected to measure. Also, most studies have a limited time horizon, and that could make some indicators unreliable. In addition, there have been discussions about how indicators may be manipulated and their perceived societal impact being flawed. That is why many believe that using indicators by themselves at the level of the individual and making determinations based on them results in faulty measurements. A valid and just assessment of individual research can only be done properly if there is sufficient background knowledge on the particular role the research played in their publications while also taking into consideration other types of information affecting their performance ( Moed, 2017 ).
Although making a contribution to scientific-scholarly progress is a notion that has a place in history, it is argued that this impact can only be measured in the long term. This is why some current indicators measuring scientific-scholarly contributions may be focused less on actual contributions and more as an indication of “attention, visibility, and short-term impact.” In terms of societal value, it is almost impossible assess in a politically neutral manner. This is because societal value is usually measured based on the policy domain, which makes it hard to be neutral ( Moed, 2017 ).

However, the importance of indicators should not be underestimated because of these factors. Instead, you will need to pay attention to how these influences may change your perception and try to eliminate any biases. For one, an assumption in the usage of indicators to assess academic research has been that it is not the “potential influence or importance of research but the actual influence or impact” that is important for policymakers and researchers. Another bias present in indicators that you can eliminate is the usage of citations as indicators of the importance of the research rather than effective communication strategies. When you shift your perspective to look at citations in this way, it will discourage their usage as a major indicator of importance ( Moed, 2017 ).

With that being said, do not let the shortcomings of the research indicator system stop you from reaping their best qualities. There are many ways you can use these indicators to influence your decisions and better your outcomes. For example, you can use citations as an indicator of your social media presence and if you are effectively getting your work out into the world. Though the specifics of how accurate indicators are is a hotly contested issue, balancing your trust in indicators with some skepticism will result in better outcomes in the future. The only way for you to fully understand these biases and balance your expectations correctly is by looking at different systems and digging into studies about these specific indicators.
Since indicators depend on a wide variety of outcomes, one way to better these outcomes is by maximizing your work’s impact and visibility. You can find some tips about how to go about this process by looking through eContent Pro’s blogs and adding to your research factors, which will result in higher visibility and better outcomes in terms of impact. Also, since indicators rely on citations and other similarly measured factors, you might want to take a look at eContent Pro’s publishing services to see what works best for you in order to ensure that your work gets to the right audience and becomes an important piece of scholarly work in your academic field. Whether it is libraries and open access organizations, university presses and commercial publishing houses, or academic and research individuals, eContent Pro’s services will ensure that your work gets the visibility and recognition it deserves.
As publishing is an important pillar of building a standout research profile, it is paramount to make use of available author services, many of which are available on the eContent Pro’s website . Services such as English Language Copyediting , Scientific and Scholarly Editing , Journal Selection , and many other related services will greatly improve your chances of getting your manuscript accepted into a journal. You will find eContent Pro’s author services to be top quality, turned around exceptionally quickly, and affordably priced. Here are what our satisfied customers are saying about eContent Pro’s Author Services:
“The feedback on the technical content was beyond my expectations as it included additional reference suggestions and questions provoking further thought. The chapter has improved as a result.”
Dr. Sheron Burns, University of the West Indies, Jamaica
“This is not my first experience with eContent Pro. I was extremely pleased with the communication between me and office staff/professionals.”
Dr. Theresa Canada, Western Connecticut State University, USA

- Edith Cowan University. (2016). Research performance analytics. https://intranet.ecu.edu.au/__data/assets/pdf_file/0005/720374/Research-Performance-Analytics.pdf. https://intranet.ecu.edu.au/__data/assets/pdf_file/0005/720374/Research-Performance-Analytics.pdf
- Moed, H. (2017). How can we use research performance indicators in an informed and responsible manner? The Bibliomagician. https://thebibliomagician.wordpress.com/2017/11/03/how-can-we-use-research-performance-indicators-in-an-informed-and-responsible-manner-guest-post-by-henk-moed/
- National Academies of Sciences, Engineering, and Medicine. (2008). ). Performance measurement tool box and reporting system for research programs and projects. The National Academies Press. https://nap.nationalacademies.org/read/23093/chapter/5
Please complete the following form to proceed to the video:
Research Impact Indicators & Metrics
Purpose and benefits, coverage and scope, riim team - contact us.
- Maximize Your Impact
- Apply Metrics Responsibly
- Author Metrics
- Article Metrics
- Journal Metrics
- Book/Chapter Metrics
- Data Metrics
- Open Educational Resource Metrics
Related Guides - RIIM
Open Scholarship & Scholarly Publishing

Welcome to the Research Impact Indicators & Metrics guide, a collection of tools, resources and contextual narrative to help you present a picture of how your scholarship is received and used within your field and beyond. Research is often measured in terms of its impact within an academic discipline (s), upon society or upon economies . As with any raw numbers, impact metrics can be misappropriated and misconstrued. Our goal is to help you select the metrics and tools that most accurately and fully represent your work.
Appropriate indicators applied within context have the benefits of:
- Demonstrating what audiences are reading/using your works
- Demonstrating your work's value for promotion and tenure
- Justifying funding requests
The sections of this guide are designed to help you answer questions such as:
- How can I increase the visibility of my research?
- What are the best ways to portray my research impact?
- What are the top journals in my field ?
- What is the best database to get my H-index ?
- How do I incorporate download counts (& other metrics) into my Tenure & Promotion packet ?
- Who are the top authors in my field (and with whom might I collaborate)?
- How are my grant research outputs performing ?
The tools and resources included here are available freely and publicly or through a Libraries subscription. You may be familiar with or have heard of others, but if you have to pay to use them, we are not talking about them in this guide.
For news, resources and tools, see Open Scholarship & Scholarly Publishing blog posts on impact indicators .
Finally, the focus here is to help individual scholars. Tools and methods for evaluating a department, group or institutional ranking may be related, but they are beyond the scope of this guide.
We welcome your questions about impact metrics and/or your suggestions to improve this guide . Please contact us at [email protected] .
This guide has been developed by a team of librarians:
- Christine Turner, Scholarly Communication Librarian
- Jennifer Chaput, Data Services Librarian
- Melanie Radik, Science and Engineering Librarian
- Rebecca Reznik-Zellen, Head, Science and Engineering Librarian, and
- Sarah Fitzgerald, Assessment and Planning Librarian
- Next: Maximize Your Impact >>
- Last Updated: Jul 3, 2024 10:30 AM
- URL: https://guides.library.umass.edu/Research_Impact
© 2022 University of Massachusetts Amherst • Site Policies • Accessibility

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
Measuring the outcome and impact of research capacity strengthening initiatives: A review of indicators used or described in the published and grey literature
Justin pulford.
1 Department of International Public Health, Liverpool School of Tropical Medicine, Liverpool, L3 5QA, UK
Natasha Price
Jessica amegee quach, imelda bates, associated data.
- Pulford J, Price N, Amegee J, et al.: List of RCS Outcome Indicators.xlsx. Measuring the outcome and impact of research capacity strengthening initiatives: A review of indicators used or described in the published and grey literature - Full listing of retrieved RCS indicators. V1 ed: Harvard Dataverse;2020.
Underlying data
Harvard Dataverse: Measuring the outcome and impact of research capacity strengthening initiatives: A review of indicators used or described in the published and grey literature - Full listing of retrieved RCS indicators. https://doi.org/10.7910/DVN/K6GIGX 18 .
This project contains the following underlying data:
- List of RCS Impact Indicators
- List of RCS Outcome Indicators
- List of RCS Output Indicators
- List of Source Documents
Data are available under the terms of the Creative Commons Zero "No rights reserved" data waiver (CC0 1.0 Public domain dedication).
Peer Review Summary
| Review date | Reviewer name(s) | Version reviewed | Review status |
|---|---|---|---|
| Meriel Flint-O'Kane | Approved | ||
| Francesco Obino and Daniel Fussy | Approved | ||
| Peter Taylor | Approved | ||
| Erica Di Ruggiero | Approved |
Background: Development partners and research councils are increasingly investing in research capacity strengthening initiatives in low- and middle-income countries to support sustainable research systems. However, there are few reported evaluations of research capacity strengthening initiatives and no agreed evaluation metrics.
Methods: To advance progress towards a standardised set of outcome and impact indicators, this paper presents a structured review of research capacity strengthening indicators described in the published and grey literature.
Results: We identified a total of 668 indicators of which 40% measured output, 59.5% outcome and 0.5% impact. Only 1% of outcome and impact indicators met all four quality criteria applied. A majority (63%) of reported outcome indicators clustered in four focal areas, including: research management and support (97/400), the attainment and application of new research skills and knowledge (62/400), research collaboration (53/400), and knowledge transfer (39/400).
Conclusions: Whilst this review identified few examples of quality research capacity strengthening indicators, it has identified priority focal areas in which outcome and impact indicators could be developed as well as a small set of ‘candidate’ indicators that could form the basis of development efforts.
Introduction
Research capacity strengthening (RCS) has been defined as the “process of individual and institutional development which leads to higher levels of skills and greater ability to perform useful research” 1 . National capacity to generate robust, innovative and locally appropriate research is considered essential to population health 2 , 3 and socioeconomic development 4 , 5 . However, wide global disparities in research capacity and productivity currently exist: South Asian countries account for 23% of the World’s population yet produced less than 5% of the global output of scientific publications in 2013 6 ; and sub-Saharan Africa (accounting for 13% of the global population), contributes 1% of global investment in research and development and holds 0.1% of global patents 6 . Accordingly, international development partners and research funding bodies are increasingly investing in RCS initiatives in low- and middle-income countries (LMICs). The UK Collaborative on Development Research predicts the United Kingdom’s total aid spend on research will rise to £1.2 billion by 2021 7 , a large proportion of which would be direct or indirect investment in RCS in LMICs. The total global spend on RCS in LMICs, while not yet calculated, would likely be many times this figure.
Despite this substantial investment, few robust evaluations of RCS initiatives in LMIC contexts have been presented in the published or grey literatures with the available evidence base characterised by reflective, largely qualitative individual case studies or commentaries 8 . RCS evaluation frameworks have been described 9 – 11 , but a comprehensive set of standard outcome or impact indicators have not been agreed and common indicators are used inconsistently. For example, publication count has been used as both an output 12 and outcome indicator 13 sometimes with 14 or without 10 accounting for publication quality.
The dearth of robust RCS programme evaluation and, more fundamentally, robust evaluation metrics available for consistent application across RCS programmes, has contributed to a paradoxical situation in which investments designed to strengthen the quantity, quality and impact of locally produced research in LMIC settings are themselves hindered by a lack of supporting evidence. As a substantial proportion of RCS investment is derived from publicly funded development assistance 15 – 17 , then ensuring the means to reliably evaluate impact and value for money of research and health system investments assumes even further importance.
This paper aims to advance progress towards the establishment of a standardised set of outcome and impact indicators for use across RCS initiatives in LMIC contexts. As a first step towards this goal, a systematic review of RCS outcome and impact indicators previously described in the published and grey literatures is presented. The review findings highlight the range, type and quality of RCS indicators currently available and allows inconsistencies, duplications, overlaps and gaps to be identified. These results may then be used to inform planning and decision making regarding the selection and/or development of standard RCS evaluation metrics. In the interim, the resulting list of indicators may also serve as a useful resource for RCS programme funders, managers and evaluators as they design their respective monitoring and evaluation frameworks.
Search strategy and study selection
Peer reviewed publications were sought via the following databases: PubMed, Global Health, CINAHL Complete and International Bibliography of the Social Sciences (IBSS). The search was limited to English language publications and was conducted using the keywords: (research capacity) AND (develop* OR build* OR strengthen*) AND (indicator) AND (monitoring OR evaluation). The search was conducted without date limitations up until March 2018. Following removal of duplicates, all retrieved publications were subject to an initial review of the title, abstract and listed keywords. Publications that met, or were suggestive of meeting, the inclusion criteria were then subjected to full text review. Publications subjected to full text review met the inclusion criteria if they: were peer-reviewed; pertained to ‘research capacity’ (as either a primary or secondary focus); and included at least one output, outcome or impact indicator that has been used to measure research capacity or was proposed as a possible measure of research capacity.
The search was supplemented by a manual review of the references listed in each paper that met the final inclusion criteria and by a citation search using first author names for all papers which met the final inclusion criteria from both the initial electronic and supplementary manual searches. A further 19 papers which met the inclusion criteria were identified in this way and included in the review.
Relevant grey literature was then sought via the following databases: Google Advanced, BASE, Grey Literature and OpenGrey. The same search terms and inclusion criteria as described above were used. This search was supplemented by a request circulated across the authors’ personal networks for relevant research reports pertaining to RCS evaluation which may fit the inclusion criteria. There were seven reports identified this way, resulting in a final sample of 25 publications and seven reports. Figure 1 depicts the overall process and outcomes from this search strategy.

Data extraction
Research capacity strengthening indicator descriptions and definitions were extracted from each publication/report and recorded verbatim in an Excel spreadsheet (see Underlying data ) 18 . Other information recorded alongside each indicator included: the type of indicator (output, outcome or impact) ( Box 1 ); the level of measurement (individual research capacity; institutional research capacity; or systemic research capacity); source information (author, year and title of publication/report); and a brief summary of the context in which the indicator was applied. Designation of indicator type (output, outcome or impact) and level of measurement (individual, institutional or systemic) were based on those ascribed by the author/s when reported. Where indicator type and measurement level were not reported, we used our own judgement drawing on the reported context from the respective publication/report.
Some publications/reports used the same indicators across different levels (i.e. as both an individual and an institutional measure) and in these cases we reported the indicator at a single level only based on apparent best fit. However, if the same publication reported the same indicator as both an output and an outcome measure, then it was reported twice. Where there was variation between the way that one publication or another classified an indicator (e.g. the same indicator being described as an ‘output’ indicator in one publication and an ‘outcome’ indicator in another), we remained true to the texts and recorded each separately. Indicators that pertained to the evaluation of course materials or content (e.g. how useful were the PowerPoint slides provided?) were excluded from analysis, although indicators that focused on the outcome of course attendance were retained.
Defining output, outcome, and impact indicators
Output indicators - defined as measures of programme or project activities that are directly controllable by the RCS initiative (e.g. number of infectious disease experts from country X training in academic writing).
Outcome indicators - defined as measures of change in behaviour or performance, in the short- to mid-term, that could reasonably be attributed to the RCS initiative in full or large part (e.g. number of manuscripts published by infectious disease experts from country X following an academic writing course).
Impact indicators - defined as measures of longer-term change that may not be directly attributable to the RCS initiative but directly relate to the overarching aims of the RCS initiative (e.g. reduction in infectious disease mortality in country X).
Data analysis
Once all listed indicators from across the 32 publications and reports had been entered into the Excel spreadsheet, the research team coded all outcome and impact indicators according to their respective focus (i.e. the focus of the indicated measure, such as publication count or grant submissions) and quality. Output indicators were excluded from further analysis. Indicators were coded independently by two researchers, checking consistency and resolving discrepancies through discussion and, if necessary, by bringing in a third reviewer. ‘Focus’ codes were emergent and were based on stated or implied focal area of each indicator. ‘Quality’ was coded against four pre-determined criteria: 1) a measure for the stated indicator was at least implied in the indicator description; 2) the measure was clearly defined; 3) the defined measure was sensitive to change; and 4) the defined measure was time-bound (thus, criteria 2 is only applied if criteria 1 is met and criteria 3 and 4 are only applied if criteria 2 is met).
Type and level of identified indicators
We identified a total of 668 reported or described indicators of research capacity from across the 32 publications or reports included in the review. Of these, 40% (265/668) were output indicators, 59.5% (400/668) were outcome indicators and 0.5% (3/668) were impact indicators. A total of 34% (225/668) of these indicators were measures of individual research capacity, 38% (265/668) were measures of institutional research capacity and 21% (178/668) were systemic measures of research capacity. Figure 2 illustrates the spread of indicator type across these three categories by level. The full list of 668 indicators, inclusive of source information, is available as Underlying data 18 .

Outcome indicators
The 400 outcome indicators were subsequently coded to nine thematic categories and 36 sub-categories, as described in Box 2 . The categories and the total number of indicators in each (across all three levels) were as follows: research management and support (n=97), skills/knowledge (n=62), collaboration activities (n=53), knowledge translation (n=39), bibliometrics (n=31), research funding (n=25), recognition (n=11), infrastructure (n=5) and other (n=77). Figure 3 depicts the number of outcome indicators by category and level.
Outcome indicator categories and sub-categories
1. Bibliometrics : Indicators relating to the development, publication and use of written outputs such as peer reviewed journal articles.
Sub-categories: peer reviewed publication; publication (any form of publication other than peer review); reference (e.g. records of citations); quality (e.g. rating by impact factor).
2. Collaboration Activities : Indicators relating to networking, collaborating, mentoring type activities.
Sub-categories: engagement (evidence of working collaboratively); establishment (creating new networks, collaborations); experience (e.g. perception of equity in a specific partnership).
3. Infrastructure : Indicators relating to research infrastructure including buildings, labs, equipment, libraries and other physical resources.
Sub-categories: suitability (the provision of adequate facilities for research); procurement (e.g. purchase of laboratory equipment).
4. Knowledge translation : Indicators relating to the dissemination of research and knowledge, including conferences, media and public education/outreach.
Sub-categories: dissemination (examples of research being communicated to different audiences); influence (using research knowledge to influence policy, the commissioning of new research, etc).
5. Recognition :Indicators relating to professional or institutional esteem.
Sub-categories: Appointment (e.g. appointed to leadership positions); Awards (i.e. receiving an award); reputation (e.g. invited keynote address).
6. Research funding : Indicators relating to funding for research.
Sub-categories: funds received (e.g. competitive grants); allocation (e.g. allocate budget to support local research); expenditure (use of research funds); access (access to research funding/competitive awards).
7. Research Management & Support (RMS) : Indicators relating to the administration of university or research institution systems that make research possible (e.g. finance, ITC and project management).
Sub-categories: career support (e.g. working conditions, salary and career development); organisation capacity (to manage/support research); research investment; resource access (e.g. to IT, libraries etc); sustainability (of RMS); governance (e.g. formation of ethics review committees); national capacity (to support research); national planning (e.g. developing national research priorities).
8. Skills/training activities : Indicators relating to training and educational activities relating to research or research subject area knowledge.
Sub-categories: attainment (of new skills); application (of new skills); transfer (of new skills).
9. Other : Indicators relating to any area other than the eight described above.
Sub-categories: research quality (e.g. quality of work undertaken); research production (e.g. increase in research activity); research process (e.g. inclusion of new methods or techniques); research workforce (e.g. growth in number of researchers); career advancement (e.g. promotion); equity (e.g. gender equity); miscellaneous.

Table 1 – Table 3 present the number of outcome indicators in each sub-category as well as an example indicator for each, by the three respective research capacity levels (individual, institutional and systemic). The category and sub-category designation assigned to all 400 outcome indicators are available as Underlying data 18 .
| Category | Variant | Number | Example indicator |
|---|---|---|---|
| Bibliometrics | Peer-reviewed publication Publication Reference Quality | 5 13 3 6 | Number of articles published in peer-reviewed journals Number of conference papers Citations Publications with impact factor indexed in WoS |
| Collaboration Activities | Engagement Establishment Experience | 10 4 1 | Evidence of contribution/membership to networks Development of sustainable research collaborations Attitudes/behavior are conducive to working effectively in partnership towards development goals |
| Knowledge Translation | Dissemination Influence | 4 5 | Applied dissemination of findings Evidence of influence on local strategy & planning |
| Recognition | Appointment Awards Reputation | 2 3 3 | Editor of international/national conference proceedings Number of awards/type of awards Invitations to speak at meetings |
| Research Funding | Funds received | 11 | New research funding obtained |
| RMS | Career support | 3 | Percent of time spent on research activities |
| Skills/knowledge | Application Attainment Transfer | 13 27 2 | Applying/using new evaluation methodology Evidence of progressive skill development Shared lessons learned from the distance education program with other personnel at the site |
| Other | Research quality Research production Research process Research workforce Career advancement | 2 3 8 2 4 | Scientific merit of research proposal Number of grants completed Incorporation of end-users’ concerns into research planning & design Evidence that awardees returned to active & independent research in LMICs Returned fellows take up leadership roles in scientific networks & communities of practice |
| Categories | Variants | Number | Example indicator |
|---|---|---|---|
| Bibliometrics | Peer-review publication Publication Quality | 1 1 1 | Number of joint scientific publications Number of research reports published Production of high quality/scientifically sound literature reviews |
| Collaboration Activities | Engagement Establishment Experience | 15 6 3 | Number of joint activities with other research organizations Develop research networks within and between institutions Collaborations characterized by trust & commitment and continue after award concludes |
| Infrastructure | Suitability Procurement | 4 1 | Facilities and infrastructure are appropriate to research needs and researchers’ capacities Research equipment obtained at home institution |
| Knowledge Translation | Dissemination Influence | 9 5 | Number of knowledge exchange events Examples of applying locally developed knowledge in strategy policy and practice |
| Recognition | Reputation | 2 | Enhanced reputation & increased appeal of institutions |
| Research Funding | Funds Received Allocation Expenditure | 3 1 1 | Obtaining more funding for research & research skill building training at host organisation Budget allocation for specific priority health research areas Proportion of funds spent according to workplans |
| RMS | Organisational capacity Research investment Career support Resource access Sustainability Governance | 14 3 10 4 3 12 | Applying data systems for reporting at organizational level Funding to support practitioners & teams to disseminate findings Evidence of matching novice & experienced researchers Access to information technology Level of financial sustainability Growth & development of institution in line with vision & mission |
| Skills/knowledge | Application Attainment Transfer | 6 11 2 | Applying new skills in financial management to research projects Strengthening capacities to carry out methodologically sound evaluations in the South Counselling master's and PhD students about appropriate research design and protocols |
| Other | Research quality Career advancement Research production Research workforce Research process | 5 1 12 6 4 | Quality of research outputs Evidence of secondment opportunities offered & taken up Range & scale of research projects Levels of skills within workforce & skill mix of the skills across groups Evidence of supporting service user links in research |
| Categories | Variants | Number | Example indicator |
|---|---|---|---|
| Bibliometrics | Publication | 1 | Proportion of TDR grantees' publications with first author [country] institutions |
| Collaboration Activities | Engagement Establishment Experience | 4 9 1 | Changing how organizations work together to share/exchange information, research results Partnerships for research dialogue at local, regional & international levels TDR partnerships are perceived as useful & productive |
| Knowledge Translation | Dissemination Influence | 2 14 | Media interest in health research Policy decision are influenced by research outputs |
| Recognition | Reputation | 1 | Greater Sth-Sth respect between organisations leading to Sth-Sth learning activities |
| Research Funding | Allocation Access | 6 3 | Level of funding of research by the Government Local responsive funding access & use |
| RMS | National capacity National planning Governance Career support | 18 11 18 1 | Local ownership of research & health research system evaluation Harmonised regional research activities Governance of health research ethics Researcher salary on par or above other countries in region (by gender) |
| Skills/knowledge | Transfer | 1 | Secondary benefits to students through training, travel & education made them ‘diffusers’ of new techniques between institutions |
| Other | Research production Research workforce Research process Equity Research quality Miscellaneous | 11 5 7 4 1 2 | Generating new knowledge on a research problem at a regional level Evidence of brain drain or not Several institutions using/applying common methodology to conduct research towards common goal Equitable access to knowledge & experience across partnerships Proportion of positive satisfaction response from TDR staff Importance of multidisciplinary research over the past 5 years |
Table 4 presents the percentage of outcome indicators that met each of the four quality measures as well as the percentage that met all four quality indicators by indicator category. As shown, all outcome indicators implied a measurement focus (e.g. received a national grant or time spent on research activities), 21% presented a defined measure (e.g. had at least one publication), 13% presented a defined measure sensitive to change (e.g. number of publications presented in peer reviewed journals) and 5% presented a defined measure, sensitive to change and time bound (e.g. number of competitive grants won per year). Only 1% (6/400) of outcome indicators met all four quality criteria including: 1) Completed research projects written up and submitted to peer reviewed journals within 4 weeks of the course end; 2) Number of competitive grants won per year (independently or as a part of a team); 3) Number and evidence of projects transitioned to and sustained by institutions, organizations or agencies for at least two years; 4) Proportion of females among grantees/contract recipients (over total number and total funding); 5) Proportion of [Tropical Disease Research] grants/contracts awarded to [Disease Endemic Country] (over total number and total funding); and 6) Proportion of [Tropical Disease Research] grants/contracts awarded to low-income countries (over total number and total funding). Indicators pertaining to research funding and bibliometrics scored highest on the quality measures whereas indicators pertaining to research management and support and collaboration activities scored the lowest.
| Level | No | Quality measure | All 4 quality measures evident | |||
|---|---|---|---|---|---|---|
| Implied | Defined | Sensitive to change | Time-Bound | |||
| % | % | % | % | % | ||
| Bibliometrics | 31 | 100 | 42 | 29 | 6 | 3 |
| Collaboration Activities | 53 | 100 | 13 | 9 | 0 | 0 |
| Infrastructure | 5 | 100 | 20 | 0 | 0 | 0 |
| Knowledge Translation | 39 | 100 | 18 | 18 | 0 | 0 |
| Recognition | 11 | 100 | 27 | 18 | 0 | 0 |
| Research Funding | 25 | 100 | 56 | 40 | 12 | 12 |
| RMS | 97 | 100 | 7 | 7 | 1 | 1 |
| Skills/Knowledge | 62 | 100 | 27 | 0 | 21 | 0 |
| Other | 77 | 100 | 19 | 19 | 1 | 1 |
Impact indicators
The three impact indicators were all systemic-level indicators and were all coded to a ‘health and wellbeing’ theme; two to a sub-category of ‘people’, one to a sub-category of ‘disease’. The three impact indicators were: 1) Contribution to health of populations served; 2) Impact of project on patients' quality of life, including social capital and health gain; and 3) Estimated impact on disease control and prevention. All three met the ‘implied measure’ quality criteria. No indicators met any of the remaining three quality criteria.
This paper sought to inform the development of standardised RCS evaluation metrics through a systematic review of RCS indicators previously described in the published and grey literatures. The review found a spread between individual- (34%), institutional- (38%) and systemic-level (21%) indicators, implying both a need and interest in RCS metrics across all levels of the research system. This is consistent with contemporary RCS frameworks 10 , 19 , although the high proportion of institutional-level indicators is somewhat surprising given the continued predominance of individual-level RCS initiatives and activities such as scholarship provision, individual skills training and research-centred RCS consortia 20 .
Outcome indicators were the most common indicator type identified by the review, accounting for 59.5% (400/669) of the total. However, the large number of outcome indicators were subsequently assigned to a relatively small number of post-coded thematic categories (n=9), suggestive of considerable overlap and duplication among the existing indicator stock. Just under two-thirds of the outcome indicators pertained to four thematic domains (research management and support, skills/knowledge attainment or application, collaboration activities and knowledge translation) suggesting an even narrower focus in practice. It is not possible to determine on the basis of this review whether the relatively narrow focus of the reported indicators is reflective of greater interest in these areas or practical issues pertaining to outcome measurement (e.g. these domains may be inherently easier to measure); however, if standardised indicators in these key focal areas are identified and agreed, then they are likely to hold wide appeal.
The near absence of impact indicators is a finding of significant note, highlighting a lack of long-term evaluation of RCS interventions 8 as well as the inherent complexity in attempting to evaluate a multifaceted, long-term, continuous process subject to a diverse range of influences and assumptions. Theoretical models for evaluating complex interventions have been developed 33 , as have broad guidelines for applied evaluation of complex interventions 34 ; thus, the notion of evaluating ‘impact’ of RCS investment is not beyond the reach of contemporary evaluation science and evaluation frameworks tailored for RCS interventions have been proposed 11 . Attempting to measure RCS impact by classic, linear evaluation methodologies via precise, quantifiable metrics may not be the best path forward. However, the general dearth of any form of RCS impact indicator (as revealed in this review) or robust evaluative investigation 8 , 20 suggests an urgent need for investment in RCS evaluation frameworks and methodologies irrespective of typology.
The quality of retrieved indicators, as assessed by four specified criteria (measure for the stated indicator was implied by indicator description; measure clearly defined; defined measure was sensitive to change; and defined measure was time-bound) was uniformly poor. Only 1% (6/400) of outcome indicators and none of the impact indicators met all four criteria. Quality ratings were highest amongst indicators focused on measuring research funding or bibliometrics and lowest amongst research management and support and collaboration activities. This most likely reflects differences in the relative complexity of attempting to measure capacity gain across these different domain types; however, as ‘research management and support’ and ‘collaboration activity’ indicators were two of the most common outcome indicator types, this finding suggests that the quality of measurement is poorest in the RCS domains of most apparent interest. The quality data further suggest that RCS indicators retrieved by the review were most commonly (by design or otherwise) ‘expressions’ of the types of RCS outcomes that would be worthwhile measuring as opposed to well defined RCS metrics. For example, ‘links between research activities and national priorities’ 19 or ‘ease of access to research undertaken locally’ 22 are areas in which RCS outcome could be assessed, yet precise metrics to do so remain undescribed.
Despite the quality issues, it is possible to draw potential ‘candidate’ outcome indicators for each focal area, and at each research capacity level, from the amalgamated list (see Underlying data ) 18 . These candidate indicators could then be further developed or refined through remote decision-making processes, such as those applied to develop other indicator sets 37 , or through a dedicated conference or workshop as often used to determine health research priorities 38 . The same processes could also be used to identify potential impact indicators and/or additional focal areas and associated indicators for either outcome or impact assessment. Dedicated, inclusive and broad consultation of this type would appear to be an essential next step towards the development of a comprehensive set of standardised, widely applicable RCS outcome and impact indicators given the review findings.
Limitations
RCS is a broad, multi-disciplinary endeavour without a standardised definition, lexicon or discipline-specific journals 8 . As such, relevant literature may have gone undetected by the search methodology. Similarly, it is quite likely that numerous RCS outcome or impact indicators exist solely in project specific log frames or other forms of project-specific documentation not accessible in the public domain or not readily accessible by conventional literature search methodologies. Furthermore, RCS outcome or impact indicators presented in a language other than English were excluded from review. The review findings, therefore, are unlikely to represent the complete collection of RCS indicators used by programme implementers and/or potentially accessible in the public domain. The quality measurement criteria were limited in scope, not accounting for factors such as relevance or feasibility, and were biased towards quantitative indicators. Qualitative indicators would have scored poorly by default. Nevertheless, the review findings represent the most comprehensive listing of currently available RCS indicators compiled to date (to the best of the authors’ knowledge) and the indicators retrieved are highly likely to be reflective of the range, type and quality of indicators in current use, even if not identified by the search methodology.
Numerous RCS outcome indicators are present in the public and grey literature, although across a relatively limited range. This suggests significant overlap and duplication in currently reported outcome indicators as well as common interest in key focal areas. Very few impact indicators were identified by this review and the quality of all indicators, both outcome and impact, was uniformly poor. Thus, on the basis of this review, it is possible to identify priority focal areas in which outcome and impact indicators could be developed, namely: research management and support, the attainment and application of new skills and knowledge, research collaboration and knowledge transfer. However, good examples of indicators in each of these areas now need to be developed. Priority next steps would be to identify and refine standardised outcome indicators in the focal areas of common interest, drawing on the best candidate indicators among those currently in use, and proposing potential impact indicators for subsequent testing and application.
Data availability
[version 1; peer review: 4 approved]
Funding Statement
This work was funded by the American Thoracic Society.
The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Reviewer response for version 1
Meriel flint-o'kane.
1 Faculty of Public Health and Policy, London School of Hygiene and Tropical Medicine, London, UK
Summary: This paper provides a review and analysis of the quality and suitability of M&E metrics for funding that is allocated to strengthen research capacity in LMIC's. Published and grey literature has been reviewed to identify indicators used to measure the outputs, outcomes and impacts of relevant programmes and the findings have been assessed in terms of content and quality. The authors conclude that the outcome indicators identified were of low quality and impact indicators are almost always missing from RCS MEL frameworks and recommend further work to develop appropriate indicators to measure the outcomes and impacts of research capacity strengthening programmes/activities. Through the review of existing outcome indicators the authors have identified four focal areas against which indicators could be developed.
- The search strategy and study selection is clearly described and links to source data are available. Data extraction and analysis methods are also clearly described.
- No major points to address. This work is by a leading team in the field of RCS research and makes a useful contribution to the literature in providing a thorough review of indicators used to monitor and evaluate work funded to strengthen research capacity.
- Though the article is not focused on health research, health is specifically referred to in a few places throughout the article e.g. line 4 (and corresponding references) of the introduction, Research Funding example indicators in Table 2, RMS example indicators in Table 3, numbers 5 and 6 of the 6 outcome indicators meeting all four quality criteria refer to TDR, and the impact indicators are all acknowledged as being specific to health and wellbeing. It would be interesting to understand which other research disciplines featured in the literature reviewed, and the spread of results across disciplines in order that analysis and findings could indicate if there is variety between and/or within disciplines in approaches to MEL for RCS and what can be learnt from this.
- No background, references or justification is given for the pre-determined 'quality' criteria.
- The authors note in 'Limitations' that project documents were not available in the public domain and documents not in English were excluded. Further reflection on to what extent Log Frames, ToC's and other MEL docs for programmes that have RCS as a primary or secondary outcome would be in the public domain could be helpful e.g. is it common for delivery partners of RCS programmes to make their MEL docs publicly available? If not, are these indicators representative of those currently/recently being used by actors in the RCS programme delivery space or do they represent a subset that is more likely to have publicly available data?
Is the work clearly and accurately presented and does it cite the current literature?
If applicable, is the statistical analysis and its interpretation appropriate?
Not applicable
Are all the source data underlying the results available to ensure full reproducibility?
Is the study design appropriate and is the work technically sound?
Are the conclusions drawn adequately supported by the results?
Are sufficient details of methods and analysis provided to allow replication by others?
Reviewer Expertise:
Global health, research capacity strengthening, higher education capacity
I confirm that I have read this submission and believe that I have an appropriate level of expertise to confirm that it is of an acceptable scientific standard.
Francesco Obino
1 Global Development Network, New Delhi, Delhi, India
Daniel Fussy
The article is an timely contribution to an urgent question: how do we know if research capacity strengthening is working? The analysis of the problem (a. the lack of a shared reference framework for evaluating research capacity strengthening, which in turn implies that b. the scope for systematic and cumulative learning remains limited) is convincing and valid. The methodology is clearly explained and up to existing standards and expectations for this kind of exercise. The conclusions are straightforward, and the limitations well articulated (the focus on English, and the bias towards quantitative measures being the most important ones.)
A few overall comments for the authors, keeping in mind the 'agenda' the article is trying to support (i.e. developing good examples of RCS indicators), and its potential uptake:
- RCS lack definition too, not just indicators. The article does not differentiate between research capacity strengthening done at the national level and at the international level, or in different fields (health sciences vs social sciences, etc.). While this is key to the aim of the paper to 'survey' existing indicators, the lack of solid evaluation of RCS can be also understood as the result not so much of 'underdevelopment' of the field, but of its overdevelopment in the absence of a shared definition of what RCS is. In this sense, putting all RCS (indicators) in the 'same box' might in fact reinforce the confusion around what is there to be measured, and how. International donor-funded, project-based RCS efforts differ (in scope, objectives and means) from the RCS effort of a science council or a local research training institution - despite overlaps. Often, the difference in objectives might make indicators hard to include in the same box. In this sense, the paper should acknowledge the lack of a shared definition of RCS, and the limitation it poses to an analysis of indicators. For this specific article, it might be useful to define RCS as international, donor-funded, project-based set of activities. Arguably, the very need of a discussion on RCS evaluation is largely driven by the fact that RCS is part of the evaluation-heavy international donor sector. This might help further defining the relevant timeframe for the search, and situating RCS historically.
- RCS is more than the sum of quality outputs. I wonder about the lack of discussion on 'process indicators' given the nature of RCS as a set of activities. These are notoriously difficult (but not impossible) to use in the donor-funded, project-based, time-bound RCS efforts, but might be very relevant to describe change and ultimately impact.
- RCS impacts research systems, policy, or development? When it comes to discussion of impacts and impact indicators, the lack of definition of RCS becomes an insurmountable limitation. The study could acknowledge the need for unpacking the link between output, outcome and impact measurement/definition (particularly in light of lack of shared definition of RCS) in internationally funded programs, as a complementary exercise to the surveying of indicators. The fact that the very few impact indicators identified reveal an expectation for RCS to deliver impact on population health outcomes is a good example of the limitations imposed by lack of clear definitions.
- How important is the UK? Given the global audience of the piece, it might be useful to explain why the figures relating to projected RCS funding from the UK are significant to describe larger trends - particularly if figures include both 'direct' and 'indirect' RCS.
Research capacity building methodologies, political theory, international relations
We confirm that we have read this submission and believe that we have an appropriate level of expertise to confirm that it is of an acceptable scientific standard.
Peter Taylor
1 Institute of Development Studies, Brighton, UK
The article addresses an issue that is receiving renewed interest in recent years - research capacity strengthening (RCS), and the particular challenge of evaluating outputs, outcomes and impacts of RCS initiatives.
The study undertook a structured review of RCS indicators in the published and grey literature. Key findings included the identification of rather few examples of quality RCS, with emphasis on four focal areas (research management and support, skill and knowledge development, research collaboration and knowledge transfer. The study concludes that there is significant room for development of indicators, and consequently the potential adoption of these to allow a more systematic approach to RCS approaches and to their subsequent evaluation.
The study is clearly presented and has a solid methodology. The validity of the findings rest on the extent to which the systematic review did identify published material that engages in this issue. As the authors note, it is likely that there is a wider body of grey literature in the form of project and program reports that were not located through the search. This suggests that there is need for more published work on this topic (making the paper therefore relevant and useful), and perhaps reinforces a wider view that many RCS efforts are inadequately evaluated (or not evaluated at all). An earlier World Bank Institute report on evaluation of training (Taschereau, 2010 1 ), for example, had highlighted challenges in evaluation of the impact of training and institutional development programs. The study refers briefly to RCS interventions, taking training as an example, but this only related to training which makes up a small percentage of the overall efforts towards RCS.
It would be very interesting to situate this welcome study in the context of broader discussions and debates on RCS, particularly as a contribution to theory and practice at strengthening research capacity at individual, organizational and system levels. The latter of these is the most complex to conceptualise, to implement, and to measure, and is receiving valuable attention from RCS stakeholders such as the Global Development Network (GDN, 2017 2 ) through their Doing Research Program - a growing source of literature for subsequent review.
As the authors of the study note, there is a danger in identifying RCS indicators that are seen as having universal application and attractiveness because they are relatively easy to measure. There is an equal, related danger that, due to relative measurability, a majority of RCS interventions become so streamlined in terms of their approach that they begin to follow recipe or blueprint approaches.
The study is agnostic on different approaches to RCS. Work undertaken by the Think Tank Initiative (TTI) for example (Weyrauch, 2014 3 ) has demonstrated a range of useful RCS approaches, including flexible financial support, accompanied learning supported by trusted advisors/program officers, action learning, training and others. In a final evaluation of the Think Tank Initiative (Christoplos et al. , 2019 4 ), training was viewed as having had the least value amongst several intervention types in terms of RCS outcomes, whilst flexible financial support and accompanied learning processes were viewed as being significantly more effective. It would be interesting to identify indicators of outcomes or even impacts that might relate to different types of RCS interventions which were not included in the publications reviewed by this study.
A key indicator of RCS identified by the TTI evaluation, which interestingly does not appear explicitly in the indicator list of this study, was leadership. As the authors indicate, there are likely to be other valuable indicators not surfaced through this review and this requires more work.
This study offers a very important contribution to a field currently being reinvigorated and is highly welcome. Rather than being valued because it may potentially offer a future blueprint list of indicators, (not least since, as the authors observe, the indicator list generated in this study is partial in comparison to a much wider potential range), its value lies particularly in its potential for contribution to further debate and dialogue on the theory and practice of RCS interventions and their evaluation; this dialogue can in turn be further informed by access to a more diverse set of grey literature and by engagement with stakeholders who have experience and interest in strengthening this work. Hopefully the authors of this study, and other researchers, will continue this important line of work and promote ongoing discussion and debate.
International development, organizational learning and development, research capacity strengthening
Erica Di Ruggiero
1 Dalla Lana School of Public Health, University of Toronto, Toronto, ON, Canada
- The article outlines clear research questions and methods and provides a very useful summary of findings from a structured review of research capacity strengthening indicators for use in low- and middle-income countries (LMICs). Terminology is overall quite clearly defined. Some greater precision relate to the use of the terminology: context for indicator's application; knowledge transfer vs. knowledge translation are used.
- The definition of knowledge translation provided seems limiting and perhaps the authors meant only transfer. It would have been helpful to have some descriptive data on the sources of the publications/reports from which the indicators were derived (i.e. were they all published by academics vs. any from research funders). For example, it's unclear if any indicators developed by funders such as the International Development Research Centre and others that support LMIC research are included.
- The limitations section is clear.
- It would have been helpful to have the authors elaborate a bit more on the dearth of qualitative indicators, appreciating the fact that they would have 'scored poorly by default' because of the methodology used. Could the authors comment in the conclusion on areas for indicator development (like qualitative indicators; equity-related indicators - for e.g. I note that perception of equity in a specific partnership was part of the definition for collaboration and in the 'other' category, but to my knowledge, equity didn't really appear elsewhere)?
Public health research; evaluation
Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock ( ) or https:// means you've safely connected to the .gov website. Share sensitive information only on official, secure websites.
CDC Approach to Evaluation
Indicators are measureable information used to determine if a program is implementing their program as expected and achieving their outcomes. Not only can indicators help understand what happened or changed, but can also help you to ask further questions about how these changes happened.
The choice of indicators will often inform the rest of the evaluation plan, including evaluation methods, data analysis, and reporting. Strong indicators can be quantitative or qualitative, and are part of the evaluation plan. In evaluation, the indicators should be reviewed and used for program improvement throughout the program’s life cycle.
Indicators can relate to any part of the program and its logic model or program description. Here are three big and most common categories of indicators.
- Input indicators measure the contributions necessary to enable the program to be implemented (e.g., funding, staff, key partners, infrastructure).
- Process indicators measure the program’s activities and outputs (direct products/deliverables of the activities). Together, measures of activities and outputs indicate whether the program is being implemented as planned. Many people use output indicators as their process indicators; that is, the production of strong outputs is the sign that the program’s activities have been implemented correctly. Others may collect measures of the activities and separate output measures of the products/deliverables produced by those activities. Regardless of how you slice the process indicators, if they show the activities are not being implemented with fidelity, then the program risks not being able to achieve the intended outcomes.
- Outcome indicators measure whether the program is achieving the expected effects/changes in the short, intermediate, and long term. Some programs refer to their longest-term/most distal outcome indicators as impact indicators. Because outcome indicators measure the changes that occur over time, indicators should be measured at least at baseline (before the program/project begins) and at the end of the project. Long-term outcomes are often difficult to measure and attribute to a single program. However, that does not mean a program should not try to determine how they are contributing to the health impact of interest (e.g., decrease in morbidity related to particular health issue).
When selecting indicators, programs should keep in mind that some indicators will be more time-consuming and costly than others to collect and analyze. You should consider using existing data sources if possible (e.g., census, existing surveys, surveillance) and if not available then factor in the burden needed to collect each indicator before requiring collection.
Strong indicators are simple, precise, and measurable. In addition, some programs aspire to indicators that are ‘SMART’: Specific, measurable, attainable, relevant, and timely.
- Criteria for Selection of High-Performing Indicators: A Checklist to Inform Monitoring and Evaluation: Designed to help those responsible for monitoring and evaluation identify high-performing, resource-efficient indicators in collaboration with stakeholders.
- CDC Evaluation Coffee Break: Using Indicators: How to Make Indicators Work for You: Slides from presentation by staff at CDC’s Division for Heart Disease and Stroke prevention.
E-mail: [email protected]
To receive email updates about this page, enter your email address:
- Open access
- Published: 04 September 2024
Development of a basic evaluation model for manual therapy learning in rehabilitation students based on the Delphi method
- Wang Ziyi 1 , 2 ,
- Zhou Supo 3 &
- Marcin Białas 1
BMC Medical Education volume 24 , Article number: 964 ( 2024 ) Cite this article
Metrics details
Manual therapy is a crucial component in rehabilitation education, yet there is a lack of models for evaluating learning in this area. This study aims to develop a foundational evaluation model for manual therapy learning among rehabilitation students, based on the Delphi method, and to analyze the theoretical basis and practical significance of this model.
An initial framework for evaluating the fundamentals of manual therapy learning was constructed through a literature review and theoretical analysis. Using the Delphi method, consultations were conducted with young experts in the field of rehabilitation from January 2024 to March 2024. Fifteen experts completed three rounds of consultation. Each round involved analysis using Dview software, refining and adjusting indicators based on expert opinions, and finally summarizing all retained indicators using Mindmaster.
The effective response rates for the three rounds of questionnaires were 88%, 100%, and 100%, respectively. Expert familiarity scores were 0.91, 0.95, and 0.95; coefficient of judgment were 0.92, 0.93, and 0.93; authority coefficients were 0.92, 0.94, and 0.94, respectively. Based on three rounds of consultation, the model established includes 3 primary indicators, 10 secondary indicators, 17 tertiary indicators, and 9 quaternary indicators. A total of 24 statistical indicators were finalized, with 8 under the Cognitive Abilities category, 10 under the Practical Skills category, and 6 under the Emotional Competence category.
This study has developed an evaluation model for manual therapy learning among rehabilitation students, based on the Delphi method. The model includes multi-level evaluation indicators covering the key dimensions of Cognitive Abilities, Practical Skills, and Emotional Competence. These indicators provide a preliminary evaluation framework for manual therapy education and a theoretical basis for future research.
Peer Review reports
Introduction
The term “manual therapy” has traditionally been associated with physical therapists who examine and treat patients who have disorders related to the musculoskeletal system [ 1 ]. In vocational colleges in China, manual therapy techniques are an essential part of the rehabilitation education curriculum, integrating traditional Chinese medicine and modern medical teaching methods. These techniques include methods such as neurological rehabilitation, and the level of proficiency in these skills directly impacts the professional capabilities of students after graduation. In documents related to rehabilitation competency by the World Health Organization [ 2 , 3 , 4 ], it is noted that traditional teaching implicitly links the health needs of the population to the curriculum content. It also introduces competency-based education, which explicitly connects the health needs of the population to the competencies required of learners. The Rehabilitation Competency Framework (RCF) suggests a methodology for developing a rehabilitation education and training program and curriculum that can support competency-based education [ 5 ]. Research indicates that manual therapy education needs reform [ 6 ]. The existing evaluation models for manual therapy learning among rehabilitation students face several challenges: the use of equipment for objective assessments is cumbersome, the aspects of evaluation are not comprehensive, and there is a gap between the data from expert practices and the guidance provided to students. Some existing research has proposed models in specific manual therapy instruction. For example, the “Sequential Partial Task Practice (SPTP) strategy” was introduced in spinal manipulation (SM) teaching [ 7 ], and studies focusing on force-time characteristics [ 8 , 9 ] to summarize manual techniques for subsequent teaching. Some approaches apply specific techniques to specific diseases [ 10 ]. However, in terms of overall talent development, we may still need a more comprehensive and practical model.
Learning rehabilitation therapy techniques involves comprehensive skill development. Although some studies [ 11 , 12 ] have addressed the mechanisms of manual therapy, manual therapy based on mechanical actions should be considered one of the most important skills for rehabilitation therapists to focus on [ 13 ]. Currently, the training of rehabilitation students in vocational colleges primarily relies on course grades, clinical practice, and final-year exams to assess students before they enter society. However, these assessments often fail to meet the evaluation needs of employers, schools, teachers, patients/customers, and the students themselves regarding their rehabilitation capabilities. We lack a model for evaluating students’ manual therapy skills, especially for beginners. Developing a foundational evaluation model that integrates existing courses and clinical practice, in line with the World Health Organization’s Rehabilitation Competency Framework, holds significant practical and instructional value. This study aims to construct a foundational evaluation model for manual therapy learning among vocational school rehabilitation students through expert consultation. We present the following article following the CREDES reporting checklist (available at https://figshare.com/s/2886b42de467d58bd631 ) and the survey was performed according to the Delphi studies criteria [ 14 ].
This study employs the Delphi method for the following reasons [ 5 , 15 , 16 , 17 , 18 ]: Different experts have different emphases in manual therapy evaluation, and we need to collect a wide range of opinions and suggestions; unlike a focus group discussion, the anonymity of the Delphi method can reduce some disturbances in achieving consensus; the Delphi method allows for multiple rounds of consultation, facilitating the optimization of the model and flexible adjustment of issues that arise during consultation; the Delphi method is also used in constructing competency models for rehabilitation and has been maturely applied in closely related fields such as nursing. The research is mainly carried out in three stages: (1) Preparatory phase; (2) Delphi phase; (3) Reach consensus (Fig. 1 ).

The flow chart of the research
Literature review
We utilized databases from PubMed to search for and collect literature focused on the theme of rehabilitation education. With the MeSH terms related to “manual therapy” and “education” were used in PubMed. We also studied the World Health Organization’s (WHO) guidelines on rehabilitation competencies, gathered score sheets from national rehabilitation skills competitions, and collected training programs for students of rehabilitation therapy technology in vocational colleges in Jiangsu Province. This helped us to identify and organize the indicators that may be involved in the basic manual therapy learning of students.
Design consulting framework
The selection of experts for the study followed the principle of representativeness, considering factors such as educational qualifications, years of professional experience, and the type of workplace, which included schools, hospitals, and studios. It was ensured that each round included at least 15 experts [ 15 ]. Each round of questionnaires sent to experts is reviewed and tested. An initial list of 20 experts was created, and after a preliminary survey, the consultation list for the first round was determined randomly. The second round was organized based on the feedback and the collection of expert questionnaires from the first round, and the third round was set up following the second round’s feedback and questionnaire collection, continuing until the criteria for concluding the study were met. Inclusion criteria for experts included: (1) having a bachelor’s degree or higher; (2) at least two years of experience in teaching or mentoring; (3) achievements in provincial or national rehabilitation skills competitions or having guided students to such achievements; (4) high level of enthusiasm; and adherence to the principles of informed consent and voluntariness.
The main contents of expert consultation include the experts’ evaluation of the importance of the basic assessment indicators for students’ manual therapy learning, suggestions for building the model, basic information about the experts, and self-evaluations of the “basis for expert judgment” and “familiarity level”. Importance evaluation follows the Likert five-point rating scale, ranging from “very important” to “not important,” with scores assigned from 5 to 1, respectively. Expert Judgment Basis Coefficient (Ca): This includes aspects of work experience, theoretical analysis, understanding of domestic and international peers, and intuitive feelings, scored at three levels: high, medium, and low, with coefficients of 0.4, 0.3, 0.2 (work experience), 0.3, 0.2, 0.1 (theoretical analysis), 0.2, 0.1, 0.1 (understanding of peers), and 0.1, 0.1, 0.1 (intuitive feelings).Expert Familiarity Score (Cs): Rated over five levels: very familiar (1.0), familiar (0.8), moderately familiar (0.5), unfamiliar (0.2), and very unfamiliar (0.0). Expert Authority Coefficient (Cr): Indicates the level of expert authority, represented by the average of the Expert Judgment Basis Coefficient and Expert Familiarity Score. The prediction accuracy increases with the level of expert authority; an Expert Authority Coefficient ≥ 0.70 is considered acceptable, while this study uses an Expert Authority Coefficient > 0.8.
Statistical analysis
In this study, Excel and Dview software were used to analyze and process the data generated in each round. The degree of agreement among experts was analyzed using the coefficient of concordance and the coefficient of variation. The Kendall’s W coefficient of concordance, calculated through Dview software, is represented by W, which ranges from 0 to 1. A higher W value indicates better agreement among experts, and vice versa. If the P -value corresponding to W is less than 0.05, it can be considered that there is consistency in the experts’ ratings of the indicator system. The coefficient of variation (CV) is the ratio of the mean importance score of a certain indicator to its standard deviation; a smaller CV indicates a higher degree of agreement among experts about this indicator. This paper uses the coefficient of variation (CV) and Kendall’s W (W) to assess the level of agreement among expert opinions. A CV < 0.25 suggests a tendency towards consensus among experts. The concentration of expert opinions is represented by the arithmetic mean and the frequency of maximum scores. The arithmetic mean is the average of the experts’ importance scores for a particular indicator; a higher mean indicates greater importance of the indicator in the system. The frequency of maximum scores is the ratio of the number of experts who gave the highest score to an indicator to the total number of experts who rated that indicator; a higher frequency of maximum scores indicates greater importance of the indicator in the system.
A clear and transparent guide for action
During the indicator selection process, this paper adopts the “threshold method” for selecting indicators. The threshold calculation formulas used are as follows: For maximum score frequency and arithmetic mean, the threshold is calculated as “Threshold = Mean - Standard Deviation.” We will select indicators that score above this threshold. For the coefficient of variation, the threshold is calculated as “Threshold = Mean + Standard Deviation.” We will select indicators that score below this threshold. To ensure that key indicators are not eliminated, we will discard indicators that do not meet all three criteria. For indicators that do not meet one or two criteria, we will modify or discuss selection based on principles of rationality and systematicity. Modifications to the model content are generally confirmed by discussions between two experts. If the two experts cannot reach a consensus, a voting process is introduced for the disputed parts, and consensus is formed through expert voting. The process ends when all consulting experts no longer propose new suggestions for the overall model, and all indicators meet the inclusion criteria.
Basic principles of the model and model presentation
This study establishes two basic principles before constructing the target model. (1) The comprehensiveness of the model, where the dimensions of the assessment indicators built into the model are relatively comprehensive. (2) The flexibility of using the model, allows for flexible application across different scenarios, techniques, and personnel. Additionally, the model can be continuously supplemented and developed through further research. After consensus is reached, use MindMaster software to draw the final model.
Ethical considerations
The assignment for technical design, informed consent form, and data report form were approved by the Research Ethical Committee of Yancheng TCM Hospital Affiliated to Nanjing University of Chinese Medicine according to the World Medical Association Declaration of Helsinki Ethical. Approval number: KY230905-02.
Basic information of experts
In this study, an initial list of 20 experts was drafted. After a preliminary survey of their intentions, one expert who did not respond was excluded, and two with insufficient participation intentions were also excluded. This confirmed a list of 17 experts for the first round of consultation. After the first round, two experts whose authority coefficients were less than 0.8 were excluded, resulting in a final selection of 15 young experts from rehabilitation therapy-related schools, hospitals, and studios in Jiangsu Province (Table 1 ). The average age was 34.1 ± 6.6 years, and the average teaching tenure was 8.8 ± 7.7 years. Among them, one had an undergraduate degree, and 14 had graduate degrees or higher. All completed all three rounds of the survey. The level of expert engagement was indicated by the response rate of the expert consultation form, reflecting their concern for the study. The effective response rates were 88% for the first round, and 100% for the second and third rounds, all well above the 70% considered excellent. The average familiarity of the experts with the rounds was 0.91, 0.95, and 0.95 respectively, and the judgment basis coefficients were 0.92, 0.93, and 0.93. The authority coefficients were 0.92, 0.94, and 0.94 respectively.
Results of three rounds of the Delphi phase
The experts’ scoring data was organized in Excel and imported into DView software to calculate Kendall’s coefficient of concordance W, the progressive significance P value, chi-square, mean, coefficient of variation, and the frequency of full marks. The degree of opinion coordination and concentration of expert opinions across three rounds was summarized. The threshold method combined with expert views was applied to refine the model after three rounds of indicator screening. The table (Table 2 ) shows that the experts’ scoring on the indicator system was consistent across all three rounds.
The first Delphi round results
This round still included input from experts number 6 and 9 (Table 1 ). After the first round of consultation, according to the threshold principle (Table 3 ), the arithmetic mean and full score frequency of the primary indicator “Knowledge” in “On-campus” under “Relevant course scores” and “Off-campus” under “Relevant Skills Knowledge” did not meet the threshold. In the primary indicator “Skill”, under “Force” for “Quantitative (Instrument)” the coefficient of variation did not meet the threshold (Table 4 ). These findings suggest that the indicators set under “Knowledge” and “Skill” require significant modification, combined with the feedback from the consolidated advice of the 17 experts. There were 7 suggestions for optimizing the “Knowledge” indicator, 4 suggestions for “Skill”, 6 suggestions for “Emotion,” and 7 suggestions for the overall framework. We have redefined the “Knowledge” category as “Cognition” to broaden its conceptual scope [ 19 ], incorporating the indicator evaluation dimension of “Clinical Reasoning in Rehabilitation“ [ 20 , 21 , 22 ]. For the “Skill” category, we included “Proficiency“ [ 23 , 24 ] and “Subject Evaluation/Effectiveness“ [ 25 ] as indicator evaluation dimensions and divided “Applicability Judgment“ [ 26 , 27 , 28 , 29 ] and “Positioning selection” into four levels of indicators. For the “Emotion” category, we revised the indicators of “Car” and “Respect” to “Conduct and Demeanor” and “Professional Conduct,” dividing “Conduct and Demeanor” into four levels and “Professional Conduct” into three levels [ 30 ]. These recommendations were integrated into the design of the second-round consultation form to further explore the scientific nature of the model.
The second Delphi round results
After the second round of consultation, according to the threshold principle (Table 5 ), the primary indicator “Cognition” under “On-campus” for “Related Course Scores” did not meet the threshold for the arithmetic mean, and the coefficient of variation for “Clinical Practice Site Assessment” under “Off-campus” did not meet the threshold. Additionally, the average and full score frequency for “Related Skills and Knowledge Learning Ability Assessment” under “Off-campus” did not meet the threshold. For the primary indicator “Emotion”, under “Conduct and Demeanor”, the average and full score frequency for “Appearance and Dress” and the coefficient of variation for “Preparation of Materials” did not meet the threshold (Table 6 ). We consolidated the feedback from 15 experts and optimized the model. There were 11 optimization suggestions for the “Cognition” indicator, 3 for “Skill”, and 3 for “Emotion.” Regarding whether the tertiary indicator “Core Courses Scores” should be detailed into “Theoretical scores” and “Practical scores”, 13 experts chose “yes,” one chose “no,” and one was uncertain, thus it was adopted. Concerning whether to divide the tertiary indicators “Communication” and “Conduct and Behavior” into quaternary indicators, 7 experts chose “yes,” 7 chose “no,” and one was uncertain. Considering the actual application scenario and the simplicity of the model, we retained the quaternary indicators for “Communication” and removed the related quaternary indicators for “Conduct and Behavior”. Additionally, in the “Cognition” part of the “Clinical Reasoning in Rehabilitation”, we added “Science Popularization and Patient Education Awareness“ [ 31 , 32 ]; in “Skill”, we added “Palpation identification“ [ 33 , 34 , 35 ]; and in “Emotion” under “Professional Conduct,” we replaced “Respectful and Compassionate Thinking” with “Benevolent Physician Mindset”. After considering the content covered by nouns and the need for translation understanding, we further adjusted some expressions in the whole framework. The primary indicator “Cognitive”, “Skill” and “Emotion” were changed into “Cognitive Abilities”, “Practical Skills” and “Emotional Competence”. The secondary indicators “On-campus” and “Off-campus” are replaced by “Academic Performance” and “External Assessment”, and some other details are adjusted. These recommendations were integrated into the design of the third-round consultation form.
The third Delphi round results
After the third round of consultation, according to the threshold principle (Table 7 ), the average for “Related Course Grades” under “Academic Performance” in the primary indicator “Cognition Abilities” did not meet the threshold, nor did the average and full score frequency for “Science Popularization and Patient Education Awareness” under “Clinical Reasoning in Rehabilitation”. Additionally, the coefficient of variation for “Professional Expression” under “Communication” in “Conduct and Demeanor” within “Emotional Competence” did not meet the threshold (Table 8 ). After expert discussion, it was considered acceptable that these three indicator thresholds were exceptional. The 15 experts did not suggest further modifications to the model’s framework or content of indicators, indicating a stable and ideal concentration of opinions. Consequently, it was decided not to proceed with a fourth round of questionnaire survey.
Model presentation and external review
After the third round of research and investigation, we used Mindmaster software to draw the final model diagram (Fig. 2 ). Ultimately, three primary indicators, ten secondary indicators, seventeen tertiary indicators, and nine quaternary indicators were identified. Six experts evaluated the final model, and all agreed that it is relatively well-developed. Three experts raised concerns about the weighting of indicators, which may be the focus of our next phase of research. Additionally, one expert expressed great anticipation for feedback from the actual teaching application scenarios of this model.

The final model diagram
The design of teaching assessments for manual therapy education
A key aspect of manual therapy education in rehabilitation lies in understanding the “practice and case” paradigm [ 36 , 37 , 38 ]. Students transition from classroom learning in school to stage-wise assessment of their learning outcomes before entering the professional sphere, where their clinical practice mindset may evolve [ 20 ] but remain consistent in principle throughout. In our model, there is a concept of a “simulated patient”, which involves simulating assessments using standardized patients or cases representing various types of illnesses. This allows beginners to quickly narrow the gap in operational skills compared to experts [ 25 ]. The advancement of teaching philosophies has posed challenges in integrating the biopsychosocial model into manual therapy practices [ 30 ]. Students’ expectations regarding manual skills in physical therapy, along with reflections on the experiences of touch, both receiving and administering, can foster an understanding of the philosophical aspects of science, ethics, and communication [ 19 ]. The COVID-19 pandemic has altered the clinical practice and education of manual therapy globally [ 39 ]. Past classical teaching methods, such as Peyton’s four-step approach to teaching complex spinal manipulation techniques, have been found superior to standard teaching methods, effectively imparting intricate spinal manipulation skills regardless of gender [ 40 ]. Additionally, other methods involving the integration of teaching with clinical practice [ 38 ], interdisciplinary group learning approaches [ 41 ], and utilization of instructional videos instead of live demonstrations [ 42 ] have also been explored. From the initial use of closed-circuit television in massage education [ 43 ], we have progressed to leveraging the internet to learn the operational strategies and steps of exemplary therapists worldwide. This includes practices such as utilizing Computer-Assisted Clinical Case (CACC) SOAP note exercises to assess students’ application of principles and practices in osteopathic therapy [ 44 ] or employing interactive interdisciplinary online teaching tools for biomechanics and physiology instruction [ 45 ]. Establishing an online practice community to support evidence-based physical therapy practices in manual therapy is also pivotal [ 46 ]. Moreover, the integration of real-time feedback tools and teaching aids has significantly enhanced the depth and engagement of learning [ 9 ].
Designing teaching assessments is considered an “art”, and with the enrichment of teaching methods and tools, feedback strategies [ 47 ] in teaching are continuously optimized. The development of rehabilitation professional courses remains a focal point and challenge for educators. Reubenson A and Elkins MR summarize the models of clinical education for Australian physiotherapy students and analyze the current status of entry-level physiotherapy assessments, along with suggesting future directions for physiotherapy education [ 48 ]. Their study underscores the inclusivity of indicator construction in model development, enabling students from different internship sites to evaluate their manual therapy learning progress using the model. Moreover, the model can be utilized for assessment even in non-face-to-face scenarios. Tai J, Ajjawi R, et al.‘s study [ 49 ] summarized the historical development of teaching assessment, highlighting the transition of assessment models from simple knowledge or skill evaluation to more complex “complex appraisal.” This reflects the increased dimensions of educational assessment, the evolution of methods, and the emphasis on quality. From the Delphi outcomes, Sizer et al. identified eight key skill sets essential for proficiency in orthopedic manual therapy (OMT), as distilled through principal component factor analysis: manual joint assessment, fine sensorimotor proficiency, manual patient management, bilateral hand-eye coordination, gross manual characteristics of the upper extremity, gross manual characteristics of the lower extremity, control of self and patient movement, and discriminate touch [ 50 ]. Additionally, Rutledge CM et al.‘s study [ 51 ] focuses on developing remote health capabilities for nursing education and practice. Caliskan SA et al. [ 52 ]. established a consensus on artificial intelligence (AI)-related competencies in medical education curricula. These breakthroughs in teaching assessment concepts and formats that transcend spatial limitations are worth noting for the future. While existing research has established quantitative models for some challenging manual therapy operations, such as teaching and assessment of high-speed, low-amplitude techniques for the spine [ 53 ], a more comprehensive model is needed to assist beginners in manual therapy education.
The key elements in the manual therapy evaluation model
In 1973, McClelland DC first introduced the concept of competence, emphasizing “Testing for competence rather than for intelligence,” highlighting the importance of distinguishing individual performance levels within specific job contexts [ 54 ]. In 2021, the World Health Organization introduced a competence model for rehabilitation practitioners, defining competence in five dimensions: Practice, Professionalism, Learning and Development, Management and Leadership, and Research. Each dimension outlines specific objectives from the perspectives of Competencies and Activities, with requirements for rehabilitation practitioners varying from basic to advanced levels, encompassing simple to more comprehensive skills, under general principles of talent development [ 2 ]. Our model draws inspiration and insights from the framework and concepts proposed by the World Health Organization, as well as the scoring criteria of the Rehabilitation Skills Competition. When constructing primary indicators, we initially identified three dimensions: knowledge, skills, and emotions. Subsequently, adjustments were made during three rounds of the Delphi method. The content within the three modules can be independently referenced or utilized for novice practitioners to conduct self-assessment or peer evaluation before entering the workplace.
In the Cognitive Abilities module, the model incorporates Academic Performance, External Assessment, and Clinical Reasoning in Rehabilitation. Apart from the conventional Core Course Grades and Related Course Grades from the school curriculum, it also integrates evaluations from students’ internship processes, including Clinical Practice Site Assessment and Related Skills and Knowledge Learning Ability Assessment. To emphasize the significance of professional course learning in school, we further divide Core Course Grades into Theoretical Grades and Practical Grades, aligning with the current pre-clinical internship assessments at our institution. Regarding health education, this model focuses on areas consistent with some related research directions [ 32 , 55 , 56 ]. The model highlights the importance of Clinical Reasoning in Rehabilitation by emphasizing Problem Analysis and Problem Solving in clinical practice, while also addressing the importance of Science Popularization and Patient Education Awareness.
In the Practical Skills module, this model allows for demonstration assessment based on simulated clinical scenarios, where students perform maneuvers on standardized patients, with evaluation conducted by instructors or other experts. During the operation process, we may involve assessment criteria such as Selection of techniques, Palpation Identification, Force Application, Proficiency, and ultimately, Subject Evaluation/Effectiveness. The selection of techniques involves assessing the condition of the subject, determining specific maneuvers, and appropriateness of progression and regression during maneuvers. Additionally, the selection also considers the positioning of both the operator and the subject. In assessing Force Application, besides traditional subjective evaluations, objective assessments can also be facilitated with the aid of instrumentation. Finally, for assessing Proficiency in operation, evaluations can be provided for the Overall Diagnostic and Treatment Process and Overall Operation Status. This serves as a complement to further standardizing the manual therapy process [ 16 , 53 ], as the model can be applied in evaluating the procedures of certain specialized manual techniques.
In the Emotional Competence module, the model is divided into Conduct and Demeanor, and Professional Conduct. We believe that the therapeutic process between therapists and patients inherently involves interpersonal communication, hence focusing on Conduct and Behavior. Therefore, in conjunction with score sheets from national rehabilitation skills competitions, we may introduce more detailed requirements for Fluent Expression, Professional Expression, and Clear and Comprehensive Response. Furthermore, from the perspective of rehabilitation therapists’ professional roles and in alignment with the competence model, we emphasize the importance of Professional Conduct. We consider aspects such as Benevolent Physician Mindset and Scientific Diagnostic and Therapeutic Reasoning to be particularly noteworthy.
The scope and prospects of application of manual therapy evaluation model
The assessment model we designed holds relevance for skills or disciplines involving manual manipulation. Reviewing the literature on Manual Therapy [ 1 , 57 , 58 ] reveals that several terms are used interchangeably, such as Manipulative Therapy [ 59 ], Hands-on Therapy [ 31 ], Massage Therapy [ 24 , 60 ], Manipulative Physiotherapy [ 36 ], the Chiropractic Profession [ 61 ], and Osteopathy [ 62 ]. Threlkeld AJ once stated that manual therapy encompasses a broad range of techniques used to treat neuromusculoskeletal dysfunctions, primarily aiming to relieve pain and enhance joint mobility [ 58 ]. From a professional perspective, practitioners are often referred to as Physical Therapists [ 30 , 59 ], Manual Therapists [ 63 ], Manipulative Physiotherapists [ 33 ], and Massage Therapists [ 24 , 37 , 64 ]. Differences between Chiropractors and Massage Therapists have also been discussed in the literature [ 65 ]. The evolution of specific manual techniques such as Joint Mobilization [ 66 ], Osteopathic Manipulative Treatment (OMT) [ 67 , 68 ], Spinal Manipulation Therapy (SMT) [ 69 , 70 , 71 ], Posterior-to-Anterior (PA) High-Velocity-Low-Amplitude (HVLA) Manipulations [ 72 ], and Cervical Spine Manipulation [ 73 ] has provided more precise guidance for addressing common diseases and disorders. Furthermore, researchers have highlighted that the development of motor skills is an essential component of clinical training across various health disciplines including surgery, dentistry, obstetrics, chiropractic, osteopathy, and physical therapy [ 47 ]. In current rehabilitation education, manual therapy is a crucial component of physical therapy. We categorize physical therapy into physiotherapy and physical therapy exercises. Physiotherapy typically requires the use of special devices to perform interventions involving sound, light, electricity, heat, and magnetism. On the other hand, physical therapy exercises are generally performed manually, with some techniques occasionally requiring the use of simple assistive tools. As researchers have suggested with the concept of motor skills [ 47 ], our physical therapy exercises in teaching may not only be beneficial for a single discipline but could also enhance all disciplines that require “hands-on“ [ 31 ] or “human touch“ [ 13 ] operations.
In the prospects of manual therapy education, the comprehensive neurophysiological model has revealed that manual therapy produces effects through multiple mechanisms [ 11 , 12 ]. Studies have indicated [ 12 , 74 ] that the correlation between manual assessments and clinical outcomes, mechanical measurements, and magnetic resonance imaging is poor. As measurement methodologies enrich, our teaching assessment methods will also continuously evolve. Moreover, the close connection of manual therapy with related disciplines such as anatomy and physiology [ 75 , 76 , 77 ] provides physical therapists with a comprehensive biomedical background, enhancing their clinical capabilities and multidisciplinary collaboration skills [ 13 ]. Secondly, the development of educational resources should emphasize the integration of practice and theory. Drawing on the educational content packaging model of dispatcher-assisted cardiopulmonary resuscitation (DA-CPR) [ 78 ], combining e-learning with practical training, and computer-related teaching models will enrich offline teaching [ 74 ], providing students with a comprehensive learning experience. This model not only increases flexibility and accessibility but also optimizes learning outcomes through continuous performance assessment. Finally, with the development of artificial intelligence and advanced simulation technologies [ 79 ], future manual therapy education could simulate complex human biomechanics and neurocentral processes, providing deeper and more intuitive learning tools. This will further enhance educational quality and lay a solid foundation for the lifelong learning and career development of physical therapy professionals.
Limitations
The panel of experts consulted in this study is relatively concentrated among middle-aged and young professionals and exhibits noticeable regional characteristics. Consequently, the conclusions drawn may exhibit certain regional specificities. Moreover, during the translation process of professional terminology, some terms in the Chinese consultation form were uniform; however, modifications were made to ensure comprehension in the English context.
Conclusions
This study comprehensively utilized theoretical research, literature analysis, and the Delphi expert consultation method. The selected experts are highly authoritative, and there was a good level of activity across three rounds of consultations, with well-coordinated expert opinions. The model includes multi-level evaluation indicators covering the key dimensions of Cognitive Abilities, Practical Skills, and Emotional Competence. This research systematically and preliminarily constructed an evaluation system for foundational manual therapy learning in rehabilitation students.
Availability of data and materials
The datasets generated and/or analysed during the current study are available in the “figshare” repository, available at https://figshare.com/s/2886b42de467d58bd631 .
Riddle DL. Measurement of accessory motion: critical issues and related concepts. Phys Ther. 1992;72(12):865–74.
Article Google Scholar
World Health Organization. Rehabilitation Competency Framework [M]. https://www.who.int/publications/i/item/9789240008281
World Health Organization. Adapting the WHO rehabilitation competency framework to a specific context [M]. https://www.who.int/publications/i/item/9789240015333 .
World Health Organization. Using a contextualized competency framework to develop rehabilitation programmes and their curricula [M]. https://www.who.int/publications/i/item/9789240016576 .
Li Y, Zheng D, Ma L, Luo Z, Wang X. Competency-based construction of a comprehensive curriculum system for undergraduate nursing majors in China: an in-depth interview and modified Delphi study. Ann Palliat Med. 2022;11(5):1786–98.
Kolb WH, McDevitt AW, Young J, Shamus E. The evolution of manual therapy education: what are we waiting for? J Man Manip Ther. 2020;28(1):1–3.
Wise CH, Schenk RJ, Lattanzi JB. A model for teaching and learning spinal thrust manipulation and its effect on participant confidence in technique performance. J Man Manip Ther. 2016;24(3):141–50.
Gorrell LM, Nyiro L, Pasquier M, Page I, Heneghan NR, Schweinhardt P, Descarreaux M. Spinal manipulation characteristics: a scoping literature review of force-time characteristics. Chiropr Man Th. 2023;31(1):36.
Gonzalez-Sanchez M, Ruiz-Munoz M, Avila-Bolivar AB, Cuesta-Vargas AI. Kinematic real-time feedback is more effective than traditional teaching method in learning ankle joint mobilisation: a randomised controlled trial. BMC Med Educ. 2016;16(1):261.
Maicki T, Bilski J, Szczygiel E, Trabka R. PNF and manual therapy treatment results of patients with cervical spine osteoarthritis. J Back Musculoskelet Rehabil. 2017;30(5):1095–101.
Bialosky JE, Bishop MD, Price DD, Robinson ME, George SZ. The mechanisms of manual therapy in the treatment of musculoskeletal pain: a comprehensive model. Man Ther. 2009;14(5):531–8.
Bialosky JE, Beneciuk JM, Bishop MD, Coronado RA, Penza CW, Simon CB, George SZ. Unraveling the mechanisms of manual therapy: modeling an approach. J Orthop Sports Phys Ther. 2018;48(1):8–18.
Geri T, Viceconti A, Minacci M, Testa M, Rossettini G. Manual therapy: exploiting the role of human touch. Musculoskelet Sci Pract. 2019;44:102044.
Junger S, Payne SA, Brine J, Radbruch L, Brearley SG. Guidance on conducting and reporting Delphi studies (CREDES) in palliative care: recommendations based on a methodological systematic review. Palliat Med. 2017;31(8):684–706.
de Villiers MR, de Villiers PJ, Kent AP. The Delphi technique in health sciences education research. Med Teach. 2005;27(7):639–43.
O’Donnell M, Smith JA, Abzug A, Kulig K. How should we teach lumbar manipulation? A consensus study. Man Ther. 2016;25:1–10.
Rushton A, Moore A. International identification of research priorities for postgraduate theses in musculoskeletal physiotherapy using a modified Delphi technique. Man Ther. 2010;15(2):142–8.
Keter D, Griswold D, Learman K, Cook C. Priorities in updating training paradigms in orthopedic manual therapy: an international Delphi study. J Educ Eval Health Prof. 2023;20:4.
Perry J, Green A, Harrison K. The impact of masters education in manual and manipulative therapy and the ‘knowledge acquisition model.’ Man Ther. 2011;16(3):285–90.
Constantine M, Carpenter C. Bringing masters’ level skills to the clinical setting: what is the experience like for graduates of the master of science in manual therapy programme? Physiother Theory Pract. 2012;28(8):595–603.
Cruz EB, Moore AP, Cross V. A qualitative study of physiotherapy final year undergraduate students’ perceptions of clinical reasoning. Man Ther. 2012;17(6):549–53.
Yamamoto K, Condotta L, Haldane C, Jaffrani S, Johnstone V, Jachyra P, Gibson BE, Yeung E. Exploring the teaching and learning of clinical reasoning, risks, and benefits of cervical spine manipulation. Physiother Theory Pract. 2018;34(2):91–100.
Przekop PR Jr, Tulgan H, Przekop A, DeMarco WJ, Campbell N, Kisiel S. Implementation of an osteopathic manipulative medicine clinic at an allopathic teaching hospital: a research-based experience. J Am Osteopath Assoc. 2003;103(11):543–9.
Google Scholar
Donoyama N, Shibasaki M. Differences in practitioners’ proficiency affect the effectiveness of massage therapy on physical and psychological states. J Bodyw Mov Ther. 2010;14(3):239–44.
Whitman JM, Fritz JM, Childs JD. The influence of experience and specialty certifications on clinical outcomes for patients with low back pain treated within a standardized physical therapy management program. J Orthop Sports Phys Ther. 2004;34(11):662–72 discussion 672 – 665.
Thomson OP, Petty NJ, Moore AP. Clinical decision-making and therapeutic approaches in osteopathy - a qualitative grounded theory study. Man Ther. 2014;19(1):44–51.
Hansen BE, Simonsen T, Leboeuf-Yde C. Motion palpation of the lumbar spine–a problem with the test or the tester? J Manipulative Physiol Ther. 2006;29(3):208–12.
Pool J, Cagnie B, Pool-Goudzwaard A. Risks in teaching manipulation techniques in master programmes. Man Ther. 2016;25:e1-4.
Goncalves G, Demortier M, Leboeuf-Yde C, Wedderkopp N. Chiropractic conservatism and the ability to determine contra-indications, non-indications, and indications to chiropractic care: a cross-sectional survey of chiropractic students. Chiropr Man Th. 2019;27:3.
Jones M, Edwards I, Gifford L. Conceptual models for implementing biopsychosocial theory in clinical practice. Man Ther. 2002;7(1):2–9.
Pesco MS, Chosa E, Tajima N. Comparative study of hands-on therapy with active exercises vs education with active exercises for the management of upper back pain. J Manipulative Physiol Ther. 2006;29(3):228–35.
Eilayyan O, Thomas A, Halle MC, Ahmed S, Tibbles AC, Jacobs C, Mior S, Davis C, Evans R, Schneider MJ, et al. Promoting the use of self-management in novice chiropractors treating individuals with spine pain: the design of a theory-based knowledge translation intervention. BMC Musculoskelet Disord. 2018;19(1):328.
Downey BJ, Taylor NF, Niere KR. Manipulative physiotherapists can reliably palpate nominated lumbar spinal levels. Man Ther. 1999;4(3):151–6.
Harlick JC, Milosavljevic S, Milburn PD. Palpation identification of spinous processes in the lumbar spine. Man Ther. 2007;12(1):56–62.
Phillips DR, Barnard S, Mullee MA, Hurley MV. Simple anatomical information improves the accuracy of locating specific spinous processes during manual examination of the low back. Man Ther. 2009;14(3):346–50.
Rushton A, Lindsay G. Defining the construct of masters level clinical practice in manipulative physiotherapy. Man Ther. 2010;15(1):93–9.
Sherman KJ, Cherkin DC, Kahn J, Erro J, Hrbek A, Deyo RA, Eisenberg DM. A survey of training and practice patterns of massage therapists in two US states. BMC Complement Altern Med. 2005;5: 13.
Flynn TW, Wainner RS, Fritz JM. Spinal manipulation in physical therapist professional degree education: a model for teaching and integration into clinical practice. J Orthop Sports Phys Ther. 2006;36(8):577–87.
MacDonald CW, Lonnemann E, Petersen SM, Rivett DA, Osmotherly PG, Brismee JM. COVID 19 and manual therapy: international lessons and perspectives on current and future clinical practice and education. J Man Manip Ther. 2020;28(3):134–45.
Gradl-Dietsch G, Lubke C, Horst K, Simon M, Modabber A, Sonmez TT, Munker R, Nebelung S, Knobe M. Peyton’s four-step approach for teaching complex spinal manipulation techniques - a prospective randomized trial. BMC Med Educ. 2016;16(1):284.
Schuit D, Diers D, Vendrely A. Interdisciplinary group learning in a kinesiology course: a novel approach. J Allied Health. 2013;42(4):e91-96.
Seals R, Gustowski SM, Kominski C, Li F. Does replacing live demonstration with instructional videos improve student satisfaction and osteopathic manipulative treatment examination performance? J Am Osteopath Assoc. 2016;116(11):726–34.
Norkin CC, Chiswell J. Use of closed-circuit television in teaching massage. Phys Ther. 1975;55(1):41–2.
Chamberlain NR, Yates HA. Use of a computer-assisted clinical case (CACC) SOAP note exercise to assess students’ application of osteopathic principles and practice. J Am Osteopath Assoc. 2000;100(7):437–40.
Martay JLB, Martay H, Carpes FP. BodyWorks: interactive interdisciplinary online teaching tools for biomechanics and physiology teaching. Adv Physiol Educ. 2021;45(4):715–9.
Evans C, Yeung E, Markoulakis R, Guilcher S. An online community of practice to support evidence-based physiotherapy practice in manual therapy. J Contin Educ Health Prof. 2014;34(4):215–23.
Triano JJ, Descarreaux M, Dugas C. Biomechanics–review of approaches for performance training in spinal manipulation. J Electromyogr Kinesiol. 2012;22(5):732–9.
Reubenson A, Elkins MR. Clinical education of physiotherapy students. J Physiother. 2022;68(3):153–5.
Tai J, Ajjawi R, Boud D, Dawson P, Panadero E. Developing evaluative judgement: enabling students to make decisions about the quality of work. High Educ. 2017;76(3):467–81.
Sizer PS Jr, Felstehausen V, Sawyer S, Dornier L, Matthews P, Cook C. Eight critical skill sets required for manual therapy competency: a Delphi study and factor analysis of physical therapy educators of manual therapy. J Allied Health. 2007;36(1):30–40.
Rutledge CM, O’Rourke J, Mason AM, Chike-Harris K, Behnke L, Melhado L, Downes L, Gustin T. Telehealth competencies for nursing education and practice: the four P’s of telehealth. Nurse Educ. 2021;46(5):300–5.
Caliskan SA, Demir K, Karaca O. Artificial intelligence in medical education curriculum: an e-Delphi study for competencies. PLoS ONE. 2022;17(7):e0271872.
Channell MK. Teaching and assessment of high-velocity, low-amplitude techniques for the spine in predoctoral medical education. J Am Osteopath Assoc. 2016;116(9):610–8.
McClelland DC. Testing for competence rather than for intelligence. Am Psychol. 1973;28(1):1–14.
Blickenstaff C, Pearson N. Reconciling movement and exercise with pain neuroscience education: a case for consistent education. Physiother Theory Pract. 2016;32(5):396–407.
Marcano-Fernandez FA, Fillat-Goma F, Balaguer-Castro M, Rafols-Perramon O, Serrano-Sanz J, Torner P. Can patients learn how to reduce their shoulder dislocation? A one-year follow-up of the randomized clinical trial between the boss-holzach-matter self-assisted technique and the spaso method. Acta Orthop Traumatol Turc. 2020;54(5):516–8.
Farrell JP, Jensen GM. Manual therapy: a critical assessment of role in the profession of physical therapy. Phys Ther. 1992;72(12):843–52.
Threlkeld AJ. The effects of manual therapy on connective tissue. Phys Ther. 1992;72(12):893–902.
Stephens EB. Manipulative therapy in physical therapy curricula. Phys Ther. 1973;53(1):40–50.
Kania-Richmond A, Menard MB, Barberree B, Mohring M. Dancing on the edge of research - what is needed to build and sustain research capacity within the massage therapy profession? A formative evaluation. J Bodyw Mov Ther. 2017;21(2):274–83.
Beliveau PJH, Wong JJ, Sutton DA, Simon NB, Bussieres AE, Mior SA, French SD. The chiropractic profession: a scoping review of utilization rates, reasons for seeking care, patient profiles, and care provided. Chiropr Man Th. 2017;25:35.
Requena-Garcia J, Garcia-Nieto E, Varillas-Delgado D. Objectivation of an educational model in cranial osteopathy based on experience. Med (Kaunas). 2021;57(3):246.
Twomey LT. A rationale for the treatment of back pain and joint pain by manual therapy. Phys Ther. 1992;72(12):885–92.
Violato C, Salami L, Muiznieks S. Certification examinations for massage therapists: a psychometric analysis. J Manipulative Physiol Ther. 2002;25(2):111–5.
Suter E, Vanderheyden LC, Trojan LS, Verhoef MJ, Armitage GD. How important is research-based practice to chiropractors and massage therapists? J Manipulative Physiol Ther. 2007;30(2):109–15.
Petersen EJ, Thurmond SM, Buchanan SI, Chun DH, Richey AM, Nealon LP. The effect of real-time feedback on learning lumbar spine joint mobilization by entry-level doctor of physical therapy students: a randomized, controlled, crossover trial. J Man Manip Ther. 2020;28(4):201–11.
Johnson SM, Kurtz ME. Diminished use of osteopathic manipulative treatment and its impact on the uniqueness of the osteopathic profession. Acad Med. 2001;76(8):821–8.
Baker HH, Linsenmeyer M, Ridpath LC, Bauer LJ, Foster RW. Osteopathic medical students entering family medicine and attitudes regarding osteopathic manipulative treatment: preliminary findings of differences by sex. J Am Osteopath Assoc. 2017;117(6):387–92.
Rogers CM, Triano JJ. Biomechanical measure validation for spinal manipulation in clinical settings. J Manipulative Physiol Ther. 2003;26(9):539–48.
Triano JJ, Rogers CM, Combs S, Potts D, Sorrels K. Developing skilled performance of lumbar spine manipulation. J Manipulative Physiol Ther. 2002;25(6):353–61.
Pasquier M, Cheron C, Barbier G, Dugas C, Lardon A, Descarreaux M. Learning spinal manipulation: objective and subjective assessment of performance. J Manipulative Physiol Ther. 2020;43(3):189–96.
Starmer DJ, Guist BP, Tuff TR, Warren SC, Williams MG. Changes in manipulative peak force modulation and time to peak thrust among first-year chiropractic students following a 12-week detraining period. J Manipulative Physiol Ther. 2016;39(4):311–7.
Van Geyt B, Dugailly PA, De Page L, Feipel V. Relationship between subjective experience of individuals, practitioner seniority, cavitation occurrence, and 3-dimensional kinematics during cervical spine manipulation. J Manipulative Physiol Ther. 2017;40(9):643–8.
Bowley P, Holey L. Manual therapy education. Does e-learning have a place? Man Ther. 2009;14(6):709–11.
Hou Y, Zurada JM, Karwowski W, Marras WS, Davis K. Estimation of the dynamic spinal forces using a recurrent fuzzy neural network. IEEE Trans Syst Man Cybern B Cybern. 2007;37(1):100–9.
Erdemir A, McLean S, Herzog W, van den Bogert AJ. Model-based estimation of muscle forces exerted during movements. Clin Biomech (Bristol Avon). 2007;22(2):131–54.
Gangata H, Porter S, Artz N, Major K. A proposed anatomy syllabus for entry-level physiotherapists in the United Kingdom: a modified Delphi methodology by physiotherapists who teach anatomy. Clin Anat. 2023;36(3):503–26.
Claesson A, Hult H, Riva G, Byrsell F, Hermansson T, Svensson L, Djarv T, Ringh M, Nordberg P, Jonsson M, et al. Outline and validation of a new dispatcher-assisted cardiopulmonary resuscitation educational bundle using the Delphi method. Resusc Plus. 2024;17:100542.
van den Bogert AJ. Analysis and simulation of mechanical loads on the human musculoskeletal system: a methodological overview. Exerc Sport Sci Rev. 1994;22:23–51.
Download references
Acknowledgements
Thanks to Dong Xinchun, Gu Zhongke, Lu Honggang, Li Le, Sun Wudong, Wang Yudi, Wu Wenlong, Zhao Xinyu and other experts for their assistance and patient analysis during the Delphi consultation process, and some experts chose to remain anonymous, we would like to express our gratitude once again.
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Author information
Authors and affiliations.
Department of Sport, Gdansk University of Physical Education and Sport, Gdansk, 80-336, Poland
Wang Ziyi & Marcin Białas
Jiangsu Vocational College of Medicine, Yancheng City, China
Jiangsu College of Nursing, Huaian City, China
You can also search for this author in PubMed Google Scholar
Contributions
Both authors contributed to the creation of the manuscript. WZ designed and conceptualized the review and wrote the draft manuscript. ZS assisted with the Delphi consultation process and article writing. MB was involved in designing and implementing the project as a supervisor.
Corresponding author
Correspondence to Marcin Białas .
Ethics declarations
Ethics approval and consent to participate.
This research was approved by the Research Ethical Committee of Yancheng TCM Hospital Affiliated to Nanjing University of Chinese Medicine according to the World Medical Association Declaration of Helsinki Ethical. Approval number: KY230905-02. Written Informed consent was obtained from all the study participants.
Consent for publication
Not applicable. This manuscript does not contain any individual person’s data in any form (including individual details, images, or videos).
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary material 1., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/ .
Reprints and permissions
About this article
Cite this article.
Ziyi, W., Supo, Z. & Białas, M. Development of a basic evaluation model for manual therapy learning in rehabilitation students based on the Delphi method. BMC Med Educ 24 , 964 (2024). https://doi.org/10.1186/s12909-024-05932-y
Download citation
Received : 14 May 2024
Accepted : 20 August 2024
Published : 04 September 2024
DOI : https://doi.org/10.1186/s12909-024-05932-y
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Manual therapy
- Delphi method
- Rehabilitation education
- Educational model
BMC Medical Education
ISSN: 1472-6920
- General enquiries: [email protected]

An official website of the United States government
Here's how you know
Official websites use .gov A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS A lock ( ) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
- Digg
Latest Earthquakes | Chat Share Social Media
Using Multiple Indicators to Assess Stream Condition in the Chesapeake Bay
- Publications
USGS is working with federal, state and local partners to develop multiple assessments of stream and river conditions in non-tidal areas of the Chesapeake Bay watershed. These assessments will help managers preserve stream health and improve biological conditions in impaired streams as the human population and climate continue to change in this region.
What is the issue?
Streams and rivers are strongly influenced by conditions in the surrounding landscape. Urban development and intensification of agriculture practices have resulted in altered habitat, degraded water quality, and poor biological conditions in many streams within the Chesapeake Bay watershed. Managers need assessments of stream habitat, water quality, and biological conditions to estimate watershed-wide conditions and to identify areas of alteration and potential sites for conservation or restoration. Furthermore, managers need scientific studies to determine the effectiveness of best management practices for restoring streams and the biological communities they support to promote healthy habitats, wildlife and people in the bay.

What is at stake?
Over 18 million people call the Chesapeake Bay watershed home and that number is expected to increase to 20 million by 2030 . The Chesapeake Bay Program , a regional partnership with representatives across the watershed, has highlighted the need to assess stream habitat, water quality, and biological health conditions to help meet the goals of the Chesapeake Bay Watershed Agreement, reduce pollution and restore the bay.
Recent analyses by USGS and partners suggest that anticipated changes in climate and land use patterns in the near future may have dramatic consequences to Chesapeake Bay streams, and thus the fish and wildlife that depend on them— potentially endangering the culture and socioeconomic fabric of the region.
What is our approach?
Over the past several decades, many programs have collected data on stream conditions, such as salinity, pH, dissolved oxygen; physical habitat characteristics; and biological communities including aquatic insects and fish. Recent advances in modeling, remote sensing, and data availability now provide an opportunity to assess potential change in stream conditions due to land use, climate, invasive species, and management actions.

A team of USGS scientists has compiled large data sets on key stream health variables (e.g., salinity, temperature, physical habitat, and streambank erosion) and biological communities (benthic macroinvertebrates and fish). USGS is using these indicators to assess stream conditions for non-tidal streams throughout the watershed using advanced statistical and mapping techniques. Additionally, USGS is evaluating how management activities implemented across the watershed might be reducing negative effects of land use change on receiving streams and the bay. Finally, the team is examining how future land use and climate may affect future stream conditions.
An overarching objective of this work is to integrate findings into management tools that can not only track changes in stream condition, but also identify which stream stressors should be addressed and identify areas optimal for conservation or restoration.
What are the benefits?
Restoring the Chesapeake Bay ecosystem requires understanding of current and future stressors on rivers and streams. Land use and climate are ever changing and assessments of stream condition in the Chesapeake Bay watershed are enhanced when factoring in these changes. Evaluating how changes in land use and climate may affect future stream habitat and biological condition will enable Chesapeake Bay Program partners to better target their management actions for current and future conditions.
Attribution of benthic macroinvertebrate sampling data to NHDPlus V2 and NHDPlus HR catchments within the Chesapeake Bay Watershed
Attribution of stream habitat assessment data to nhdplus v2 and nhdplus hr catchments within the chesapeake bay watershed.
This data release links habitat assessment sites to both the NHDPlus Version 2 and NHDPlus High Resolution Region 02 networks using the hydrolink methodology. Linked habitat sites are those compiled by the Interstate Commission on the Potomac River Basin (ICPRB) during creation of the Chesapeake Bay Basin-wide Index of Biotic Integrity (Chessie BIBI) for benthic macroinvertebrates (https://datahub
“ChesBay 24k – LU": Land Use/Land Cover Related Data Summaries for the Chesapeake Bay Watershed Within NHD Plus HR catchments
“chesbay 24k – cl": climate related data summaries for the chesapeake bay watershed within nhd plus hr catchments, “chesbay 24k – hu": human related data summaries for the chesapeake bay watershed within nhd plus hr catchments, attribution of chessie bibi and fish sampling data to nhdplusv2 catchments within the chesapeake bay watershed, fish community and species distribution predictions for streams and rivers of the chesapeake bay watershed, modeled estimates of altered hydrologic metrics for all nhdplus v21 reaches in the chesapeake bay watershed, community metrics from inter-agency compilation of inland fish sampling data within the chesapeake bay watershed, chesapeake bay watershed historical and future projected land use and climate data summarized for nhdplusv2 catchments, causal inference approaches reveal both positive and negative unintended effects of agricultural and urban management practices on instream biological condition, observed and projected functional reorganization of riverine fish assemblages from global change, explainable machine learning improves interpretability in the predictive modeling of biological stream conditions in the chesapeake bay watershed, usa, using fish community and population indicators to assess the biological condition of streams and rivers of the chesapeake bay watershed, usa, time marches on, but do the causal pathways driving instream habitat and biology remain consistent, linking altered flow regimes to biological condition: an example using benthic macroinvertebrates in small streams of the chesapeake bay watershed, disentangling the potential effects of land-use and climate change on stream conditions, predicting biological conditions for small headwater streams in the chesapeake bay watershed, a detailed risk assessment of shale gas development on headwater streams in the pennsylvania portion of the upper susquehanna river basin, u.s.a..
Simple New Blood Test Could Revolutionize Early Alzheimer’s Detection

Researchers at the University of Melbourne have developed a promising blood test for early Alzheimer’s disease detection by measuring potassium isotopes in blood serum, offering a potential breakthrough in managing and slowing the disease’s progression.
New research has identified a promising new method for early diagnosis of Alzheimer’s disease by analyzing biomarkers in blood, potentially reducing the effects of dementia.
AD is the most common form of dementia, estimated to contribute to 60-70 percent of cases, or more than 33 million cases worldwide, according to the World Health Organisation. Currently incurable, AD is usually diagnosed when a person is having significant difficulties with memory and thinking that impact their daily life.
University of Melbourne researcher Dr. Brandon Mahan leads a group of analytical geochemists from the Faculty of Science who are collaborating with neuroscientists in the Faculty of Medicine, Dentistry, and Health Sciences (based at The Florey) to develop a blood test for earlier diagnosis of AD, as described in a paper published in Metallomics .
In a world first, the researchers applied inorganic analytical geochemistry techniques, originally developed for cosmochemistry – for example, to study the formation and evolution of the Earth, the Moon, other planets, and asteroid samples – and adapted these highly sensitive techniques to search for early biomarkers of AD in human blood serum.
Pilot Study Results
They compared the levels of potassium isotopes in blood serum in 20 samples – 10 healthy and 10 AD patients from the Australian Imaging, Biomarker, and Lifestyle study and biobank.

“Our minimally invasive test assesses the relative levels of potassium isotopes in human blood serum and shows potential to diagnose AD before cognitive decline or other disease symptoms become apparent, so action can be taken to reduce the impacts,” Dr Mahan said.
“Our test is scalable and – unlike protein-based diagnostics that can break down during storage – it avoids sample stability issues because it assesses an inorganic biomarker.”
Clinical Implications and Future Directions
Currently, clinical diagnosis of AD is based on medical history, neurological exams, cognitive, functional, and behavioral assessments, brain imaging, and protein analysis of cerebrospinal fluid or blood samples.
“Earlier diagnosis would enable earlier lifestyle changes and medication that can help slow disease progression and would allow more time for affected families to take action to reduce the social, emotional, and financial impacts of dementia,” Dr Mahan said. “It could also make patients eligible for a wider variety of clinical trials, which advance research and may provide further medical benefits.
“My research team – the Melbourne Analytical Geochemistry group – seeks partners and support to continue this important research and development.”
Co-author Professor Ashley Bush from The Florey sees promise in the results from the small pilot study.
“Our blood test successfully identified AD and shows diagnostic power that could rival leading blood tests currently used in clinical diagnosis,” Professor Bush said. “Significant further work is required to determine the ultimate utility of this promising technique.”
With the world’s population aging, the incidence of AD is rising . The number of dementia sufferers is anticipated to double every 20 years and the global cost of dementia is forecast to rise to US$2.8 trillion by 2030. In 2024, more than 421,000 Australians live with dementia . It is the second leading cause of death in Australia and the leading cause for Australian women.
Reference: “Stable potassium isotope ratios in human blood serum towards biomarker development in Alzheimer’s disease” by Brandon Mahan, Yan Hu, Esther Lahoud, Mark Nestmeyer, Alex McCoy-West, Grace Manestar, Christopher Fowler, Ashley I Bush and Frédéric Moynier, 31 August 2024, Metallomics . DOI: 10.1093/mtomcs/mfae038
Related Articles
New hope in alzheimer’s fight: researchers identify unique early biomarker, scientists have discovered new pathways of alzheimer’s disease, feeling the heat: hot flashes are an early indicator for alzheimer’s disease, a sweet clue to alzheimer’s: sugar molecule predicts disease risk, new device can detect alzheimer’s 17 years in advance, signs of dementia are written in the blood: 33 metabolic compounds may be key to new treatments, the combination of foods you eat together may raise dementia risk, an aspirin a day does not keep dementia at bay – no difference than placebo, promising dementia vaccine draws closer.
Save my name, email, and website in this browser for the next time I comment.
Type above and press Enter to search. Press Esc to cancel.
IMAGES
VIDEO
COMMENTS
An indicator provides a measure of a concept, and is typically used in quantitative research. It is useful to distinguish between an indicator and a measure: Measures refer to things that can be relatively unambiguously counted, such as personal income, household income, age, number of children, or number of years spent at school. Measures, in
Introduction. The use of research performance indicators is often discussed in the literature on science and technology policy. Such discussions focus on, amongst others, the optimal measurement of research performance, research impact and research quality and on the possibly detrimental consequences of improper use of research indicators (e.g. Hicks et al. 2015).
The use of research performance indicators is often discussed in the literature on science and technology policy. Such discussions focus on, amongst others, the optimal measurement of research performance, research impact and research quality and on the possibly detrimental consequences of improper use of research indicators (e.g. Hicks et al. 2015).
In scientific research, concepts are the abstract ideas or phenomena that are being studied (e.g., educational achievement). Variables are properties or characteristics of the concept (e.g., performance at school), while indicators are ways of measuring or quantifying variables (e.g., yearly grade reports).
The Congressional Research Service (CRS) 6 regularly refers to the National Science Board's Science and Engineering Indicators (SEI) biennial volumes (see National Science Board, 2010), which are prepared by NCSES. 7 The online version of SEI also has a sizable share of users outside the policy arena and outside the United States. There are ...
Chapter: 2 Concepts and Uses of Indicators
Abstract Research performance indicators are broadly used, for a range of purposes. The. scientific literature on research indicators has a strong methodological focus. There is no. comprehensive ...
Any indicators used for assessment of research must be carefully chosen according to the purpose of the assessment, and can be used to inform decision-making and challenge preconceptions, but not to replace expert judgement. Research should be assessed on its merits and not on the basis of where it is published or the medium of its publication.
Research missions and the goals of assessment shift and the research system itself co-evolves. Once-useful metrics become inadequate; new ones emerge. Indicator systems have to be reviewed and ...
When conducting indicator research, there is a need to have a sense of realism to make sure that the proposed approach is methodologically sound as well as practically plausible to meet with the analytical and policy needs. The methods used to produce a composite index are controversial, and the ultimate choice has to reflect the balance ...
An indicator is a quantitative or qualitative factor or variable that provides a simple and reliable means to reflect the changes connected to an intervention. Indi- cators enable us to perceive differences, improvements or developments relating to a desired change (objective or result) in a particular context.
Social Indicators Research - SpringerLink
It is to be noted that author level indicators and article level metrics are new tools for research evaluation. Author level indicators encompasses h index, citations count, i10 index, g index ...
Indicators necessarily de-contextualize information. Many of our interviewees suggested that other types of information would need to be captured by research indicators; to us this casts doubts about the appropriateness of the use of indicators alone as the relevant devices for assessing research with the purposes of designing policy.
The indicator categories include: research income, which measures the monetary value amount in terms of grants and research income, whether private or public; research training, which measures the activity of the research in terms of supervised doctoral completions and supervised master's research completions, along with measuring the quality ...
Indicator (statistics) In statistics and research design, an indicator is an observed value of a variable, or in other words "a sign of a presence or absence of the concept being studied". [1] Just like each color indicates in a traffic lights the change in the movement. For example, if a variable is religiosity, and a unit of analysis is an ...
Rise of Research on Life Satisfaction. Empirical research on life satisfaction took off as a topic in 'social indicators research,' which emerged in the 1970s. The number of papers on this subject in the journal 'Social Indicators Research' grew so much that the specialized 'Journal of Happiness Studies' was split off in 2000.
INDICATORS - INTRAC ... INDICATORS
Welcome to the Research Impact Indicators & Metrics guide, a collection of tools, resources and contextual narrative to help you present a picture of how your scholarship is received and used within your field and beyond. Research is often measured in terms of its impact within an academic discipline(s), upon society or upon economies. As with ...
indicators take the form of questionnaires or structured outlines for assessments. A few indicators are formatted like indexes, while other indicators are constructed as stages or continua. All qualitative indicators serve as the basis for measuring change over time through short narrative assessments.
Measuring the outcome and impact of research capacity ...
Indicators of research quality, quantity, openness, and ...
Indicators - Program Evaluation
Image from Google 1. Time on Task. Definition: Measures the duration it takes for a user to complete a specific task within the product.. How to Measure:. Use a timer to track the start and end of a task. Example: Time how long it takes for a user to go from the home screen to completing a purchase.
The indicators used have been useful in comparing, assessing, and evaluating both study sites, and in terms of ecological and biological improvements, a geomorphological assessment is required to fulfil the assessment of natural recovery. ... (2021SGR00859), funded by the Agency for University and Research Grants Management (AGAUR (Agència de ...
Heat Index: An Alternative Indicator for Measuring the Impacts of Meteorological Factors on Diarrhoea in the Climate Change Era: A Time-Series Study in Dhaka, Bangladesh
These indicators provide a preliminary evaluation framework for manual therapy education and a theoretical basis for future research. Manual therapy is a crucial component in rehabilitation education, yet there is a lack of models for evaluating learning in this area.
USGS is using these indicators to assess stream conditions for non-tidal streams throughout the watershed using advanced statistical and mapping techniques. Additionally, USGS is evaluating how management activities implemented across the watershed might be reducing negative effects of land use change on receiving streams and the bay.
The Big Four Recession Indicators: Aggregate. The charts above focus on the big four individually, either separately or overlaid. Now let's take a quick look at an aggregate of the four. The next chart is an index created by equally weighing the four and indexing them to 100 for the January 1959 start date. I've used a log scale to give an ...
New research has identified a promising new method for early diagnosis of Alzheimer's disease by analyzing biomarkers in blood, potentially reducing the effects of dementia. AD is the most common form of dementia, estimated to contribute to 60-70 percent of cases, or more than 33 million cases worldwide, according to the World Health ...