JMP | Statistical Discovery.™ From SAS.

Statistics Knowledge Portal
A free online introduction to statistics
Chi-Square Test of Independence
What is the chi-square test of independence.
The Chi-square test of independence is a statistical hypothesis test used to determine whether two categorical or nominal variables are likely to be related or not.
When can I use the test?
You can use the test when you have counts of values for two categorical variables.
Can I use the test if I have frequency counts in a table?
Yes. If you have only a table of values that shows frequency counts, you can use the test.
Using the Chi-square test of independence
See how to perform a chi-square test of independence using statistical software.
- Download JMP to follow along using the sample data included with the software.
- To see more JMP tutorials, visit the JMP Learning Library .
The Chi-square test of independence checks whether two variables are likely to be related or not. We have counts for two categorical or nominal variables. We also have an idea that the two variables are not related. The test gives us a way to decide if our idea is plausible or not.
The sections below discuss what we need for the test, how to do the test, understanding results, statistical details and understanding p-values.
What do we need?
For the Chi-square test of independence, we need two variables. Our idea is that the variables are not related. Here are a couple of examples:
- We have a list of movie genres; this is our first variable. Our second variable is whether or not the patrons of those genres bought snacks at the theater. Our idea (or, in statistical terms, our null hypothesis) is that the type of movie and whether or not people bought snacks are unrelated. The owner of the movie theater wants to estimate how many snacks to buy. If movie type and snack purchases are unrelated, estimating will be simpler than if the movie types impact snack sales.
- A veterinary clinic has a list of dog breeds they see as patients. The second variable is whether owners feed dry food, canned food or a mixture. Our idea is that the dog breed and types of food are unrelated. If this is true, then the clinic can order food based only on the total number of dogs, without consideration for the breeds.
For a valid test, we need:
- Data values that are a simple random sample from the population of interest.
- Two categorical or nominal variables. Don't use the independence test with continous variables that define the category combinations. However, the counts for the combinations of the two categorical variables will be continuous.
- For each combination of the levels of the two variables, we need at least five expected values. When we have fewer than five for any one combination, the test results are not reliable.
Chi-square test of independence example
Let’s take a closer look at the movie snacks example. Suppose we collect data for 600 people at our theater. For each person, we know the type of movie they saw and whether or not they bought snacks.
Let’s start by answering: Is the Chi-square test of independence an appropriate method to evaluate the relationship between movie type and snack purchases?
- We have a simple random sample of 600 people who saw a movie at our theater. We meet this requirement.
- Our variables are the movie type and whether or not snacks were purchased. Both variables are categorical. We meet this requirement.
- The last requirement is for more than five expected values for each combination of the two variables. To confirm this, we need to know the total counts for each type of movie and the total counts for whether snacks were bought or not. For now, we assume we meet this requirement and will check it later.
It appears we have indeed selected a valid method. (We still need to check that more than five values are expected for each combination.)
Here is our data summarized in a contingency table:
Table 1: Contingency table for movie snacks data
| Action | 50 | 75 |
| Comedy | 125 | 175 |
| Family | 90 | 30 |
| Horror | 45 | 10 |
Before we go any further, let’s check the assumption of five expected values in each category. The data has more than five counts in each combination of Movie Type and Snacks. But what are the expected counts if movie type and snack purchases are independent?
Finding expected counts
To find expected counts for each Movie-Snack combination, we first need the row and column totals, which are shown below:
Table 2: Contingency table for movie snacks data with row and column totals
| Type of Movie | Snacks | No Snacks | |
| Action | 50 | 75 | |
| Comedy | 125 | 175 | |
| Family | 90 | 30 | |
| Horror | 45 | 10 | |
The expected counts for each Movie-Snack combination are based on the row and column totals. We multiply the row total by the column total and then divide by the grand total. This gives us the expected count for each cell in the table. For example, for the Action-Snacks cell, we have:
$ \frac{125\times310}{600} = \frac{38,750}{600} = 65 $
We rounded the answer to the nearest whole number. If there is not a relationship between movie type and snack purchasing we would expect 65 people to have watched an action film with snacks.
Here are the actual and expected counts for each Movie-Snack combination. In each cell of Table 3 below, the expected count appears in bold beneath the actual count. The expected counts are rounded to the nearest whole number.
Table 3: Contingency table for movie snacks data showing actual count vs. expected count
| Type of Movie | Snacks | No Snacks | Row totals |
| Action | 50 | 75 | 125 |
| Comedy | 125 | 175 | 300 |
| Family | 90 | 30 | 120 |
| Horror | 45 | 10 | 55 |
| Column totals | 310 | 290 | GRAND TOTAL = 600 |
When using software, these calculated values will be labeled as “expected values,” “expected cell counts” or some similar term.
All of the expected counts for our data are larger than five, so we meet the requirement for applying the independence test.
Before calculating the test statistic, let’s look at the contingency table again. The expected counts use the row and column totals. If we look at each of the cells, we can see that some expected counts are close to the actual counts but most are not. If there is no relationship between the movie type and snack purchases, the actual and expected counts will be similar. If there is a relationship, the actual and expected counts will be different.
A common mistake with expected counts is to simply divide the grand total by the number of cells. For our movie data, this is 600 / 8 = 75. This is not correct. We know the row totals and column totals. These are fixed and cannot change for our data. The expected values are based on the row and column totals, not just on the grand total.
Performing the test
The basic idea in calculating the test statistic is to compare actual and expected values, given the row and column totals that we have in the data. First, we calculate the difference from actual and expected for each Movie-Snacks combination. Next, we square that difference. Squaring gives the same importance to combinations with fewer actual values than expected and combinations with more actual values than expected. Next, we divide by the expected value for the combination. We add up these values for each Movie-Snacks combination. This gives us our test statistic.
This is much easier to follow using the data from our example. Table 4 below shows the calculations for each Movie-Snacks combination carried out to two decimal places.
Table 4: Preparing to calculate our test statistic
| Type of Movie | Snack | No Snacks |
| Action | Actual: 50 | Actual: 75 |
Difference: 50 – 64.58 = -14.58 Squared Difference: 212.67 Divide by Expected: 212.67/64.58 = 3.29 | Difference: 75 – 60.42 = 14.58 Squared Difference: 212.67 Divide by Expected: 212.67/60.42 = 3.52 | |
| Comedy | Actual: 125 | Actual 175 |
Difference: 125 – 155 = -30 Squared Difference: 900 Divide by Expected: 900/155 = 5.81 | Difference: 175 – 145 = 30 Squared Difference: 900 Divide by Expected: 900/145 = 6.21 | |
| Family | Actual: 90 | Actual: 30 |
Difference: 90 – 62 = 28 Squared Difference: 784 Divide by Expected: 784/62 = 12.65 | Difference: 30 – 58 = -28 Squared Difference: 784 Divide by Expected: 784/58 = 13.52 | |
| Horror | Actual: 45 | Actual: 10 |
Difference: 45 – 28.42 = 16.58 Squared Difference: 275.01 Divide by Expected: 275.01/28.42 = 9.68 | Difference: 10 – 26.58 = -16.58 Squared Difference: 275.01 Divide by Expected: 275.01/26.58 = 10.35 |
Lastly, to get our test statistic, we add the numbers in the final row for each cell:
$ 3.29 + 3.52 + 5.81 + 6.21 + 12.65 + 13.52 + 9.68 + 10.35 = 65.03 $
To make our decision, we compare the test statistic to a value from the Chi-square distribution . This activity involves five steps:
- We decide on the risk we are willing to take of concluding that the two variables are not independent when in fact they are. For the movie data, we had decided prior to our data collection that we are willing to take a 5% risk of saying that the two variables – Movie Type and Snack Purchase – are not independent when they really are independent. In statistics-speak, we set the significance level, α, to 0.05.
- We calculate a test statistic. As shown above, our test statistic is 65.03.
- We find the critical value from the Chi-square distribution based on our degrees of freedom and our significance level. This is the value we expect if the two variables are independent.
- The degrees of freedom depend on how many rows and how many columns we have. The degrees of freedom (df) are calculated as: $ \text{df} = (r-1)\times(c-1) $ In the formula, r is the number of rows, and c is the number of columns in our contingency table. From our example, with Movie Type as the rows and Snack Purchase as the columns, we have: $ \text{df} = (4-1)\times(2-1) = 3\times1 = 3 $ The Chi-square value with α = 0.05 and three degrees of freedom is 7.815.
- We compare the value of our test statistic (65.03) to the Chi-square value. Since 65.03 > 7.815, we reject the idea that movie type and snack purchases are independent.
We conclude that there is some relationship between movie type and snack purchases. The owner of the movie theater cannot estimate how many snacks to buy regardless of the type of movies being shown. Instead, the owner must think about the type of movies being shown when estimating snack purchases.
It's important to note that we cannot conclude that the type of movie causes a snack purchase. The independence test tells us only whether there is a relationship or not; it does not tell us that one variable causes the other.
Understanding results
Let’s use graphs to understand the test and the results.
The side-by-side chart below shows the actual counts in blue, and the expected counts in orange. The counts appear at the top of the bars. The yellow box shows the movie type and snack purchase totals. These totals are needed to find the expected counts.

Compare the expected and actual counts for the Horror movies. You can see that more people than expected bought snacks and fewer people than expected chose not to buy snacks.
If you look across all four of the movie types and whether or not people bought snacks, you can see that there is a fairly large difference between actual and expected counts for most combinations. The independence test checks to see if the actual data is “close enough” to the expected counts that would occur if the two variables are independent. Even without a statistical test, most people would say that the two variables are not independent. The statistical test provides a common way to make the decision, so that everyone makes the same decision on the data.
The chart below shows another possible set of data. This set has the exact same row and column totals for movie type and snack purchase, but the yes/no splits in the snack purchase data are different.

The purple bars show the actual counts in this data. The orange bars show the expected counts, which are the same as in our original data set. The expected counts are the same because the row totals and column totals are the same. Looking at the graph above, most people would think that the type of movie and snack purchases are independent. If you perform the Chi-square test of independence using this new data, the test statistic is 0.903. The Chi-square value is still 7.815 because the degrees of freedom are still three. You would fail to reject the idea of independence because 0.903 < 7.815. The owner of the movie theater can estimate how many snacks to buy regardless of the type of movies being shown.
Statistical details
Let’s look at the movie-snack data and the Chi-square test of independence using statistical terms.
Our null hypothesis is that the type of movie and snack purchases are independent. The null hypothesis is written as:
$ H_0: \text{Movie Type and Snack purchases are independent} $
The alternative hypothesis is the opposite.
$ H_a: \text{Movie Type and Snack purchases are not independent} $
Before we calculate the test statistic, we find the expected counts. This is written as:
$ Σ_{ij} = \frac{R_i\times{C_j}}{N} $
The formula is for an i x j contingency table. That is a table with i rows and j columns. For example, E 11 is the expected count for the cell in the first row and first column. The formula shows R i as the row total for the i th row, and C j as the column total for the j th row. The overall sample size is N .
We calculate the test statistic using the formula below:
$ Σ^n_{i,j=1} = \frac{(O_{ij}-E_{ij})^2}{E_{ij}} $
In the formula above, we have n combinations of rows and columns. The Σ symbol means to add up the calculations for each combination. (We performed these same steps in the Movie-Snack example, beginning in Table 4.) The formula shows O ij as the Observed count for the ij -th combination and E i j as the Expected count for the combination. For the Movie-Snack example, we had four rows and two columns, so we had eight combinations.
We then compare the test statistic to the critical Chi-square value corresponding to our chosen alpha value and the degrees of freedom for our data. Using the Movie-Snack data as an example, we had set α = 0.05 and had three degrees of freedom. For the Movie-Snack data, the Chi-square value is written as:
$ χ_{0.05,3}^2 $
There are two possible results from our comparison:
- The test statistic is lower than the Chi-square value. You fail to reject the hypothesis of independence. In the movie-snack example, the theater owner can go ahead with the assumption that the type of movie a person sees has no relationship with whether or not they buy snacks.
- The test statistic is higher than the Chi-square value. You reject the hypothesis of independence. In the movie-snack example, the theater owner cannot assume that there is no relationship between the type of movie a person sees and whether or not they buy snacks.
Understanding p-values
Let’s use a graph of the Chi-square distribution to better understand the p-values. You are checking to see if your test statistic is a more extreme value in the distribution than the critical value. The graph below shows a Chi-square distribution with three degrees of freedom. It shows how the value of 7.815 “cuts off” 95% of the data. Only 5% of the data from a Chi-square distribution with three degrees of freedom is greater than 7.815.

The next distribution graph shows our results. You can see how far out “in the tail” our test statistic is. In fact, with this scale, it looks like the distribution curve is at zero at the point at which it intersects with our test statistic. It isn’t, but it is very, very close to zero. We conclude that it is very unlikely for this situation to happen by chance. The results that we collected from our movie goers would be extremely unlikely if there were truly no relationship between types of movies and snack purchases.

Statistical software shows the p-value for a test. This is the likelihood of another sample of the same size resulting in a test statistic more extreme than the test statistic from our current sample, assuming that the null hypothesis is true. It’s difficult to calculate this by hand. For the distributions shown above, if the test statistic is exactly 7.815, then the p - value will be p=0.05. With the test statistic of 65.03, the p - value is very, very small. In this example, most statistical software will report the p - value as “p < 0.0001.” This means that the likelihood of finding a more extreme value for the test statistic using another random sample (and assuming that the null hypothesis is correct) is less than one chance in 10,000.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
- Chi-Square (Χ²) Tests | Types, Formula & Examples
Chi-Square (Χ²) Tests | Types, Formula & Examples
Published on May 23, 2022 by Shaun Turney . Revised on June 22, 2023.
A Pearson’s chi-square test is a statistical test for categorical data. It is used to determine whether your data are significantly different from what you expected. There are two types of Pearson’s chi-square tests:
- The chi-square goodness of fit test is used to test whether the frequency distribution of a categorical variable is different from your expectations.
- The chi-square test of independence is used to test whether two categorical variables are related to each other.
Table of contents
What is a chi-square test, the chi-square formula, when to use a chi-square test, types of chi-square tests, how to perform a chi-square test, how to report a chi-square test, practice questions, other interesting articles, frequently asked questions about chi-square tests.
Pearson’s chi-square (Χ 2 ) tests, often referred to simply as chi-square tests, are among the most common nonparametric tests . Nonparametric tests are used for data that don’t follow the assumptions of parametric tests , especially the assumption of a normal distribution .
If you want to test a hypothesis about the distribution of a categorical variable you’ll need to use a chi-square test or another nonparametric test. Categorical variables can be nominal or ordinal and represent groupings such as species or nationalities. Because they can only have a few specific values, they can’t have a normal distribution.
Test hypotheses about frequency distributions
There are two types of Pearson’s chi-square tests, but they both test whether the observed frequency distribution of a categorical variable is significantly different from its expected frequency distribution. A frequency distribution describes how observations are distributed between different groups.
Frequency distributions are often displayed using frequency distribution tables . A frequency distribution table shows the number of observations in each group. When there are two categorical variables, you can use a specific type of frequency distribution table called a contingency table to show the number of observations in each combination of groups.
| Bird species | Frequency |
|---|---|
| House sparrow | 15 |
| House finch | 12 |
| Black-capped chickadee | 9 |
| Common grackle | 8 |
| European starling | 8 |
| Mourning dove | 6 |
| Right-handed | Left-handed | |
|---|---|---|
| American | 236 | 19 |
| Canadian | 157 | 16 |
Prevent plagiarism. Run a free check.
Both of Pearson’s chi-square tests use the same formula to calculate the test statistic , chi-square (Χ 2 ):

- Χ 2 is the chi-square test statistic
- Σ is the summation operator (it means “take the sum of”)
- O is the observed frequency
- E is the expected frequency
The larger the difference between the observations and the expectations ( O − E in the equation), the bigger the chi-square will be. To decide whether the difference is big enough to be statistically significant , you compare the chi-square value to a critical value.
A Pearson’s chi-square test may be an appropriate option for your data if all of the following are true:
- You want to test a hypothesis about one or more categorical variables . If one or more of your variables is quantitative, you should use a different statistical test . Alternatively, you could convert the quantitative variable into a categorical variable by separating the observations into intervals.
- The sample was randomly selected from the population .
- There are a minimum of five observations expected in each group or combination of groups.
The two types of Pearson’s chi-square tests are:
Chi-square goodness of fit test
Chi-square test of independence.
Mathematically, these are actually the same test. However, we often think of them as different tests because they’re used for different purposes.
You can use a chi-square goodness of fit test when you have one categorical variable. It allows you to test whether the frequency distribution of the categorical variable is significantly different from your expectations. Often, but not always, the expectation is that the categories will have equal proportions.
- Null hypothesis ( H 0 ): The bird species visit the bird feeder in equal proportions.
- Alternative hypothesis ( H A ): The bird species visit the bird feeder in different proportions.
Expectation of different proportions
- Null hypothesis ( H 0 ): The bird species visit the bird feeder in the same proportions as the average over the past five years.
- Alternative hypothesis ( H A ): The bird species visit the bird feeder in different proportions from the average over the past five years.
You can use a chi-square test of independence when you have two categorical variables. It allows you to test whether the two variables are related to each other. If two variables are independent (unrelated), the probability of belonging to a certain group of one variable isn’t affected by the other variable .
- Null hypothesis ( H 0 ): The proportion of people who are left-handed is the same for Americans and Canadians.
- Alternative hypothesis ( H A ): The proportion of people who are left-handed differs between nationalities.
Other types of chi-square tests
Some consider the chi-square test of homogeneity to be another variety of Pearson’s chi-square test. It tests whether two populations come from the same distribution by determining whether the two populations have the same proportions as each other. You can consider it simply a different way of thinking about the chi-square test of independence.
McNemar’s test is a test that uses the chi-square test statistic. It isn’t a variety of Pearson’s chi-square test, but it’s closely related. You can conduct this test when you have a related pair of categorical variables that each have two groups. It allows you to determine whether the proportions of the variables are equal.
| Like chocolate | Dislike chocolate | |
|---|---|---|
| Like vanilla | 47 | 32 |
| Dislike vanilla | 8 | 13 |
- Null hypothesis ( H 0 ): The proportion of people who like chocolate is the same as the proportion of people who like vanilla.
- Alternative hypothesis ( H A ): The proportion of people who like chocolate is different from the proportion of people who like vanilla.
There are several other types of chi-square tests that are not Pearson’s chi-square tests, including the test of a single variance and the likelihood ratio chi-square test .
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

The exact procedure for performing a Pearson’s chi-square test depends on which test you’re using, but it generally follows these steps:
- Create a table of the observed and expected frequencies. This can sometimes be the most difficult step because you will need to carefully consider which expected values are most appropriate for your null hypothesis.
- Calculate the chi-square value from your observed and expected frequencies using the chi-square formula.
- Find the critical chi-square value in a chi-square critical value table or using statistical software.
- Compare the chi-square value to the critical value to determine which is larger.
- Decide whether to reject the null hypothesis. You should reject the null hypothesis if the chi-square value is greater than the critical value. If you reject the null hypothesis, you can conclude that your data are significantly different from what you expected.
If you decide to include a Pearson’s chi-square test in your research paper , dissertation or thesis , you should report it in your results section . You can follow these rules if you want to report statistics in APA Style :
- You don’t need to provide a reference or formula since the chi-square test is a commonly used statistic.
- Refer to chi-square using its Greek symbol, Χ 2 . Although the symbol looks very similar to an “X” from the Latin alphabet, it’s actually a different symbol. Greek symbols should not be italicized.
- Include a space on either side of the equal sign.
- If your chi-square is less than zero, you should include a leading zero (a zero before the decimal point) since the chi-square can be greater than zero.
- Provide two significant digits after the decimal point.
- Report the chi-square alongside its degrees of freedom , sample size, and p value , following this format: Χ 2 (degrees of freedom, N = sample size) = chi-square value, p = p value).
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Chi square test of independence
- Statistical power
- Descriptive statistics
- Degrees of freedom
- Pearson correlation
- Null hypothesis
Methodology
- Double-blind study
- Case-control study
- Research ethics
- Data collection
- Hypothesis testing
- Structured interviews
Research bias
- Hawthorne effect
- Unconscious bias
- Recall bias
- Halo effect
- Self-serving bias
- Information bias
The two main chi-square tests are the chi-square goodness of fit test and the chi-square test of independence .
Both chi-square tests and t tests can test for differences between two groups. However, a t test is used when you have a dependent quantitative variable and an independent categorical variable (with two groups). A chi-square test of independence is used when you have two categorical variables.
Both correlations and chi-square tests can test for relationships between two variables. However, a correlation is used when you have two quantitative variables and a chi-square test of independence is used when you have two categorical variables.
Quantitative variables are any variables where the data represent amounts (e.g. height, weight, or age).
Categorical variables are any variables where the data represent groups. This includes rankings (e.g. finishing places in a race), classifications (e.g. brands of cereal), and binary outcomes (e.g. coin flips).
You need to know what type of variables you are working with to choose the right statistical test for your data and interpret your results .
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Turney, S. (2023, June 22). Chi-Square (Χ²) Tests | Types, Formula & Examples. Scribbr. Retrieved August 14, 2024, from https://www.scribbr.com/statistics/chi-square-tests/
Is this article helpful?

Shaun Turney
Other students also liked, chi-square test of independence | formula, guide & examples, chi-square goodness of fit test | formula, guide & examples, chi-square (χ²) distributions | definition & examples, what is your plagiarism score.
- Skip to secondary menu
- Skip to main content
- Skip to primary sidebar
Statistics By Jim
Making statistics intuitive
How the Chi-Squared Test of Independence Works
By Jim Frost 21 Comments
Chi-squared tests of independence determine whether a relationship exists between two categorical variables . Do the values of one categorical variable depend on the value of the other categorical variable? If the two variables are independent, knowing the value of one variable provides no information about the value of the other variable.
I’ve previously written about Pearson’s chi-square test of independence using a fun Star Trek example . Are the uniform colors related to the chances of dying? You can test the notion that the infamous red shirts have a higher likelihood of dying. In that post, I focus on the purpose of the test, applied it to this example, and interpreted the results.
In this post, I’ll take a bit of a different approach. I’ll show you the nuts and bolts of how to calculate the expected values, chi-square value, and degrees of freedom. Then you’ll learn how to use the chi-squared distribution in conjunction with the degrees of freedom to calculate the p-value.
I’ve used the same approach to explain how:
- t-Tests work .
- F-tests work in one-way ANOVA .
Of course, you’ll usually just let your statistical software perform all calculations. However, understanding the underlying methodology helps you fully comprehend the analysis.
Chi-Squared Example Dataset
For the Star Trek example, uniform color and status are the two categorical variables. The contingency table below shows the combination of variable values, frequencies, and percentages.
| 7 | 9 | 24 | 40 | |
| 129 | 46 | 215 | 390 | |
| 136 | 55 | 239 | N = 430 | |
| 5.15% | 16.36% | 10.04% |

However, our fatality rates are not equal. Gold has the highest fatality rate at 16.36%, while Blue has the lowest at 5.15%. Red is in the middle at 10.04%. Does this inequality in our sample suggest that the fatality rates are different in the population? Does a relationship exist between uniform color and fatalities?
Thanks to random sampling error, our sample’s fatality rates don’t exactly equal the population’s rates. If the population rates are equal, we’d likely still see differences in our sample. So, the question becomes, after factoring in sampling error, are the fatality rates in our sample different enough to conclude that they’re different in the population? In other words, we want to be confident that the observed differences represent a relationship in the population rather than merely random fluctuations in the sample. That’s where Pearson’s chi-squared test for independence comes in!
Hypotheses for Our Test
The two hypotheses for the chi-squared test of independence are the following:
- Null : The variables are independent. No relationship exists.
- Alternative : A relationship between the variables exists.
Related posts : Hypothesis Testing Overview and Guide to Data Types
Calculating the Expected Frequencies for the Chi-squared Test of Independence
The chi-squared test of independence compares our sample data in the contingency table to the distribution of values we’d expect if the null hypothesis is correct. Let’s construct the contingency table we’d expect to see if the null hypothesis is true for our population.
For chi-squared tests, the term “expected frequencies” refers to the values we’d expect to see if the null hypothesis is true. To calculate the expected frequency for a specific combination of categorical variables (e.g., blue shirts who died), multiply the column total (Blue) by the row total (Dead), and divide by the sample size.
Row total X Column total / Sample Size = Expected value for one table cell
To calculate the expected frequency for the Dead/Blue cell in our dataset, do the following:
- Find the row total for Dead (40)
- Find the column total for Blue (136)
- Multiply those two values and divide by the sample size (430)
40 * 136 / 430 = 12.65
If the null hypothesis is true, we’d expect to see 12.65 fatalities for wearers of the Blue uniforms in our sample. Of course, we can’t have a fraction of a death, but that doesn’t affect the results.
Contingency Table with the Expected Values
I’ll calculate the expected values for all six cells that represent the combinations of the three uniform colors and two statuses. I’ll also include the observed values in our sample. Expected values are in parentheses.
| 7 (12.65) | 9 (5.12) | 24 (22.23) | 40 | |
| 129 (123.35) | 46 (49.88) | 215 (216.77) | 390 | |
| 9.3% | 9.3% | 9.3% |
In this table, notice how the column percentages for the expected dead are all 9.3%. This equality occurs when the null hypothesis is valid, which is the condition that the expected values represent.
Using this table, we can also compare the values we observe in our sample to the frequencies we’d expect if the null hypothesis that the variables are not related is correct.
For example, the observed frequency for Blue/Dead is less than the expected value (7 < 12.65). In our sample, deaths of those in blue uniforms occurred less frequently than we’d expect if the variables are independent. On the other hand, the observed frequency for Gold/Dead is greater than the expected value (9 > 5.12). Meanwhile, the observed frequency for Red/Dead approximately equals the expected value. This interpretation matches what we concluded by assessing the column percentages in the first contingency table.
Pearson’s chi-squared test works by mathematically comparing observed frequencies to the expected values and boiling all those differences down into one number. Let’s see how it does that!
Related post : Using Contingency Tables to Calculate Probabilities
Calculating the Chi-Squared Statistic
Most hypothesis tests calculate a test statistic. For example, t-tests use t-values and F-tests use F-values as their test statistics. These statistical tests compare your observed sample data to what you would expect if the null hypothesis is true. The calculations reduce your sample data down to one value that represents how different your data are from the null. Learn more about Test Statistics .
For chi-squared tests, the test statistic is, unsurprisingly, chi-squared, or χ 2 .
The chi-squared calculations involve a familiar concept in statistics—the sum of the squared differences between the observed and expected values. This concept is similar to how regression models assess goodness-of-fit using the sum of the squared differences.
Here’s the formula for chi-squared.

Let’s walk through it!
To calculate the chi-squared statistic, take the difference between a pair of observed (O) and expected values (E), square the difference, and divide that squared difference by the expected value. Repeat this process for all cells in your contingency table and sum those values. The resulting value is χ 2 . We’ll calculate it for our example data shortly!
Important Considerations about the Chi-Squared Statistic
Notice several important considerations about chi-squared values:
Zero represents the null hypothesis. If all your observed frequencies equal the expected frequencies exactly, the chi-squared value for each cell equals zero, and the overall chi-squared statistic equals zero. Zero indicates your sample data exactly match what you’d expect if the null hypothesis is correct.
Squaring the differences ensures both that cell values must be non-negative and that larger differences are weighted more than smaller differences. A cell can never subtract from the chi-squared value.
Larger values represent a greater difference between your sample data and the null hypothesis. Chi-squared tests are one-tailed tests rather than the more familiar two-tailed tests. The test determines whether the entire set of differences exceeds a significance threshold. If your χ 2 passes the limit, your results are statistically significant! You can reject the null hypothesis and conclude that the variables are dependent–a relationship exists.
Related post : One-tailed and Two-tailed Hypothesis Tests
Calculating Chi-Squared for our Example Data
Let’s calculate the chi-squared statistic for our example data! To do that, I’ll rearrange the contingency table, making it easier to illustrate how to calculate the sum of the squared differences.

The first two columns indicate the combination of categorical variable values. The next two are the observed and expected values that we calculated before. The last column is the squared difference divided by the expected value for each row. The bottom line sums those values.
Our chi-squared test statistic is 6.17. Ok, great. What does that mean? Larger values indicate a more substantial divergence between our observed data and the null hypothesis. However, the number by itself is not useful because we don’t know if it’s unusually large. We need to place it into a broader context to determine whether it is an extreme value.
Using the Chi-Squared Distribution to Test Hypotheses
One chi-squared test produces a single chi-squared value. However, imagine performing the following process.
First, assume the null hypothesis is valid for the population. At the population level, there is no relationship between the two categorical variables. Now, we’ll repeat our study many times by drawing many random samples from this population using the same design and sample size. Next, we perform the chi-squared test of independence on all the samples and plot the distribution of the chi-squared values. This distribution is known as a sampling distribution, which is a type of probability distribution.
If we follow this procedure, we create a graph that displays the distribution of chi-squared values for a population where the null hypothesis is true. We use sampling distributions to calculate probabilities for how unlikely our sample statistic is if the null hypothesis is correct. Chi-squared tests use the chi-square distribution.
Fortunately, we don’t need to collect many random samples to create this graph! Statisticians understand the properties of chi-squared distributions so we can estimate the sampling distribution using the details of our design.
Our goal is to determine whether our sample chi-squared value is so rare that it justifies rejecting the null hypothesis for the entire population. The chi-squared distribution provides the context for making that determination. We’ll calculate the probability of obtaining a chi-squared value that is at least as high as the value that our study found (6.17).
This probability has a name—the P-value! A low probability indicates that our sample data are unlikely when the null hypothesis is true.
Alternatively, you can use a chi-square table to determine whether our study’s chi-square test statistic exceeds the critical value .
Related posts : Sampling Distributions , Understanding Probability Distributions and Interpreting P-values
Graphing the Chi-Squared Test Results for Our Example
For chi-squared tests, the degrees of freedom define the shape of the chi-squared distribution for a design. Chi-square tests use this distribution to calculate p-values. The graph below displays several chi-square distributions with differing degrees of freedom.

For a table with r rows and c columns, the method for calculating degrees of freedom for a chi-square test is (r-1) (c-1). For our example, we have two rows and three columns: (2-1) * (3-1) = 2 df.
Read my post about degrees of freedom to learn about this concept along with a more intuitive way of understanding degrees of freedom in chi-squared tests of independence.
Below is the chi-squared distribution for our study’s design.

The distribution curve displays the likelihood of chi-squared values for a population where there is no relationship between uniform color and status at the population level. I shaded the region that corresponds to chi-square values greater than or equal to our study’s value (6.17). When the null hypothesis is correct, chi-square values fall in this area approximately 4.6% of the time, which is the p-value (0.046). With a significance level of 0.05, our sample data are unusual enough to reject the null hypothesis.
The sample evidence suggests that a relationship between the variables exists in the population. While this test doesn’t indicate red shirts have a higher chance of dying, there is something else going on with red shirts. Read my other post chi-squared to learn about that !
Related Reading
When you have smaller sample sizes, you might need to use Fisher’s exact test instead of the chi-square version. To learn more, read my post, Fisher’s Exact Test: Using and Interpreting .
Learn more about How to Find the P Value .
You can also read about the chi-square goodness of fit test , which assesses the distribution of outcomes for a categorical or discrete variable.
Pearson’s chi-squared test for independence doesn’t tell you the effect size. To understand the strength of the relationship, you’d need to use something like Cramér’s V, which is a measure of association like Pearson’s correlation —except for categorical variables. That’s the topic of a future post!
Share this:

Reader Interactions

November 15, 2021 at 1:56 pm
Jim – I want to start by saying that I love your site. It has helped me out greatly during many occasions. In this particular example I am interested in understanding the logic around the math for the expected values. For example, can you explain how I should interpret scaling the total number dead by the total number blue?
From there I get that we divide by the total number of people to get the number of blue deaths expected within the group of 430 people. Is this a formula that is well known for contingency tables or did you apply that strictly for this scenario?
Hopefully this question made sense?
Either way, thanks for the contributing to the community!

November 16, 2021 at 11:48 am
I’m so glad to hear that my site has been helpful!
I’m not 100% sure what you’re asking, so I’m not sure if I’m answering your question. To start, the formulas are the standard ones for the chi-squared test of independence, which you use in conjunction with contingency tables. You’d use the same methods and formulas for other datasets.
The portion you’re asking about is how to calculate the expected number for blue deaths if there is no association between uniform color and deaths (i.e., the null hypothesis of the test is true). So, the interpretation of the value is: If there is no relationship between uniform color and deaths, we’d expect 12.6 fatalities among those wearing blue uniforms. The test as a whole compares these expected values (for all table cells) to the observed values to determine whether the data support rejecting the null hypothesis and concluding that there is a relationship between the variables.

April 22, 2021 at 7:38 am
I teach AP Stat and am planning on using your example. However, in checking conditions I would like to be able to give background on the origin of the data. I went to your link and found that this data was collected for the TV episodes. Are those the episodes just for the original series?
April 23, 2021 at 11:21 pm
That’s great you’re teaching an AP Stats class! 🙂
Yes, the data I use are from the original TV series that aired from 1966-69.

July 5, 2020 at 12:34 pm
Thank you for your gracious reply. I’m especially happy because it meant that I actually understood! You’ve done a great service with this blog; I plan to return regularly! Thank you.
July 5, 2020 at 5:43 pm
I was think exactly that after fixing the comment. It would make a perfect comprehension test. Read this article and find the two incorrect letters! You passed! 🙂
July 4, 2020 at 9:13 am
I very much appreciate your clear explanations. I’m a “50 something” trying to finish a PhD in Library Science and my brain needs the help!
One question, please?
You write above:
Larger values represent a greater difference between your sample data and the null hypothesis. Chi-squared tests are one-tailed tests rather than the more familiar two-tailed tests. The test determines whether the entire set of differences exceeds a significance threshold. If your χ2 passes the limit, your results are statistically significant! You can reject the null hypothesis and conclude that the variables are independent.
I thought that rejecting the null hypothesis allowed you to conclude the opposite. If the null hypothesis is
Null: The variables are independent. No relationship exists.
Then rejecting the Null hypothesis means rejecting that the variables are independent, not concluding that the variables are independent.
This is, please, a honest question, (not being “that guy”; i’m not smart enough!).
Again, thank you for your work!! I’m going to check to see if you cover Kendall’s W, as it’s central to a paper I’m reading!
July 4, 2020 at 3:08 pm
First, I definitely welcome all questions! And, especially in this case because you caught a typo! You’re correct about what rejecting the null hypothesis means for this test. I’ve updated the text to say “and conclude that the variables are dependent.” I double-checked elsewhere through article and all the other text about the conclusions based on significance are correct. Just a brain malfunction on my part! I’m grateful you caught that as that little slip changes the entire meaning!
Alas, I don’t cover Kendall’s W–at least not yet. I plan to add that down the road.
April 28, 2020 at 7:28 pm
Thanks Jim. Your explanations are so effective, yet easy to understand!

April 26, 2020 at 8:54 pm
Thank you Jim. Great post and reply. I have a question which is an extension of Michael’s question.
In general, it seems like one could build any test statistic. Find the distribution of your statistic under the null (say using bootstrap), and that will give you a p-value for your dataset.
Are chi-squared, t, or F-statistics special in some way? Or do we continue to use them simply because people have used them historically?
April 27, 2020 at 12:31 am
Originally, hypothesis tests that used these distributions were easier to calculate. You could calculate the test statistic using a simple formula and then look it up in a table. Later, it got even easier when the computer could both calculate the test statistic and tell you its p-value. It’s really the ease of calculation that made them special along with the theories behind them.
Now, we have such powerful computers that they can easily construct very large sets of bootstrap samples. That would’ve been difficult earlier. So, a large part of the answer is that bootstrapping really wasn’t feasible earlier and so the use of the chi-squared, t, and F distributions became the norm. The historically accepted standards.
It’s possible that over time bootstrap methods will gain be used more. I haven’t done extensive research into how efficient they are compared to using the various distributions, but what I have done indicates they are at least roughly on par. If you haven’t, I’d suggest reading my post about bootstrapping for more information.
Thanks for asking the great question!

January 31, 2020 at 1:29 am
Nice explanation

January 30, 2020 at 4:21 am
This has started my year, so far so good, Thank you Jim.

January 29, 2020 at 1:32 am
great lesson thanks

January 28, 2020 at 9:24 pm
Thankyou Jim, I will read and calc this lesson today, at 3 o’clock Brasilia time.

January 28, 2020 at 4:40 am
Thank You Sir

January 27, 2020 at 8:49 am
Great post, thanks for writing it. I am looking forward to the Cramer’s V post!
As a person just starting to dive into statistics I am curios why we so often square the differences to make calculations. It seems squaring a difference will put to much weight on large differences. For example, in the chi-square test what if we used the absolute value of observed and expected differences? Just something I have been wondering about.
January 28, 2020 at 11:43 pm
Hi Michael,
There’s several ways of looking at your question. In some cases, if you just want to know how far observations are from the mean for a dataset, you would be justified using the mean absolute deviation rather than the standard deviation, which incorporates squared deviations but then takes the square root.
However, in other cases, the squared deviations are built into the underlying analysis. Such as in linear regression where it penalizes larger errors which helps force them to be smaller. Otherwise, the regression line would not “consider” larger errors to be much worse than smaller errors. Here’s an article about it in the regression context .
Or, if you’re working with the normal distribution and using it calculate probabilities or what not, that distribution has the mean and standard deviation as parameters. And the standard deviation incorporates squared differences. You could not work with the normal distribution using mean absolute deviations (MAD).
In a similar vein for chi-squared tests, you have to realize that the chi-squared distribution is based on squared differences. So, if you wanted to do a similar analysis but with the mean absolute deviation (MAD), you’d have to devise an entirely new test statistic and sampling distribution for it! You couldn’t just use the chi-squared distribution because that is specifically for these differences that use squaring. Same thing for F-tests which use ratios of variances, and variances are of course based on squared differences. Again, to use MAD for something like ANOVA, you’d need to come up with a new test statistic and sampling distribution!
But, the general reason is that squaring does weight large differences more heavily and that fits in with the rational that given a distribution of values, outlier values should be weighted more because they are relatively unlikely to occur so when they do it’s noteworthy. It makes those large differences between the expected and the observed more “odd.” And, some analyses use an underlying sampling distribution that is based on a test statistic calculated using squared differences in some fashion.

January 27, 2020 at 2:08 am
Thank you Jim.

January 27, 2020 at 1:12 am
Great lesson Jim! You’re putting it a very simple ways for non-statisticians. Thanks for sharing the knowledge!

January 26, 2020 at 8:32 pm
Thanks for sharing, Jim!
Comments and Questions Cancel reply
Teach yourself statistics
Chi-Square Test of Independence
This lesson explains how to conduct a chi-square test for independence . The test is applied when you have two categorical variables from a single population. It is used to determine whether there is a significant association between the two variables.
For example, in an election survey, voters might be classified by gender (male or female) and voting preference (Democrat, Republican, or Independent). We could use a chi-square test for independence to determine whether gender is related to voting preference. The sample problem at the end of the lesson considers this example.
When to Use Chi-Square Test for Independence
The test procedure described in this lesson is appropriate when the following conditions are met:
- The sampling method is simple random sampling .
- The variables under study are each categorical .
- If sample data are displayed in a contingency table , the expected frequency count for each cell of the table is at least 5.
This approach consists of four steps: (1) state the hypotheses, (2) formulate an analysis plan, (3) analyze sample data, and (4) interpret results.
State the Hypotheses
Suppose that Variable A has r levels, and Variable B has c levels. The null hypothesis states that knowing the level of Variable A does not help you predict the level of Variable B. That is, the variables are independent.
H o : Variable A and Variable B are independent.
H a : Variable A and Variable B are not independent.
The alternative hypothesis is that knowing the level of Variable A can help you predict the level of Variable B.
Note: Support for the alternative hypothesis suggests that the variables are related; but the relationship is not necessarily causal, in the sense that one variable "causes" the other.
Formulate an Analysis Plan
The analysis plan describes how to use sample data to accept or reject the null hypothesis. The plan should specify the following elements.
- Significance level. Often, researchers choose significance levels equal to 0.01, 0.05, or 0.10; but any value between 0 and 1 can be used.
- Test method. Use the chi-square test for independence to determine whether there is a significant relationship between two categorical variables.
Analyze Sample Data
Using sample data, find the degrees of freedom, expected frequencies, test statistic, and the P-value associated with the test statistic. The approach described in this section is illustrated in the sample problem at the end of this lesson.
DF = (r - 1) * (c - 1)
E r,c = (n r * n c ) / n
Χ 2 = Σ [ (O r,c - E r,c ) 2 / E r,c ]
- P-value. The P-value is the probability of observing a sample statistic as extreme as the test statistic. Since the test statistic is a chi-square, use the Chi-Square Distribution Calculator to assess the probability associated with the test statistic. Use the degrees of freedom computed above.
Interpret Results
If the sample findings are unlikely, given the null hypothesis, the researcher rejects the null hypothesis. Typically, this involves comparing the P-value to the significance level , and rejecting the null hypothesis when the P-value is less than the significance level.
Test Your Understanding
A public opinion poll surveyed a simple random sample of 1000 voters. Respondents were classified by gender (male or female) and by voting preference (Republican, Democrat, or Independent). Results are shown in the contingency table below.
| Voting Preferences | Row total | |||
|---|---|---|---|---|
| Rep | Dem | Ind | ||
| Male | 200 | 150 | 50 | 400 |
| Female | 250 | 300 | 50 | 600 |
| Column total | 450 | 450 | 100 | 1000 |
Is there a gender gap? Do the men's voting preferences differ significantly from the women's preferences? Use a 0.05 level of significance.
The solution to this problem takes four steps: (1) state the hypotheses, (2) formulate an analysis plan, (3) analyze sample data, and (4) interpret results. We work through those steps below:
H o : Gender and voting preferences are independent.
H a : Gender and voting preferences are not independent.
- Formulate an analysis plan . For this analysis, the significance level is 0.05. Using sample data, we will conduct a chi-square test for independence .
DF = (r - 1) * (c - 1) = (2 - 1) * (3 - 1) = 2
E r,c = (n r * n c ) / n E 1,1 = (400 * 450) / 1000 = 180000/1000 = 180 E 1,2 = (400 * 450) / 1000 = 180000/1000 = 180 E 1,3 = (400 * 100) / 1000 = 40000/1000 = 40 E 2,1 = (600 * 450) / 1000 = 270000/1000 = 270 E 2,2 = (600 * 450) / 1000 = 270000/1000 = 270 E 2,3 = (600 * 100) / 1000 = 60000/1000 = 60
Χ 2 = Σ [ (O r,c - E r,c ) 2 / E r,c ] Χ 2 = (200 - 180) 2 /180 + (150 - 180) 2 /180 + (50 - 40) 2 /40 + (250 - 270) 2 /270 + (300 - 270) 2 /270 + (50 - 60) 2 /60 Χ 2 = 400/180 + 900/180 + 100/40 + 400/270 + 900/270 + 100/60 Χ 2 = 2.22 + 5.00 + 2.50 + 1.48 + 3.33 + 1.67 = 16.2
where DF is the degrees of freedom, r is the number of levels of gender, c is the number of levels of the voting preference, n r is the number of observations from level r of gender, n c is the number of observations from level c of voting preference, n is the number of observations in the sample, E r,c is the expected frequency count when gender is level r and voting preference is level c , and O r,c is the observed frequency count when gender is level r voting preference is level c .
The P-value is the probability that a chi-square statistic having 2 degrees of freedom is more extreme than 16.2. We use the Chi-Square Distribution Calculator to find P(Χ 2 > 16.2) = 0.0003.
- Interpret results . Since the P-value (0.0003) is less than the significance level (0.05), we cannot accept the null hypothesis. Thus, we conclude that there is a relationship between gender and voting preference.
Note: If you use this approach on an exam, you may also want to mention why this approach is appropriate. Specifically, the approach is appropriate because the sampling method was simple random sampling, the variables under study were categorical, and the expected frequency count was at least 5 in each cell of the contingency table.
Hypothesis Testing - Chi Squared Test
Lisa Sullivan, PhD
Professor of Biostatistics
Boston University School of Public Health

Introduction
This module will continue the discussion of hypothesis testing, where a specific statement or hypothesis is generated about a population parameter, and sample statistics are used to assess the likelihood that the hypothesis is true. The hypothesis is based on available information and the investigator's belief about the population parameters. The specific tests considered here are called chi-square tests and are appropriate when the outcome is discrete (dichotomous, ordinal or categorical). For example, in some clinical trials the outcome is a classification such as hypertensive, pre-hypertensive or normotensive. We could use the same classification in an observational study such as the Framingham Heart Study to compare men and women in terms of their blood pressure status - again using the classification of hypertensive, pre-hypertensive or normotensive status.
The technique to analyze a discrete outcome uses what is called a chi-square test. Specifically, the test statistic follows a chi-square probability distribution. We will consider chi-square tests here with one, two and more than two independent comparison groups.
Learning Objectives
After completing this module, the student will be able to:
- Perform chi-square tests by hand
- Appropriately interpret results of chi-square tests
- Identify the appropriate hypothesis testing procedure based on type of outcome variable and number of samples
Tests with One Sample, Discrete Outcome
Here we consider hypothesis testing with a discrete outcome variable in a single population. Discrete variables are variables that take on more than two distinct responses or categories and the responses can be ordered or unordered (i.e., the outcome can be ordinal or categorical). The procedure we describe here can be used for dichotomous (exactly 2 response options), ordinal or categorical discrete outcomes and the objective is to compare the distribution of responses, or the proportions of participants in each response category, to a known distribution. The known distribution is derived from another study or report and it is again important in setting up the hypotheses that the comparator distribution specified in the null hypothesis is a fair comparison. The comparator is sometimes called an external or a historical control.
In one sample tests for a discrete outcome, we set up our hypotheses against an appropriate comparator. We select a sample and compute descriptive statistics on the sample data. Specifically, we compute the sample size (n) and the proportions of participants in each response
Test Statistic for Testing H 0 : p 1 = p 10 , p 2 = p 20 , ..., p k = p k0
We find the critical value in a table of probabilities for the chi-square distribution with degrees of freedom (df) = k-1. In the test statistic, O = observed frequency and E=expected frequency in each of the response categories. The observed frequencies are those observed in the sample and the expected frequencies are computed as described below. χ 2 (chi-square) is another probability distribution and ranges from 0 to ∞. The test above statistic formula above is appropriate for large samples, defined as expected frequencies of at least 5 in each of the response categories.
When we conduct a χ 2 test, we compare the observed frequencies in each response category to the frequencies we would expect if the null hypothesis were true. These expected frequencies are determined by allocating the sample to the response categories according to the distribution specified in H 0 . This is done by multiplying the observed sample size (n) by the proportions specified in the null hypothesis (p 10 , p 20 , ..., p k0 ). To ensure that the sample size is appropriate for the use of the test statistic above, we need to ensure that the following: min(np 10 , n p 20 , ..., n p k0 ) > 5.
The test of hypothesis with a discrete outcome measured in a single sample, where the goal is to assess whether the distribution of responses follows a known distribution, is called the χ 2 goodness-of-fit test. As the name indicates, the idea is to assess whether the pattern or distribution of responses in the sample "fits" a specified population (external or historical) distribution. In the next example we illustrate the test. As we work through the example, we provide additional details related to the use of this new test statistic.
A University conducted a survey of its recent graduates to collect demographic and health information for future planning purposes as well as to assess students' satisfaction with their undergraduate experiences. The survey revealed that a substantial proportion of students were not engaging in regular exercise, many felt their nutrition was poor and a substantial number were smoking. In response to a question on regular exercise, 60% of all graduates reported getting no regular exercise, 25% reported exercising sporadically and 15% reported exercising regularly as undergraduates. The next year the University launched a health promotion campaign on campus in an attempt to increase health behaviors among undergraduates. The program included modules on exercise, nutrition and smoking cessation. To evaluate the impact of the program, the University again surveyed graduates and asked the same questions. The survey was completed by 470 graduates and the following data were collected on the exercise question:
|
|
|
|
|
|
| Number of Students | 255 | 125 | 90 | 470 |
Based on the data, is there evidence of a shift in the distribution of responses to the exercise question following the implementation of the health promotion campaign on campus? Run the test at a 5% level of significance.
In this example, we have one sample and a discrete (ordinal) outcome variable (with three response options). We specifically want to compare the distribution of responses in the sample to the distribution reported the previous year (i.e., 60%, 25%, 15% reporting no, sporadic and regular exercise, respectively). We now run the test using the five-step approach.
- Step 1. Set up hypotheses and determine level of significance.
The null hypothesis again represents the "no change" or "no difference" situation. If the health promotion campaign has no impact then we expect the distribution of responses to the exercise question to be the same as that measured prior to the implementation of the program.
H 0 : p 1 =0.60, p 2 =0.25, p 3 =0.15, or equivalently H 0 : Distribution of responses is 0.60, 0.25, 0.15
H 1 : H 0 is false. α =0.05
Notice that the research hypothesis is written in words rather than in symbols. The research hypothesis as stated captures any difference in the distribution of responses from that specified in the null hypothesis. We do not specify a specific alternative distribution, instead we are testing whether the sample data "fit" the distribution in H 0 or not. With the χ 2 goodness-of-fit test there is no upper or lower tailed version of the test.
- Step 2. Select the appropriate test statistic.
The test statistic is:
We must first assess whether the sample size is adequate. Specifically, we need to check min(np 0 , np 1, ..., n p k ) > 5. The sample size here is n=470 and the proportions specified in the null hypothesis are 0.60, 0.25 and 0.15. Thus, min( 470(0.65), 470(0.25), 470(0.15))=min(282, 117.5, 70.5)=70.5. The sample size is more than adequate so the formula can be used.
- Step 3. Set up decision rule.
The decision rule for the χ 2 test depends on the level of significance and the degrees of freedom, defined as degrees of freedom (df) = k-1 (where k is the number of response categories). If the null hypothesis is true, the observed and expected frequencies will be close in value and the χ 2 statistic will be close to zero. If the null hypothesis is false, then the χ 2 statistic will be large. Critical values can be found in a table of probabilities for the χ 2 distribution. Here we have df=k-1=3-1=2 and a 5% level of significance. The appropriate critical value is 5.99, and the decision rule is as follows: Reject H 0 if χ 2 > 5.99.
- Step 4. Compute the test statistic.
We now compute the expected frequencies using the sample size and the proportions specified in the null hypothesis. We then substitute the sample data (observed frequencies) and the expected frequencies into the formula for the test statistic identified in Step 2. The computations can be organized as follows.
|
|
|
|
|
|
|---|---|---|---|---|
|
| 255 | 125 | 90 | 470 |
|
| 470(0.60) =282 | 470(0.25) =117.5 | 470(0.15) =70.5 | 470 |
Notice that the expected frequencies are taken to one decimal place and that the sum of the observed frequencies is equal to the sum of the expected frequencies. The test statistic is computed as follows:
- Step 5. Conclusion.
We reject H 0 because 8.46 > 5.99. We have statistically significant evidence at α=0.05 to show that H 0 is false, or that the distribution of responses is not 0.60, 0.25, 0.15. The p-value is p < 0.005.
In the χ 2 goodness-of-fit test, we conclude that either the distribution specified in H 0 is false (when we reject H 0 ) or that we do not have sufficient evidence to show that the distribution specified in H 0 is false (when we fail to reject H 0 ). Here, we reject H 0 and concluded that the distribution of responses to the exercise question following the implementation of the health promotion campaign was not the same as the distribution prior. The test itself does not provide details of how the distribution has shifted. A comparison of the observed and expected frequencies will provide some insight into the shift (when the null hypothesis is rejected). Does it appear that the health promotion campaign was effective?
Consider the following:
|
|
|
|
|
|
|---|---|---|---|---|
|
| 255 | 125 | 90 | 470 |
|
| 282 | 117.5 | 70.5 | 470 |
If the null hypothesis were true (i.e., no change from the prior year) we would have expected more students to fall in the "No Regular Exercise" category and fewer in the "Regular Exercise" categories. In the sample, 255/470 = 54% reported no regular exercise and 90/470=19% reported regular exercise. Thus, there is a shift toward more regular exercise following the implementation of the health promotion campaign. There is evidence of a statistical difference, is this a meaningful difference? Is there room for improvement?
The National Center for Health Statistics (NCHS) provided data on the distribution of weight (in categories) among Americans in 2002. The distribution was based on specific values of body mass index (BMI) computed as weight in kilograms over height in meters squared. Underweight was defined as BMI< 18.5, Normal weight as BMI between 18.5 and 24.9, overweight as BMI between 25 and 29.9 and obese as BMI of 30 or greater. Americans in 2002 were distributed as follows: 2% Underweight, 39% Normal Weight, 36% Overweight, and 23% Obese. Suppose we want to assess whether the distribution of BMI is different in the Framingham Offspring sample. Using data from the n=3,326 participants who attended the seventh examination of the Offspring in the Framingham Heart Study we created the BMI categories as defined and observed the following:
|
|
|
|
|
30 |
|
|---|---|---|---|---|---|
|
| 20 | 932 | 1374 | 1000 | 3326 |
- Step 1. Set up hypotheses and determine level of significance.
H 0 : p 1 =0.02, p 2 =0.39, p 3 =0.36, p 4 =0.23 or equivalently
H 0 : Distribution of responses is 0.02, 0.39, 0.36, 0.23
H 1 : H 0 is false. α=0.05
The formula for the test statistic is:
We must assess whether the sample size is adequate. Specifically, we need to check min(np 0 , np 1, ..., n p k ) > 5. The sample size here is n=3,326 and the proportions specified in the null hypothesis are 0.02, 0.39, 0.36 and 0.23. Thus, min( 3326(0.02), 3326(0.39), 3326(0.36), 3326(0.23))=min(66.5, 1297.1, 1197.4, 765.0)=66.5. The sample size is more than adequate, so the formula can be used.
Here we have df=k-1=4-1=3 and a 5% level of significance. The appropriate critical value is 7.81 and the decision rule is as follows: Reject H 0 if χ 2 > 7.81.
We now compute the expected frequencies using the sample size and the proportions specified in the null hypothesis. We then substitute the sample data (observed frequencies) into the formula for the test statistic identified in Step 2. We organize the computations in the following table.
|
|
|
|
|
30 |
|
|---|---|---|---|---|---|
|
| 20 | 932 | 1374 | 1000 | 3326 |
|
| 66.5 | 1297.1 | 1197.4 | 765.0 | 3326 |
The test statistic is computed as follows:
We reject H 0 because 233.53 > 7.81. We have statistically significant evidence at α=0.05 to show that H 0 is false or that the distribution of BMI in Framingham is different from the national data reported in 2002, p < 0.005.
Again, the χ 2 goodness-of-fit test allows us to assess whether the distribution of responses "fits" a specified distribution. Here we show that the distribution of BMI in the Framingham Offspring Study is different from the national distribution. To understand the nature of the difference we can compare observed and expected frequencies or observed and expected proportions (or percentages). The frequencies are large because of the large sample size, the observed percentages of patients in the Framingham sample are as follows: 0.6% underweight, 28% normal weight, 41% overweight and 30% obese. In the Framingham Offspring sample there are higher percentages of overweight and obese persons (41% and 30% in Framingham as compared to 36% and 23% in the national data), and lower proportions of underweight and normal weight persons (0.6% and 28% in Framingham as compared to 2% and 39% in the national data). Are these meaningful differences?
In the module on hypothesis testing for means and proportions, we discussed hypothesis testing applications with a dichotomous outcome variable in a single population. We presented a test using a test statistic Z to test whether an observed (sample) proportion differed significantly from a historical or external comparator. The chi-square goodness-of-fit test can also be used with a dichotomous outcome and the results are mathematically equivalent.
In the prior module, we considered the following example. Here we show the equivalence to the chi-square goodness-of-fit test.
The NCHS report indicated that in 2002, 75% of children aged 2 to 17 saw a dentist in the past year. An investigator wants to assess whether use of dental services is similar in children living in the city of Boston. A sample of 125 children aged 2 to 17 living in Boston are surveyed and 64 reported seeing a dentist over the past 12 months. Is there a significant difference in use of dental services between children living in Boston and the national data?
We presented the following approach to the test using a Z statistic.
- Step 1. Set up hypotheses and determine level of significance
H 0 : p = 0.75
H 1 : p ≠ 0.75 α=0.05
We must first check that the sample size is adequate. Specifically, we need to check min(np 0 , n(1-p 0 )) = min( 125(0.75), 125(1-0.75))=min(94, 31)=31. The sample size is more than adequate so the following formula can be used
This is a two-tailed test, using a Z statistic and a 5% level of significance. Reject H 0 if Z < -1.960 or if Z > 1.960.
We now substitute the sample data into the formula for the test statistic identified in Step 2. The sample proportion is:
We reject H 0 because -6.15 < -1.960. We have statistically significant evidence at a =0.05 to show that there is a statistically significant difference in the use of dental service by children living in Boston as compared to the national data. (p < 0.0001).
We now conduct the same test using the chi-square goodness-of-fit test. First, we summarize our sample data as follows:
|
| Saw a Dentist in Past 12 Months | Did Not See a Dentist in Past 12 Months | Total |
|---|---|---|---|
| # of Participants | 64 | 61 | 125 |
H 0 : p 1 =0.75, p 2 =0.25 or equivalently H 0 : Distribution of responses is 0.75, 0.25
We must assess whether the sample size is adequate. Specifically, we need to check min(np 0 , np 1, ...,np k >) > 5. The sample size here is n=125 and the proportions specified in the null hypothesis are 0.75, 0.25. Thus, min( 125(0.75), 125(0.25))=min(93.75, 31.25)=31.25. The sample size is more than adequate so the formula can be used.
Here we have df=k-1=2-1=1 and a 5% level of significance. The appropriate critical value is 3.84, and the decision rule is as follows: Reject H 0 if χ 2 > 3.84. (Note that 1.96 2 = 3.84, where 1.96 was the critical value used in the Z test for proportions shown above.)
|
|
|
|
|
|---|---|---|---|
|
| 64 | 61 | 125 |
|
| 93.75 | 31.25 | 125 |
(Note that (-6.15) 2 = 37.8, where -6.15 was the value of the Z statistic in the test for proportions shown above.)
We reject H 0 because 37.8 > 3.84. We have statistically significant evidence at α=0.05 to show that there is a statistically significant difference in the use of dental service by children living in Boston as compared to the national data. (p < 0.0001). This is the same conclusion we reached when we conducted the test using the Z test above. With a dichotomous outcome, Z 2 = χ 2 ! In statistics, there are often several approaches that can be used to test hypotheses.
Tests for Two or More Independent Samples, Discrete Outcome
Here we extend that application of the chi-square test to the case with two or more independent comparison groups. Specifically, the outcome of interest is discrete with two or more responses and the responses can be ordered or unordered (i.e., the outcome can be dichotomous, ordinal or categorical). We now consider the situation where there are two or more independent comparison groups and the goal of the analysis is to compare the distribution of responses to the discrete outcome variable among several independent comparison groups.
The test is called the χ 2 test of independence and the null hypothesis is that there is no difference in the distribution of responses to the outcome across comparison groups. This is often stated as follows: The outcome variable and the grouping variable (e.g., the comparison treatments or comparison groups) are independent (hence the name of the test). Independence here implies homogeneity in the distribution of the outcome among comparison groups.
The null hypothesis in the χ 2 test of independence is often stated in words as: H 0 : The distribution of the outcome is independent of the groups. The alternative or research hypothesis is that there is a difference in the distribution of responses to the outcome variable among the comparison groups (i.e., that the distribution of responses "depends" on the group). In order to test the hypothesis, we measure the discrete outcome variable in each participant in each comparison group. The data of interest are the observed frequencies (or number of participants in each response category in each group). The formula for the test statistic for the χ 2 test of independence is given below.
Test Statistic for Testing H 0 : Distribution of outcome is independent of groups
and we find the critical value in a table of probabilities for the chi-square distribution with df=(r-1)*(c-1).
Here O = observed frequency, E=expected frequency in each of the response categories in each group, r = the number of rows in the two-way table and c = the number of columns in the two-way table. r and c correspond to the number of comparison groups and the number of response options in the outcome (see below for more details). The observed frequencies are the sample data and the expected frequencies are computed as described below. The test statistic is appropriate for large samples, defined as expected frequencies of at least 5 in each of the response categories in each group.
The data for the χ 2 test of independence are organized in a two-way table. The outcome and grouping variable are shown in the rows and columns of the table. The sample table below illustrates the data layout. The table entries (blank below) are the numbers of participants in each group responding to each response category of the outcome variable.
Table - Possible outcomes are are listed in the columns; The groups being compared are listed in rows.
|
|
|
| |||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| N |
In the table above, the grouping variable is shown in the rows of the table; r denotes the number of independent groups. The outcome variable is shown in the columns of the table; c denotes the number of response options in the outcome variable. Each combination of a row (group) and column (response) is called a cell of the table. The table has r*c cells and is sometimes called an r x c ("r by c") table. For example, if there are 4 groups and 5 categories in the outcome variable, the data are organized in a 4 X 5 table. The row and column totals are shown along the right-hand margin and the bottom of the table, respectively. The total sample size, N, can be computed by summing the row totals or the column totals. Similar to ANOVA, N does not refer to a population size here but rather to the total sample size in the analysis. The sample data can be organized into a table like the above. The numbers of participants within each group who select each response option are shown in the cells of the table and these are the observed frequencies used in the test statistic.
The test statistic for the χ 2 test of independence involves comparing observed (sample data) and expected frequencies in each cell of the table. The expected frequencies are computed assuming that the null hypothesis is true. The null hypothesis states that the two variables (the grouping variable and the outcome) are independent. The definition of independence is as follows:
Two events, A and B, are independent if P(A|B) = P(A), or equivalently, if P(A and B) = P(A) P(B).
The second statement indicates that if two events, A and B, are independent then the probability of their intersection can be computed by multiplying the probability of each individual event. To conduct the χ 2 test of independence, we need to compute expected frequencies in each cell of the table. Expected frequencies are computed by assuming that the grouping variable and outcome are independent (i.e., under the null hypothesis). Thus, if the null hypothesis is true, using the definition of independence:
P(Group 1 and Response Option 1) = P(Group 1) P(Response Option 1).
The above states that the probability that an individual is in Group 1 and their outcome is Response Option 1 is computed by multiplying the probability that person is in Group 1 by the probability that a person is in Response Option 1. To conduct the χ 2 test of independence, we need expected frequencies and not expected probabilities . To convert the above probability to a frequency, we multiply by N. Consider the following small example.
|
|
|
|
|
|
|---|---|---|---|---|
|
| 10 | 8 | 7 | 25 |
|
| 22 | 15 | 13 | 50 |
|
| 30 | 28 | 17 | 75 |
|
| 62 | 51 | 37 | 150 |
The data shown above are measured in a sample of size N=150. The frequencies in the cells of the table are the observed frequencies. If Group and Response are independent, then we can compute the probability that a person in the sample is in Group 1 and Response category 1 using:
P(Group 1 and Response 1) = P(Group 1) P(Response 1),
P(Group 1 and Response 1) = (25/150) (62/150) = 0.069.
Thus if Group and Response are independent we would expect 6.9% of the sample to be in the top left cell of the table (Group 1 and Response 1). The expected frequency is 150(0.069) = 10.4. We could do the same for Group 2 and Response 1:
P(Group 2 and Response 1) = P(Group 2) P(Response 1),
P(Group 2 and Response 1) = (50/150) (62/150) = 0.138.
The expected frequency in Group 2 and Response 1 is 150(0.138) = 20.7.
Thus, the formula for determining the expected cell frequencies in the χ 2 test of independence is as follows:
Expected Cell Frequency = (Row Total * Column Total)/N.
The above computes the expected frequency in one step rather than computing the expected probability first and then converting to a frequency.
In a prior example we evaluated data from a survey of university graduates which assessed, among other things, how frequently they exercised. The survey was completed by 470 graduates. In the prior example we used the χ 2 goodness-of-fit test to assess whether there was a shift in the distribution of responses to the exercise question following the implementation of a health promotion campaign on campus. We specifically considered one sample (all students) and compared the observed distribution to the distribution of responses the prior year (a historical control). Suppose we now wish to assess whether there is a relationship between exercise on campus and students' living arrangements. As part of the same survey, graduates were asked where they lived their senior year. The response options were dormitory, on-campus apartment, off-campus apartment, and at home (i.e., commuted to and from the university). The data are shown below.
|
|
|
|
|
|
|---|---|---|---|---|
|
| 32 | 30 | 28 | 90 |
|
| 74 | 64 | 42 | 180 |
|
| 110 | 25 | 15 | 150 |
|
| 39 | 6 | 5 | 50 |
|
| 255 | 125 | 90 | 470 |
Based on the data, is there a relationship between exercise and student's living arrangement? Do you think where a person lives affect their exercise status? Here we have four independent comparison groups (living arrangement) and a discrete (ordinal) outcome variable with three response options. We specifically want to test whether living arrangement and exercise are independent. We will run the test using the five-step approach.
H 0 : Living arrangement and exercise are independent
H 1 : H 0 is false. α=0.05
The null and research hypotheses are written in words rather than in symbols. The research hypothesis is that the grouping variable (living arrangement) and the outcome variable (exercise) are dependent or related.
- Step 2. Select the appropriate test statistic.
The condition for appropriate use of the above test statistic is that each expected frequency is at least 5. In Step 4 we will compute the expected frequencies and we will ensure that the condition is met.
The decision rule depends on the level of significance and the degrees of freedom, defined as df = (r-1)(c-1), where r and c are the numbers of rows and columns in the two-way data table. The row variable is the living arrangement and there are 4 arrangements considered, thus r=4. The column variable is exercise and 3 responses are considered, thus c=3. For this test, df=(4-1)(3-1)=3(2)=6. Again, with χ 2 tests there are no upper, lower or two-tailed tests. If the null hypothesis is true, the observed and expected frequencies will be close in value and the χ 2 statistic will be close to zero. If the null hypothesis is false, then the χ 2 statistic will be large. The rejection region for the χ 2 test of independence is always in the upper (right-hand) tail of the distribution. For df=6 and a 5% level of significance, the appropriate critical value is 12.59 and the decision rule is as follows: Reject H 0 if c 2 > 12.59.
We now compute the expected frequencies using the formula,
Expected Frequency = (Row Total * Column Total)/N.
The computations can be organized in a two-way table. The top number in each cell of the table is the observed frequency and the bottom number is the expected frequency. The expected frequencies are shown in parentheses.
|
|
|
|
|
|
|---|---|---|---|---|
|
| 32 (48.8) | 30 (23.9) | 28 (17.2) | 90 |
|
| 74 (97.7) | 64 (47.9) | 42 (34.5) | 180 |
|
| 110 (81.4) | 25 (39.9) | 15 (28.7) | 150 |
|
| 39 (27.1) | 6 (13.3) | 5 (9.6) | 50 |
|
| 255 | 125 | 90 | 470 |
Notice that the expected frequencies are taken to one decimal place and that the sums of the observed frequencies are equal to the sums of the expected frequencies in each row and column of the table.
Recall in Step 2 a condition for the appropriate use of the test statistic was that each expected frequency is at least 5. This is true for this sample (the smallest expected frequency is 9.6) and therefore it is appropriate to use the test statistic.
We reject H 0 because 60.5 > 12.59. We have statistically significant evidence at a =0.05 to show that H 0 is false or that living arrangement and exercise are not independent (i.e., they are dependent or related), p < 0.005.
Again, the χ 2 test of independence is used to test whether the distribution of the outcome variable is similar across the comparison groups. Here we rejected H 0 and concluded that the distribution of exercise is not independent of living arrangement, or that there is a relationship between living arrangement and exercise. The test provides an overall assessment of statistical significance. When the null hypothesis is rejected, it is important to review the sample data to understand the nature of the relationship. Consider again the sample data.
Because there are different numbers of students in each living situation, it makes the comparisons of exercise patterns difficult on the basis of the frequencies alone. The following table displays the percentages of students in each exercise category by living arrangement. The percentages sum to 100% in each row of the table. For comparison purposes, percentages are also shown for the total sample along the bottom row of the table.
|
|
|
|
|
|---|---|---|---|
|
| 36% | 33% | 31% |
|
| 41% | 36% | 23% |
|
| 73% | 17% | 10% |
|
| 78% | 12% | 10% |
|
| 54% | 27% | 19% |
From the above, it is clear that higher percentages of students living in dormitories and in on-campus apartments reported regular exercise (31% and 23%) as compared to students living in off-campus apartments and at home (10% each).
Test Yourself
Pancreaticoduodenectomy (PD) is a procedure that is associated with considerable morbidity. A study was recently conducted on 553 patients who had a successful PD between January 2000 and December 2010 to determine whether their Surgical Apgar Score (SAS) is related to 30-day perioperative morbidity and mortality. The table below gives the number of patients experiencing no, minor, or major morbidity by SAS category.
|
|
|
|
|
|---|---|---|---|
| 0-4 | 21 | 20 | 16 |
| 5-6 | 135 | 71 | 35 |
| 7-10 | 158 | 62 | 35 |
Question: What would be an appropriate statistical test to examine whether there is an association between Surgical Apgar Score and patient outcome? Using 14.13 as the value of the test statistic for these data, carry out the appropriate test at a 5% level of significance. Show all parts of your test.
In the module on hypothesis testing for means and proportions, we discussed hypothesis testing applications with a dichotomous outcome variable and two independent comparison groups. We presented a test using a test statistic Z to test for equality of independent proportions. The chi-square test of independence can also be used with a dichotomous outcome and the results are mathematically equivalent.
In the prior module, we considered the following example. Here we show the equivalence to the chi-square test of independence.
A randomized trial is designed to evaluate the effectiveness of a newly developed pain reliever designed to reduce pain in patients following joint replacement surgery. The trial compares the new pain reliever to the pain reliever currently in use (called the standard of care). A total of 100 patients undergoing joint replacement surgery agreed to participate in the trial. Patients were randomly assigned to receive either the new pain reliever or the standard pain reliever following surgery and were blind to the treatment assignment. Before receiving the assigned treatment, patients were asked to rate their pain on a scale of 0-10 with higher scores indicative of more pain. Each patient was then given the assigned treatment and after 30 minutes was again asked to rate their pain on the same scale. The primary outcome was a reduction in pain of 3 or more scale points (defined by clinicians as a clinically meaningful reduction). The following data were observed in the trial.
|
|
|
|
|
|---|---|---|---|
|
| 50 | 23 | 0.46 |
|
| 50 | 11 | 0.22 |
We tested whether there was a significant difference in the proportions of patients reporting a meaningful reduction (i.e., a reduction of 3 or more scale points) using a Z statistic, as follows.
H 0 : p 1 = p 2
H 1 : p 1 ≠ p 2 α=0.05
Here the new or experimental pain reliever is group 1 and the standard pain reliever is group 2.
We must first check that the sample size is adequate. Specifically, we need to ensure that we have at least 5 successes and 5 failures in each comparison group or that:
In this example, we have
Therefore, the sample size is adequate, so the following formula can be used:
Reject H 0 if Z < -1.960 or if Z > 1.960.
We now substitute the sample data into the formula for the test statistic identified in Step 2. We first compute the overall proportion of successes:
We now substitute to compute the test statistic.
- Step 5. Conclusion.
We now conduct the same test using the chi-square test of independence.
H 0 : Treatment and outcome (meaningful reduction in pain) are independent
H 1 : H 0 is false. α=0.05
The formula for the test statistic is:
For this test, df=(2-1)(2-1)=1. At a 5% level of significance, the appropriate critical value is 3.84 and the decision rule is as follows: Reject H0 if χ 2 > 3.84. (Note that 1.96 2 = 3.84, where 1.96 was the critical value used in the Z test for proportions shown above.)
We now compute the expected frequencies using:
The computations can be organized in a two-way table. The top number in each cell of the table is the observed frequency and the bottom number is the expected frequency. The expected frequencies are shown in parentheses.
|
|
|
|
|
|---|---|---|---|
|
| 23 (17.0) | 27 (33.0) | 50 |
|
| 11 (17.0) | 39 (33.0) | 50 |
|
| 34 | 66 | 100 |
A condition for the appropriate use of the test statistic was that each expected frequency is at least 5. This is true for this sample (the smallest expected frequency is 22.0) and therefore it is appropriate to use the test statistic.
(Note that (2.53) 2 = 6.4, where 2.53 was the value of the Z statistic in the test for proportions shown above.)
Chi-Squared Tests in R
The video below by Mike Marin demonstrates how to perform chi-squared tests in the R programming language.
Answer to Problem on Pancreaticoduodenectomy and Surgical Apgar Scores
We have 3 independent comparison groups (Surgical Apgar Score) and a categorical outcome variable (morbidity/mortality). We can run a Chi-Squared test of independence.
H 0 : Apgar scores and patient outcome are independent of one another.
H A : Apgar scores and patient outcome are not independent.
Chi-squared = 14.3
Since 14.3 is greater than 9.49, we reject H 0.
There is an association between Apgar scores and patient outcome. The lowest Apgar score group (0 to 4) experienced the highest percentage of major morbidity or mortality (16 out of 57=28%) compared to the other Apgar score groups.
Chi-Square Test of Independence
The Chi-Square test of independence is used to determine if there is a significant relationship between two nominal (categorical) variables. The frequency of each category for one nominal variable is compared across the categories of the second nominal variable. The data can be displayed in a contingency table where each row represents a category for one variable and each column represents a category for the other variable. For example, say a researcher wants to examine the relationship between gender (male vs. female) and empathy (high vs. low). The chi-square test of independence can be used to examine this relationship. The null hypothesis for this test is that there is no relationship between gender and empathy. The alternative hypothesis is that there is a relationship between gender and empathy (e.g. there are more high-empathy females than high-empathy males).
Calculate Chi Square Statistic by Hand
First we have to calculate the expected value of the two nominal variables. We can calculate the expected value of the two nominal variables by using this formula:

N = total number
After calculating the expected value, we will apply the following formula to calculate the value of the Chi-Square test of Independence:

Degree of freedom is calculated by using the following formula: DF = (r-1)(c-1) Where DF = Degree of freedom r = number of rows c = number of columns
Need assistance with your research?
Schedule a time to speak with an expert using the calendar below.
Transform raw data to written interpreted results in seconds.
Null hypothesis: Assumes that there is no association between the two variables.
Alternative hypothesis: Assumes that there is an association between the two variables.
Hypothesis testing: Hypothesis testing for the chi-square test of independence as it is for other tests like ANOVA , where a test statistic is computed and compared to a critical value. The critical value for the chi-square statistic is determined by the level of significance (typically .05) and the degrees of freedom. The degrees of freedom for the chi-square are calculated using the following formula: df = (r-1)(c-1) where r is the number of rows and c is the number of columns. If the observed chi-square test statistic is greater than the critical value, the null hypothesis can be rejected.
Related Pages:
- Conduct and Interpret the Chi-Square Test of Independence
- Test of Independence: degrees of freedom
- Take the course: Chi Square Test of Independence
Statistics Solutions can assist with your quantitative analysis by assisting you to develop your methodology and results chapters. The services that we offer include:
Data Analysis Plan
- Edit your research questions and null/alternative hypotheses
- Write your data analysis plan; specify specific statistics to address the research questions, the assumptions of the statistics, and justify why they are the appropriate statistics; provide references
- Justify your sample size/power analysis, provide references
- Explain your data analysis plan to you so you are comfortable and confident
- Two hours of additional support with your statistician
Quantitative Results Section (Descriptive Statistics, Bivariate and Multivariate Analyses, Structural Equation Modeling , Path analysis, HLM, Cluster Analysis )
- Clean and code dataset
- Conduct descriptive statistics (i.e., mean, standard deviation, frequency and percent, as appropriate)
- Conduct analyses to examine each of your research questions
- Write-up results
- Provide APA 7 th edition tables and figures
- Explain Chapter 4 findings
- Ongoing support for entire results chapter statistics
Please call 727-442-4290 to request a quote based on the specifics of your research, schedule using the calendar on this page, or email [email protected]
- Flashes Safe Seven
- FlashLine Login
- Faculty & Staff Phone Directory
- Emeriti or Retiree
- All Departments
- Maps & Directions

- Building Guide
- Departments
- Directions & Parking
- Faculty & Staff
- Give to University Libraries
- Library Instructional Spaces
- Mission & Vision
- Newsletters
- Circulation
- Course Reserves / Core Textbooks
- Equipment for Checkout
- Interlibrary Loan
- Library Instruction
- Library Tutorials
- My Library Account
- Open Access Kent State
- Research Support Services
- Statistical Consulting
- Student Multimedia Studio
- Citation Tools
- Databases A-to-Z
- Databases By Subject
- Digital Collections
- Discovery@Kent State
- Government Information
- Journal Finder
- Library Guides
- Connect from Off-Campus
- Library Workshops
- Subject Librarians Directory
- Suggestions/Feedback
- Writing Commons
- Academic Integrity
- Jobs for Students
- International Students
- Meet with a Librarian
- Study Spaces
- University Libraries Student Scholarship
- Affordable Course Materials
- Copyright Services
- Selection Manager
- Suggest a Purchase
Library Locations at the Kent Campus
- Architecture Library
- Fashion Library
- Map Library
- Performing Arts Library
- Special Collections and Archives
Regional Campus Libraries
- East Liverpool
- College of Podiatric Medicine
- Kent State University
- SPSS Tutorials
Chi-Square Test of Independence
Spss tutorials: chi-square test of independence.
- The SPSS Environment
- The Data View Window
- Using SPSS Syntax
- Data Creation in SPSS
- Importing Data into SPSS
- Variable Types
- Date-Time Variables in SPSS
- Defining Variables
- Creating a Codebook
- Computing Variables
- Computing Variables: Mean Centering
- Computing Variables: Recoding Categorical Variables
- Computing Variables: Recoding String Variables into Coded Categories (Automatic Recode)
- rank transform converts a set of data values by ordering them from smallest to largest, and then assigning a rank to each value. In SPSS, the Rank Cases procedure can be used to compute the rank transform of a variable." href="https://libguides.library.kent.edu/SPSS/RankCases" style="" >Computing Variables: Rank Transforms (Rank Cases)
- Weighting Cases
- Sorting Data
- Grouping Data
- Descriptive Stats for One Numeric Variable (Explore)
- Descriptive Stats for One Numeric Variable (Frequencies)
- Descriptive Stats for Many Numeric Variables (Descriptives)
- Descriptive Stats by Group (Compare Means)
- Frequency Tables
- Working with "Check All That Apply" Survey Data (Multiple Response Sets)
- Pearson Correlation
- One Sample t Test
- Paired Samples t Test
- Independent Samples t Test
- One-Way ANOVA
- How to Cite the Tutorials
Sample Data Files
Our tutorials reference a dataset called "sample" in many examples. If you'd like to download the sample dataset to work through the examples, choose one of the files below:
- Data definitions (*.pdf)
- Data - Comma delimited (*.csv)
- Data - Tab delimited (*.txt)
- Data - Excel format (*.xlsx)
- Data - SAS format (*.sas7bdat)
- Data - SPSS format (*.sav)
- SPSS Syntax (*.sps) Syntax to add variable labels, value labels, set variable types, and compute several recoded variables used in later tutorials.
- SAS Syntax (*.sas) Syntax to read the CSV-format sample data and set variable labels and formats/value labels.
The Chi-Square Test of Independence determines whether there is an association between categorical variables (i.e., whether the variables are independent or related). It is a nonparametric test.
This test is also known as:
- Chi-Square Test of Association.
This test utilizes a contingency table to analyze the data. A contingency table (also known as a cross-tabulation , crosstab , or two-way table ) is an arrangement in which data is classified according to two categorical variables. The categories for one variable appear in the rows, and the categories for the other variable appear in columns. Each variable must have two or more categories. Each cell reflects the total count of cases for a specific pair of categories.
There are several tests that go by the name "chi-square test" in addition to the Chi-Square Test of Independence. Look for context clues in the data and research question to make sure what form of the chi-square test is being used.
Common Uses
The Chi-Square Test of Independence is commonly used to test the following:
- Statistical independence or association between two categorical variables.
The Chi-Square Test of Independence can only compare categorical variables. It cannot make comparisons between continuous variables or between categorical and continuous variables. Additionally, the Chi-Square Test of Independence only assesses associations between categorical variables, and can not provide any inferences about causation.
If your categorical variables represent "pre-test" and "post-test" observations, then the chi-square test of independence is not appropriate . This is because the assumption of the independence of observations is violated. In this situation, McNemar's Test is appropriate.
Data Requirements
Your data must meet the following requirements:
- Two categorical variables.
- Two or more categories (groups) for each variable.
- There is no relationship between the subjects in each group.
- The categorical variables are not "paired" in any way (e.g. pre-test/post-test observations).
- Expected frequencies for each cell are at least 1.
- Expected frequencies should be at least 5 for the majority (80%) of the cells.
The null hypothesis ( H 0 ) and alternative hypothesis ( H 1 ) of the Chi-Square Test of Independence can be expressed in two different but equivalent ways:
H 0 : "[ Variable 1 ] is independent of [ Variable 2 ]" H 1 : "[ Variable 1 ] is not independent of [ Variable 2 ]"
H 0 : "[ Variable 1 ] is not associated with [ Variable 2 ]" H 1 : "[ Variable 1 ] is associated with [ Variable 2 ]"
Test Statistic
The test statistic for the Chi-Square Test of Independence is denoted Χ 2 , and is computed as:
$$ \chi^{2} = \sum_{i=1}^{R}{\sum_{j=1}^{C}{\frac{(o_{ij} - e_{ij})^{2}}{e_{ij}}}} $$
\(o_{ij}\) is the observed cell count in the i th row and j th column of the table
\(e_{ij}\) is the expected cell count in the i th row and j th column of the table, computed as
$$ e_{ij} = \frac{\mathrm{ \textrm{row } \mathit{i}} \textrm{ total} * \mathrm{\textrm{col } \mathit{j}} \textrm{ total}}{\textrm{grand total}} $$
The quantity ( o ij - e ij ) is sometimes referred to as the residual of cell ( i , j ), denoted \(r_{ij}\).
The calculated Χ 2 value is then compared to the critical value from the Χ 2 distribution table with degrees of freedom df = ( R - 1)( C - 1) and chosen confidence level. If the calculated Χ 2 value > critical Χ 2 value, then we reject the null hypothesis.
Data Set-Up
There are two different ways in which your data may be set up initially. The format of the data will determine how to proceed with running the Chi-Square Test of Independence. At minimum, your data should include two categorical variables (represented in columns) that will be used in the analysis. The categorical variables must include at least two groups. Your data may be formatted in either of the following ways:
If you have the raw data (each row is a subject):

- Cases represent subjects, and each subject appears once in the dataset. That is, each row represents an observation from a unique subject.
- The dataset contains at least two nominal categorical variables (string or numeric). The categorical variables used in the test must have two or more categories.
If you have frequencies (each row is a combination of factors):
An example of using the chi-square test for this type of data can be found in the Weighting Cases tutorial .

- Each row in the dataset represents a distinct combination of the categories.
- The value in the "frequency" column for a given row is the number of unique subjects with that combination of categories.
- You should have three variables: one representing each category, and a third representing the number of occurrences of that particular combination of factors.
- Before running the test, you must activate Weight Cases, and set the frequency variable as the weight.
Run a Chi-Square Test of Independence
In SPSS, the Chi-Square Test of Independence is an option within the Crosstabs procedure. Recall that the Crosstabs procedure creates a contingency table or two-way table , which summarizes the distribution of two categorical variables.
To create a crosstab and perform a chi-square test of independence, click Analyze > Descriptive Statistics > Crosstabs .

A Row(s): One or more variables to use in the rows of the crosstab(s). You must enter at least one Row variable.
B Column(s): One or more variables to use in the columns of the crosstab(s). You must enter at least one Column variable.
Also note that if you specify one row variable and two or more column variables, SPSS will print crosstabs for each pairing of the row variable with the column variables. The same is true if you have one column variable and two or more row variables, or if you have multiple row and column variables. A chi-square test will be produced for each table. Additionally, if you include a layer variable, chi-square tests will be run for each pair of row and column variables within each level of the layer variable.
C Layer: An optional "stratification" variable. If you have turned on the chi-square test results and have specified a layer variable, SPSS will subset the data with respect to the categories of the layer variable, then run chi-square tests between the row and column variables. (This is not equivalent to testing for a three-way association, or testing for an association between the row and column variable after controlling for the layer variable.)
D Statistics: Opens the Crosstabs: Statistics window, which contains fifteen different inferential statistics for comparing categorical variables.

To run the Chi-Square Test of Independence, make sure that the Chi-square box is checked.
E Cells: Opens the Crosstabs: Cell Display window, which controls which output is displayed in each cell of the crosstab. (Note: in a crosstab, the cells are the inner sections of the table. They show the number of observations for a given combination of the row and column categories.) There are three options in this window that are useful (but optional) when performing a Chi-Square Test of Independence:

1 Observed : The actual number of observations for a given cell. This option is enabled by default.
2 Expected : The expected number of observations for that cell (see the test statistic formula).
3 Unstandardized Residuals : The "residual" value, computed as observed minus expected.
F Format: Opens the Crosstabs: Table Format window, which specifies how the rows of the table are sorted.

Example: Chi-square Test for 3x2 Table
Problem statement.
In the sample dataset, respondents were asked their gender and whether or not they were a cigarette smoker. There were three answer choices: Nonsmoker, Past smoker, and Current smoker. Suppose we want to test for an association between smoking behavior (nonsmoker, current smoker, or past smoker) and gender (male or female) using a Chi-Square Test of Independence (we'll use α = 0.05).
Before the Test
Before we test for "association", it is helpful to understand what an "association" and a "lack of association" between two categorical variables looks like. One way to visualize this is using clustered bar charts. Let's look at the clustered bar chart produced by the Crosstabs procedure.
This is the chart that is produced if you use Smoking as the row variable and Gender as the column variable (running the syntax later in this example):
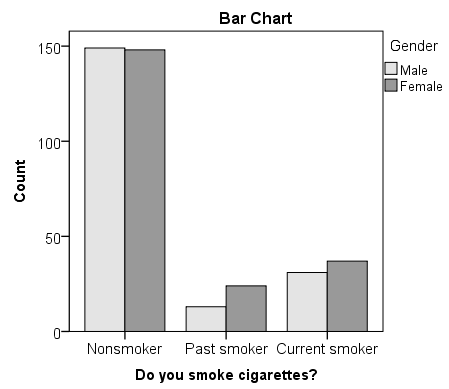
The "clusters" in a clustered bar chart are determined by the row variable (in this case, the smoking categories). The color of the bars is determined by the column variable (in this case, gender). The height of each bar represents the total number of observations in that particular combination of categories.
This type of chart emphasizes the differences within the categories of the row variable. Notice how within each smoking category, the heights of the bars (i.e., the number of males and females) are very similar. That is, there are an approximately equal number of male and female nonsmokers; approximately equal number of male and female past smokers; approximately equal number of male and female current smokers. If there were an association between gender and smoking, we would expect these counts to differ between groups in some way.
Running the Test
- Open the Crosstabs dialog ( Analyze > Descriptive Statistics > Crosstabs ).
- Select Smoking as the row variable, and Gender as the column variable.
- Click Statistics . Check Chi-square , then click Continue .
- (Optional) Check the box for Display clustered bar charts .
The first table is the Case Processing summary, which tells us the number of valid cases used for analysis. Only cases with nonmissing values for both smoking behavior and gender can be used in the test.

The next tables are the crosstabulation and chi-square test results.

The key result in the Chi-Square Tests table is the Pearson Chi-Square.
- The value of the test statistic is 3.171.
- The footnote for this statistic pertains to the expected cell count assumption (i.e., expected cell counts are all greater than 5): no cells had an expected count less than 5, so this assumption was met.
- Because the test statistic is based on a 3x2 crosstabulation table, the degrees of freedom (df) for the test statistic is $$ df = (R - 1)*(C - 1) = (3 - 1)*(2 - 1) = 2*1 = 2 $$.
- The corresponding p-value of the test statistic is p = 0.205.
Decision and Conclusions
Since the p-value is greater than our chosen significance level ( α = 0.05), we do not reject the null hypothesis. Rather, we conclude that there is not enough evidence to suggest an association between gender and smoking.
Based on the results, we can state the following:
- No association was found between gender and smoking behavior ( Χ 2 (2)> = 3.171, p = 0.205).
Example: Chi-square Test for 2x2 Table
Let's continue the row and column percentage example from the Crosstabs tutorial, which described the relationship between the variables RankUpperUnder (upperclassman/underclassman) and LivesOnCampus (lives on campus/lives off-campus). Recall that the column percentages of the crosstab appeared to indicate that upperclassmen were less likely than underclassmen to live on campus:
- The proportion of underclassmen who live off campus is 34.8%, or 79/227.
- The proportion of underclassmen who live on campus is 65.2%, or 148/227.
- The proportion of upperclassmen who live off campus is 94.4%, or 152/161.
- The proportion of upperclassmen who live on campus is 5.6%, or 9/161.
Suppose that we want to test the association between class rank and living on campus using a Chi-Square Test of Independence (using α = 0.05).
The clustered bar chart from the Crosstabs procedure can act as a complement to the column percentages above. Let's look at the chart produced by the Crosstabs procedure for this example:
The height of each bar represents the total number of observations in that particular combination of categories. The "clusters" are formed by the row variable (in this case, class rank). This type of chart emphasizes the differences within the underclassmen and upperclassmen groups. Here, the differences in number of students living on campus versus living off-campus is much starker within the class rank groups.
- Select RankUpperUnder as the row variable, and LiveOnCampus as the column variable.
- (Optional) Click Cells . Under Counts, check the boxes for Observed and Expected , and under Residuals, click Unstandardized . Then click Continue .
The first table is the Case Processing summary, which tells us the number of valid cases used for analysis. Only cases with nonmissing values for both class rank and living on campus can be used in the test.

The next table is the crosstabulation. If you elected to check off the boxes for Observed Count, Expected Count, and Unstandardized Residuals, you should see the following table:

With the Expected Count values shown, we can confirm that all cells have an expected value greater than 5.
| Off-Campus | On-Campus | Total | |
|---|---|---|---|
| Underclassman | Row 1, column 1 $$ o_{\mathrm{11}} = 79 $$ $$ e_{\mathrm{11}} = \frac{227*231}{388} = 135.147 $$ $$ r_{\mathrm{11}} = 79 - 135.147 = -56.147 $$ | Row 1, column 2 $$ o_{\mathrm{12}} = 148 $$ $$ e_{\mathrm{12}} = \frac{227*157}{388} = 91.853 $$ $$ r_{\mathrm{12}} = 148 - 91.853 = 56.147 $$ | row 1 total = 227 |
| Upperclassmen | Row 2, column 1 $$ o_{\mathrm{21}} = 152 $$ $$ e_{\mathrm{21}} = \frac{161*231}{388} = 95.853 $$ $$ r_{\mathrm{21}} = 152 - 95.853 = 56.147 $$ | Row 2, column 2 $$ o_{\mathrm{22}} = 9 $$ $$ e_{\mathrm{22}} = \frac{161*157}{388} = 65.147 $$ $$ r_{\mathrm{22}} = 9 - 65.147 = -56.147 $$ | row 2 total = 161 |
| Total | col 1 total = 231 | col 2 total = 157 | grand total = 388 |
These numbers can be plugged into the chi-square test statistic formula:
$$ \chi^{2} = \sum_{i=1}^{R}{\sum_{j=1}^{C}{\frac{(o_{ij} - e_{ij})^{2}}{e_{ij}}}} = \frac{(-56.147)^{2}}{135.147} + \frac{(56.147)^{2}}{91.853} + \frac{(56.147)^{2}}{95.853} + \frac{(-56.147)^{2}}{65.147} = 138.926 $$
We can confirm this computation with the results in the Chi-Square Tests table:

The row of interest here is Pearson Chi-Square and its footnote.
- The value of the test statistic is 138.926.
- Because the crosstabulation is a 2x2 table, the degrees of freedom (df) for the test statistic is $$ df = (R - 1)*(C - 1) = (2 - 1)*(2 - 1) = 1 $$.
- The corresponding p-value of the test statistic is so small that it is cut off from display. Instead of writing "p = 0.000", we instead write the mathematically correct statement p < 0.001.
Since the p-value is less than our chosen significance level α = 0.05, we can reject the null hypothesis, and conclude that there is an association between class rank and whether or not students live on-campus.
- There was a significant association between class rank and living on campus ( Χ 2 (1) = 138.9, p < .001).
- << Previous: Analyzing Data
- Next: Pearson Correlation >>
- Last Updated: Jul 10, 2024 11:08 AM
- URL: https://libguides.library.kent.edu/SPSS
Street Address
Mailing address, quick links.
- How Are We Doing?
- Student Jobs
Information
- Accessibility
- Emergency Information
- For Our Alumni
- For the Media
- Jobs & Employment
- Life at KSU
- Privacy Statement
- Technology Support
- Website Feedback
Chi-Square Independence Test – What and Why?
Chi-square independence test - what is it.
- Null Hypothesis
- Assumptions
Test Statistic
Effect size.
The chi-square independence test evaluates if two categorical variables are related in some population. Example: a scientist wants to know if education level and marital status are related for all people in some country. He collects data on a simple random sample of n = 300 people, part of which are shown below.

Chi-Square Test - Observed Frequencies
A good first step for these data is inspecting the contingency table of marital status by education. Such a table -shown below- displays the frequency distribution of marital status for each education category separately. So let's take a look at it.

The numbers in this table are known as the observed frequencies . They tell us an awful lot about our data. For instance,
- there's 4 marital status categories and 5 education levels;
- we succeeded in collecting data on our entire sample of n = 300 respondents (bottom right cell);
- we've 84 respondents with a Bachelor’s degree (bottom row, middle);
- we've 30 divorced respondents (last column, middle);
- we've 9 divorced respondents with a Bachelor’s degree.
Chi-Square Test - Column Percentages
Although our contingency table is a great starting point, it doesn't really show us if education level and marital status are related. This question is answered more easily from a slightly different table as shown below.

This table shows -for each education level separately- the percentages of respondents that fall into each marital status category. Before reading on, take a careful look at this table and tell me is marital status related to education level and -if so- how? If we inspect the first row, we see that 46% of respondents with middle school never married. If we move rightwards (towards higher education levels), we see this percentage decrease: only 18% of respondents with a PhD degree never married (top right cell).
Reversely, note that 64% of PhD respondents are married (second row). If we move towards the lower education levels (leftwards), we see this percentage decrease to 31% for respondents having just middle school. In short, more highly educated respondents marry more often than less educated respondents.
Chi-Square Test - Stacked Bar Chart
Our last table shows a relation between marital status and education. This becomes much clearer by visualizing this table as a stacked bar chart , shown below.

If we move from top to bottom (highest to lowest education) in this chart, we see the dark blue bar (never married) increase. Marital status is clearly associated with education level. The lower someone’s education, the smaller the chance he’s married. That is: education “says something” about marital status (and reversely) in our sample. So what about the population?
Chi-Square Test - Null Hypothesis
The null hypothesis for a chi-square independence test is that two categorical variables are independent in some population. Now, marital status and education are related -thus not independent- in our sample. However, we can't conclude that this holds for our entire population. The basic problem is that samples usually differ from populations.
If marital status and education are perfectly independent in our population, we may still see some relation in our sample by mere chance. However, a strong relation in a large sample is extremely unlikely and hence refutes our null hypothesis. In this case we'll conclude that the variables were not independent in our population after all.
So exactly how strong is this dependence -or association- in our sample? And what's the probability -or p-value - of finding it if the variables are (perfectly) independent in the entire population?
Chi-Square Test - Statistical Independence
Before we continue, let's first make sure we understand what “independence” really means in the first place. In short, independence means that one variable doesn't “say anything” about another variable. A different way of saying the exact same thing is that independence means that the relative frequencies of one variable are identical over all levels of some other variable. Uh... say again? Well, what if we had found the chart below?

What does education “say about” marital status? Absolutely nothing! Why? Because the frequency distributions of marital status are identical over education levels: no matter the education level, the probability of being married is 50% and the probability of never being married is 30%.
In this chart, education and marital status are perfectly independent . The hypothesis of independence tells us which frequencies we should have found in our sample: the expected frequencies.
Expected Frequencies
Expected frequencies are the frequencies we expect in a sample if the null hypothesis holds. If education and marital status are independent in our population, then we expect this in our sample too. This implies the contingency table -holding expected frequencies- shown below.

These expected frequencies are calculated as $$eij = \frac{oi\cdot oj}{N}$$ where
- \(eij\) is an expected frequency;
- \(oi\) is a marginal column frequency;
- \(oj\) is a marginal row frequency;
- \(N\) is the total sample size.
So for our first cell, that'll be $$eij = \frac{39 \cdot 90}{300} = 11.7$$ and so on. But let's not bother too much as our software will take care of all this.
Note that many expected frequencies are non integers . For instance, 11.7 respondents with middle school who never married. Although there's no such thing as “11.7 respondents” in the real world, such non integer frequencies are just fine mathematically. So at this point, we've 2 contingency tables:
- a contingency table with observed frequencies we found in our sample;
- a contingency table with expected frequencies we should have found in our sample if the variables are really independent.
The screenshot below shows both tables in this GoogleSheet (read-only). This sheet demonstrates all formulas that are used for this test.

Insofar as the observed and expected frequencies differ, our data deviate more from independence. So how much do they differ? First off, we subtract each expected frequency from each observed frequency, resulting in a residual . That is, $$rij = oij - eij$$ For our example, this results in (5 * 4 =) 20 residuals. Larger (absolute) residuals indicate a larger difference between our data and the null hypothesis. We basically add up all residuals , resulting in a single number: the χ 2 (pronounce “chi-square”) test statistic.
The chi-square test statistic is calculated as $$\chi^2 = \Sigma{\frac{(oij - eij)^2}{eij}}$$ so for our data $$\chi^2 = \frac{(18 - 11.7)^2}{11.7} + \frac{(36 - 27)^2}{27} + ... + \frac{(6 - 5.4)^2}{5.4} = 23.57$$ Again, our software will take care of all this. But if you'd like to see the calculations, take a look at this GoogleSheet .

So χ 2 = 23.57 in our sample. This number summarizes the difference between our data and our independence hypothesis. Is 23.57 a large value? What's the probability of finding this? Well, we can calculate it from its sampling distribution but this requires a couple of assumptions.
Chi-Square Test Assumptions
The assumptions for a chi-square independence test are
- independent observations . This usually -not always- holds if each case in SPSS holds a unique person or other statistical unit. Since this is the case for our data, we'll assume this has been met.
- For a 2 by 2 table , all expected frequencies > 5. However, for a 2 by 2 table, a z-test for 2 independent proportions is preferred over the chi-square test. For a larger table , all expected frequencies > 1 and no more than 20% of all cells may have expected frequencies < 5.
If these assumptions hold, our χ 2 test statistic follows a χ 2 distribution. It's this distribution that tells us the probability of finding χ 2 > 23.57.
Chi-Square Test - Degrees of Freedom
We'll get the p-value we're after from the chi-square distribution if we give it 2 numbers:
- the χ 2 value (23.57) and
- the degrees of freedom (df).
The degrees of freedom is basically a number that determines the exact shape of our distribution. The figure below illustrates this point.

Right. Now, degrees of freedom -or df- are calculated as $$df = (i - 1) \cdot (j - 1)$$ where
- \(i\) is the number of rows in our contingency table and
- \(j\) is the number of columns
so in our example $$df = (5 - 1) \cdot (4 - 1) = 12.$$ And with df = 12, the probability of finding χ 2 ≥ 23.57 ≈ 0.023. We simply look this up in SPSS or other appropriate software. This is our 1-tailed significance . It basically means, there's a 0.023 (or 2.3%) chance of finding this association in our sample if it is zero in our population.

Since this is a small chance, we no longer believe our null hypothesis of our variables being independent in our population. Conclusion: marital status and education are related in our population. Now, keep in mind that our p-value of 0.023 only tells us that the association between our variables is probably not zero. It doesn't say anything about the strength of this association: the effect size.
For the effect size of a chi-square independence test, consult the appropriate association measure. If at least one nominal variable is involved, that'll usually be Cramér’s V (a sort of Pearson correlation for categorical variables). In our example Cramér’s V = 0.162. Since Cramér’s V takes on values between 0 and 1, 0.162 indicates a very weak association. If both variables had been ordinal, Kendall’s tau or a Spearman correlation would have been suitable as well.
For reporting our results in APA style, we may write something like “An association between education and marital status was observed, χ 2 (12) = 23.57, p = 0.023.”
Chi-Square Independence Test - Software
You can run a chi-square independence test in Excel or Google Sheets but you probably want to use a more user friendly package such as
The figure below shows the output for our example generated by SPSS.

For a full tutorial (using a different example), see SPSS Chi-Square Independence Test .
Thanks for reading!
Tell us what you think!
This tutorial has 83 comments:.

By Ruben Geert van den Berg on October 30th, 2022
Thanks for the compliment!
Please note that you can print any web page to a .pdf file from your web browser (Edge/Firefox/Safari/Chrome).
Best regards,
SPSS tutorials

By Guellati on November 8th, 2022

By Chaquitta Carr on November 10th, 2022
This is awesome, but I have to read it a couple times because it is still quite overwhelming. You guys broke this down in a language I can at least begin to process, understand, and apply.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Biochem Med (Zagreb)
- v.23(2); 2013 Jun
The Chi-square test of independence
The Chi-square statistic is a non-parametric (distribution free) tool designed to analyze group differences when the dependent variable is measured at a nominal level. Like all non-parametric statistics, the Chi-square is robust with respect to the distribution of the data. Specifically, it does not require equality of variances among the study groups or homoscedasticity in the data. It permits evaluation of both dichotomous independent variables, and of multiple group studies. Unlike many other non-parametric and some parametric statistics, the calculations needed to compute the Chi-square provide considerable information about how each of the groups performed in the study. This richness of detail allows the researcher to understand the results and thus to derive more detailed information from this statistic than from many others.
The Chi-square is a significance statistic, and should be followed with a strength statistic. The Cramer’s V is the most common strength test used to test the data when a significant Chi-square result has been obtained. Advantages of the Chi-square include its robustness with respect to distribution of the data, its ease of computation, the detailed information that can be derived from the test, its use in studies for which parametric assumptions cannot be met, and its flexibility in handling data from both two group and multiple group studies. Limitations include its sample size requirements, difficulty of interpretation when there are large numbers of categories (20 or more) in the independent or dependent variables, and tendency of the Cramer’s V to produce relative low correlation measures, even for highly significant results.
Introduction
The Chi-square test of independence (also known as the Pearson Chi-square test, or simply the Chi-square) is one of the most useful statistics for testing hypotheses when the variables are nominal, as often happens in clinical research. Unlike most statistics, the Chi-square (χ 2 ) can provide information not only on the significance of any observed differences, but also provides detailed information on exactly which categories account for any differences found. Thus, the amount and detail of information this statistic can provide renders it one of the most useful tools in the researcher’s array of available analysis tools. As with any statistic, there are requirements for its appropriate use, which are called “assumptions” of the statistic. Additionally, the χ 2 is a significance test, and should always be coupled with an appropriate test of strength.
The Chi-square test is a non-parametric statistic, also called a distribution free test. Non-parametric tests should be used when any one of the following conditions pertains to the data:
- The level of measurement of all the variables is nominal or ordinal.
- The sample sizes of the study groups are unequal; for the χ 2 the groups may be of equal size or unequal size whereas some parametric tests require groups of equal or approximately equal size.
- The distribution of the data was seriously skewed or kurtotic (parametric tests assume approximately normal distribution of the dependent variable), and thus the researcher must use a distribution free statistic rather than a parametric statistic.
- The data violate the assumptions of equal variance or homoscedasticity.
- For any of a number of reasons ( 1 ), the continuous data were collapsed into a small number of categories, and thus the data are no longer interval or ratio.
Assumptions of the Chi-square
As with parametric tests, the non-parametric tests, including the χ 2 assume the data were obtained through random selection. However, it is not uncommon to find inferential statistics used when data are from convenience samples rather than random samples. (To have confidence in the results when the random sampling assumption is violated, several replication studies should be performed with essentially the same result obtained). Each non-parametric test has its own specific assumptions as well. The assumptions of the Chi-square include:
- The data in the cells should be frequencies, or counts of cases rather than percentages or some other transformation of the data.
- The levels (or categories) of the variables are mutually exclusive. That is, a particular subject fits into one and only one level of each of the variables.
- Each subject may contribute data to one and only one cell in the χ 2 . If, for example, the same subjects are tested over time such that the comparisons are of the same subjects at Time 1, Time 2, Time 3, etc., then χ 2 may not be used.
- The study groups must be independent. This means that a different test must be used if the two groups are related. For example, a different test must be used if the researcher’s data consists of paired samples, such as in studies in which a parent is paired with his or her child.
- There are 2 variables, and both are measured as categories, usually at the nominal level. However, data may be ordinal data. Interval or ratio data that have been collapsed into ordinal categories may also be used. While Chi-square has no rule about limiting the number of cells (by limiting the number of categories for each variable), a very large number of cells (over 20) can make it difficult to meet assumption #6 below, and to interpret the meaning of the results.
- The value of the cell expecteds should be 5 or more in at least 80% of the cells, and no cell should have an expected of less than one ( 3 ). This assumption is most likely to be met if the sample size equals at least the number of cells multiplied by 5. Essentially, this assumption specifies the number of cases (sample size) needed to use the χ 2 for any number of cells in that χ 2 . This requirement will be fully explained in the example of the calculation of the statistic in the case study example.
To illustrate the calculation and interpretation of the χ 2 statistic, the following case example will be used:
The owner of a laboratory wants to keep sick leave as low as possible by keeping employees healthy through disease prevention programs. Many employees have contracted pneumonia leading to productivity problems due to sick leave from the disease. There is a vaccine for pneumococcal pneumonia, and the owner believes that it is important to get as many employees vaccinated as possible. Due to a production problem at the company that produces the vaccine, there is only enough vaccine for half the employees. In effect, there are two groups; employees who received the vaccine and employees who did not receive the vaccine. The company sent a nurse to every employee who contracted pneumonia to provide home health care and to take a sputum sample for culture to determine the causative agent. They kept track of the number of employees who contracted pneumonia and which type of pneumonia each had. The data were organized as follows:
- Group 1: Not provided with the vaccine (unvaccinated control group, N = 92)
- Group 2: Provided with the vaccine (vaccinated experimental group, N = 92)
In this case, the independent variable is vaccination status (vaccinated versus unvaccinated). The dependent variable is health outcome with three levels:
- contracted pneumoccal pneumonia;
- contracted another type of pneumonia; and
- did not contract pneumonia.
The company wanted to know if providing the vaccine made a difference. To answer this question, they must choose a statistic that can test for differences when all the variables are nominal. The χ 2 statistic was used to test the question, “Was there a difference in incidence of pneumonia between the two groups?” At the end of the winter, Table 1 was constructed to illustrate the occurrence of pneumonia among the employees.
Results of the vaccination program.
| Sick with pneumococcal pneumonia | 23 | 5 |
| Sick with non-pneumococcal pneumonia | 8 | 10 |
| No pneumonia | 61 | 77 |
Calculating Chi-square
With the data in table form, the researcher can proceed with calculating the χ 2 statistic to find out if the vaccination program made any difference in the health outcomes of the employees. The formula for calculating a Chi-Square is:
The first step in calculating a χ 2 is to calculate the sum of each row, and the sum of each column. These sums are called the “marginals” and there are row marginal values and column marginal values. The marginal values for the case study data are presented in Table 2 .
Calculation of marginals.
| Sick with pneumococcal pneumonia | 23 | 5 | |
| Sick with non-pneumococcal pneumonia | 8 | 10 | |
| Stayed healthy | 61 | 77 | |
The second step is to calculate the expected values for each cell. In the Chi-square statistic, the “expected” values represent an estimate of how the cases would be distributed if there were NO vaccine effect. Expected values must reflect both the incidence of cases in each category and the unbiased distribution of cases if there is no vaccine effect. This means the statistic cannot just count the total N and divide by 6 for the expected number in each cell. That would not take account of the fact that more subjects stayed healthy regardless of whether they were vaccinated or not. Chi-Square expecteds are calculated as follows:
Specifically, for each cell, its row marginal is multiplied by its column marginal, and that product is divided by the sample size. For Cell 1, the math is as follows: (28 × 92)/184 = 13.92. Table 3 provides the results of this calculation for each cell. Once the expected values have been calculated, the cell χ 2 values are calculated with the following formula:
The cell χ 2 for the first cell in the case study data is calculated as follows: (23−13.93) 2 /13.93 = 5.92. The cell χ 2 value for each cellis the value in parentheses in each of the cells in Table 3 .
Cell expected values and (cell Chi-square values).
| Sick with pneumococcal pneumonia | 13.92 (5.92) | 12.57 (4.56) |
| Sick with non-pneumococcal pneumonia | 8.95 (0.10) | 9.05 (0.10) |
| Stayed healthy | 69.12 (0.95) | 69.88 (0.73) |
Once the cell χ 2 values have been calculated, they are summed to obtain the χ 2 statistic for the table. In this case, the χ 2 is 12.35 (rounded). The Chi-square table requires the table’s degrees of freedom (df) in order to determine the significance level of the statistic. The degrees of freedom for a χ 2 table are calculated with the formula:
For example, a 2 × 2 table has 1 df. (2−1) × (2−1) = 1. A 3 × 3 table has (3−1) × (3−1) = 4 df. A 4 × 5 table has (4−1) × (5−1) = 3 × 4 = 12 df. Assuming a χ 2 value of 12.35 with each of these different df levels (1, 4, and 12), the significance levels from a table of χ 2 values, the significance levels are: df = 1, P < 0.001, df = 4, P < 0.025, and df = 12, P > 0.10. Note, as degrees of freedom increase, the P-level becomes less significant, until the χ 2 value of 12.35 is no longer statistically significant at the 0.05 level, because P was greater than 0.10.
For the sample table with 3 rows and 2 columns, df = (3−1) × (2−1) = 2 × 1 = 2. A Chi-square table of significances is available in many elementary statistics texts and on many Internet sites. Using a χ 2 table, the significance of a Chi-square value of 12.35 with 2 df equals P < 0.005. This value may be rounded to P < 0.01 for convenience. The exact significance when the Chi-square is calculated through a statistical program is found to be P = 0.0011.
As the P-value of the table is less than P < 0.05, the researcher rejects the null hypothesis and accepts the alternate hypothesis: “There is a difference in occurrence of pneumococcal pneumonia between the vaccinated and unvaccinated groups.” However, this result does not specify what that difference might be. To fully interpret the result, it is useful to look at the cell χ 2 values.
Interpreting cell χ 2 values
It can be seen in Table 3 that the largest cell χ 2 value of 5.92 occurs in Cell 1. This is a result of the observed value being 23 while only 13.92 were expected. Therefore, this cell has a much larger number of observed cases than would be expected by chance. Cell 1 reflects the number of unvaccinated employees who contracted pneumococcal pneumonia. This means that the number of unvaccinated people who contracted pneumococcal pneumonia was significantly greater than expected. The second largest cell χ 2 value of 4.56 is located in Cell 2. However, in this cell we discover that the number of observed cases was much lower than expected (Observed = 5, Expected = 12.57). This means that a significantly lower number of vaccinated subjects contracted pneumococcal pneumonia than would be expected if the vaccine had no effect. No other cell has a cell χ 2 value greater than 0.99.
A cell χ 2 value less than 1.0 should be interpreted as the number of observed cases being approximately equal to the number of expected cases, meaning there is no vaccination effect on any of the other cells. In the case study example, all other cells produced cell χ 2 values below 1.0. Therefore the company can conclude that there was no difference between the two groups for incidence of non-pneumococcal pneumonia. It can be seen that for both groups, the majority of employees stayed healthy. The meaningful result was that there were significantly fewer cases of pneumococcal pneumonia among the vaccinated employees and significantly more cases among the unvaccinated employees. As a result, the company should conclude that the vaccination program did reduce the incidence of pneumoccal pneumonia.
Very few statistical programs provide tables of cell expecteds and cell χ 2 values as part of the default output. Some programs will produce those tables as an option, and that option should be used to examine the cell χ 2 values. If the program provides an option to print out only the cell χ 2 value (but not cell expecteds), the direction of the χ 2 value provides information. A positive cell χ 2 value means that the observed value is higher than the expected value, and a negative cell χ 2 value (e.g. −12.45) means the observed cases are less than the expected number of cases. When the program does not provide either option, all the researcher can conclude is this: The overall table provides evidence that the two groups are independent (significantly different because P < 0.05), or are not independent (P > 0.05). Most researchers inspect the table to estimate which cells are overrepresented with a large number of cases versus those which have a small number of cases. However, without access to cell expecteds or cell χ 2 values, the interpretation of the direction of the group differences is less precise. Given the ease of calculating the cell expecteds and χ 2 values, researchers may want to hand calculate those values to enhance interpretation.
Chi-square and closely related tests
One might ask if, in this case, the Chi-square was the best or only test the researcher could have used. Nominal variables require the use of non-parametric tests, and there are three commonly used significance tests that can be used for this type of nominal data. The first and most commonly used is the Chi-square. The second is the Fisher’s exact test, which is a bit more precise than the Chi-square, but it is used only for 2 × 2 Tables ( 4 ). For example, if the only options in the case study were pneumonia versus no pneumonia, the table would have 2 rows and 2 columns and the correct test would be the Fisher’s exact. The case study example requires a 2 × 3 table and thus the data are not suitable for the Fisher’s exact test.
The third test is the maximum likelihood ratio Chi-square test which is most often used when the data set is too small to meet the sample size assumption of the Chi-square test. As exhibited by the table of expected values for the case study, the cell expected requirements of the Chi-square were met by the data in the example. Specifically, there are 6 cells in the table. To meet the requirement that 80% of the cells have expected values of 5 or more, this table must have 6 × 0.8 = 4.8 rounded to 5. This table meets the requirement that at least 5 of the 6 cells must have cell expected of 5 or more, and so there is no need to use the maximum likelihood ratio chi-square. Suppose the sample size were much smaller. Suppose the sample size was smaller and the table had the data in Table 4 .
Example of a table that violates cell expected values.
| Pneumococcal Pneumonia | 4 (2.22)/1.42 | 0 (1.75)/1.78 |
| Non-pneumococcal Pneumonia | 2 (1.67)/0.07 | 1 (1.33)/0.08 |
| Stayed healthy | 14 (16.11)/0.28 | 15 (12.89)/0.35 |
Sample raw data presented first, sample expected values in parentheses, and cell follow the slash.
Although the total sample size of 39 exceeds the value of 5 cases × 6 cells = 30, the very low distribution of cases in 4 of the cells is of concern. When the cell expecteds are calculated, it can be seen that 4 of the 6 cells have expecteds below 5, and thus this table violates the χ 2 test assumption. This table should be tested with a maximum likelihood ratio Chi-square test.
When researchers use the Chi-square test in violation of one or more assumptions, the result may or may not be reliable. In this author’s experience of having output from both the appropriate and inappropriate tests on the same data, one of three outcomes are possible:
First, the appropriate and the inappropriate test may give the same results.
Second, the appropriate test may produce a significant result while the inappropriate test provides a result that is not statistically significant, which is a Type II error.
Third, the appropriate test may provide a non-significant result while the inappropriate test may provide a significant result, which is a Type I error.
Strength test for the Chi-square
The researcher’s work is not quite done yet. Finding a significant difference merely means that the differences between the vaccinated and unvaccinated groups have less than 1.1 in a thousand chances of being in error (P = 0.0011). That is, there are 1.1 in one thousand chances that there really is no difference between the two groups for contracting pneumococcal pneumonia, and that the researcher made a Type I error. That is a sufficiently remote probability of error that in this case, the company can be confident that the vaccination made a difference. While useful, this is not complete information. It is necessary to know the strength of the association as well as the significance.
Statistical significance does not necessarily imply clinical importance. Clinical significance is usually a function of how much improvement is produced by the treatment. For example, if there was a significant difference, but the vaccine only reduced pneumonias by two cases, it might not be worth the company’s money to vaccinate 184 people (at a cost of $20 per person) to eliminate only two cases. In this case study, the vaccinated group experienced only 5 cases out of 92 employees (a rate of 5%) while the unvaccinated group experienced 23 cases out of 92 employees (a rate of 25%). While it is always a matter of judgment as to whether the results are worth the investment, many employers would view 25% of their workforce becoming ill with a preventable infectious illness as an undesirable outcome. There is, however, a more standardized strength test for the Chi-Square.
Statistical strength tests are correlation measures. For the Chi-square, the most commonly used strength test is the Cramer’s V test. It is easily calculated with the following formula:
Where n is the number of rows or number of columns, whichever is less. For the example, the V is 0.259 or rounded, 0.26 as calculated below.
The Cramer’s V is a form of a correlation and is interpreted exactly the same. For any correlation, a value of 0.26 is a weak correlation. It should be noted that a relatively weak correlation is all that can be expected when a phenomena is only partially dependent on the independent variable.
In the case study, five vaccinated people did contract pneumococcal pneumonia, but vaccinated or not, the majority of employees remained healthy. Clearly, most employees will not get pneumonia. This fact alone makes it difficult to obtain a moderate or high correlation coefficient. The amount of change the treatment (vaccine) can produce is limited by the relatively low rate of disease in the population of employees. While the correlation value is low, it is statistically significant, and the clinical importance of reducing a rate of 25% incidence to 5% incidence of the disease would appear to be clinically worthwhile. These are the factors the researcher should take into account when interpreting this statistical result.
Summary and conclusions
The Chi-square is a valuable analysis tool that provides considerable information about the nature of research data. It is a powerful statistic that enables researchers to test hypotheses about variables measured at the nominal level. As with all inferential statistics, the results are most reliable when the data are collected from randomly selected subjects, and when sample sizes are sufficiently large that they produce appropriate statistical power. The Chi-square is also an excellent tool to use when violations of assumptions of equal variances and homoscedascity are violated and parametric statistics such as the t-test and ANOVA cannot provide reliable results. As the Chi-Square and its strength test, the Cramer’s V are both simple to compute, it is an especially convenient tool for researchers in the field where statistical programs may not be easily accessed. However, most statistical programs provide not only the Chi-square and Cramer’s V, but also a variety of other non-parametric tools for both significance and strength testing.
Potential conflict of interest
None declared.

Stats and R
Chi-square test of independence by hand.
- Hypothesis test
- Inferential statistics
Introduction
How the test works, observed frequencies, expected frequencies, test statistic, critical value, conclusion and interpretation.

Chi-square tests of independence test whether two qualitative variables are independent, that is, whether there exists a relationship between two categorical variables. In other words, this test is used to determine whether the values of one of the 2 qualitative variables depend on the values of the other qualitative variable.
If the test shows no association between the two variables (i.e., the variables are independent), it means that knowing the value of one variable gives no information about the value of the other variable. On the contrary, if the test shows a relationship between the variables (i.e., the variables are dependent), it means that knowing the value of one variable provides information about the value of the other variable.
This article focuses on how to perform a Chi-square test of independence by hand and how to interpret the results with a concrete example. To learn how to do this test in R, read the article “ Chi-square test of independence in R ”.
The Chi-square test of independence is a hypothesis test so it has a null ( \(H_0\) ) and an alternative hypothesis ( \(H_1\) ):
- \(H_0\) : the variables are independent, there is no relationship between the two categorical variables. Knowing the value of one variable does not help to predict the value of the other variable
- \(H_1\) : the variables are dependent, there is a relationship between the two categorical variables. Knowing the value of one variable helps to predict the value of the other variable
The Chi-square test of independence works by comparing the observed frequencies (so the frequencies observed in your sample) to the expected frequencies if there was no relationship between the two categorical variables (so the expected frequencies if the null hypothesis was true).
If the difference between the observed frequencies and the expected frequencies is small , we cannot reject the null hypothesis of independence and thus we cannot reject the fact that the two variables are not related . On the other hand, if the difference between the observed frequencies and the expected frequencies is large , we can reject the null hypothesis of independence and thus we can conclude that the two variables are related .
The threshold between a small and large difference is a value that comes from the Chi-square distribution (hence the name of the test). This value, referred as the critical value, depends on the significance level \(\alpha\) (usually set equal to 5%) and on the degrees of freedom. This critical value can be found in the statistical table of the Chi-square distribution. More on this critical value and the degrees of freedom later in the article.
For our example, we want to determine whether there is a statistically significant association between smoking and being a professional athlete. Smoking can only be “yes” or “no” and being a professional athlete can only be “yes” or “no”. The two variables of interest are qualitative variables so we need to use a Chi-square test of independence, and the data have been collected on 28 persons.
Note that we chose binary variables (binary variables = qualitative variables with two levels) for the sake of easiness, but the Chi-square test of independence can also be performed on qualitative variables with more than two levels. For instance, if the variable smoking had three levels: (i) non-smokers, (ii) moderate smokers and (iii) heavy smokers, the steps and the interpretation of the results of the test are similar than with two levels.
Our data are summarized in the contingency table below reporting the number of people in each subgroup, totals by row, by column and the grand total:
| Non-smoker | Smoker | Total | |
|---|---|---|---|
| 14 | 4 | 18 | |
| 0 | 10 | 10 | |
| 14 | 14 | 28 |
Remember that for the Chi-square test of independence we need to determine whether the observed counts are significantly different from the counts that we would expect if there was no association between the two variables. We have the observed counts (see the table above), so we now need to compute the expected counts in the case the variables were independent. These expected frequencies are computed for each subgroup one by one with the following formula:
\[\text{exp. frequencies} = \frac{\text{total # of obs. for the row} \cdot \text{total # of obs. for the column}}{\text{total number of observations}}\]
where obs. correspond to observations. Given our table of observed frequencies above, below is the table of the expected frequencies computed for each subgroup:
| Non-smoker | Smoker | Total | |
|---|---|---|---|
| (18 * 14) / 28 = 9 | (18 * 14) / 28 = 9 | 18 | |
| (10 * 14) / 28 = 5 | (10 * 14) / 28 = 5 | 10 | |
| 14 | 14 | 28 |
Note that the Chi-square test of independence should only be done when the expected frequencies in all groups are equal to or greater than 5. This assumption is met for our example as the minimum number of expected frequencies is 5. If the condition is not met, the Fisher’s exact test is preferred.
Talking about assumptions, the Chi-square test of independence requires that the observations are independent. This is usually not tested formally, but rather verified based on the design of the experiment and on the good control of experimental conditions. If you are not sure, ask yourself if one observation is related to another (if one observation has an impact on another). If not, it is most likely that you have independent observations.
If you have dependent observations (paired samples), the McNemar’s or Cochran’s Q tests should be used instead. The McNemar’s test is used when we want to know if there is a significant change in two paired samples (typically in a study with a measure before and after on the same subject) when the variables have only two categories. The Cochran’s Q tests is an extension of the McNemar’s test when we have more than two related measures.
We have the observed and expected frequencies. We now need to compare these frequencies to determine if they differ significantly. The difference between the observed and expected frequencies, referred as the test statistic (or t-stat) and denoted \(\chi^2\) , is computed as follows:
\[\chi^2 = \sum_{i, j} \frac{\big(O_{ij} - E_{ij}\big)^2}{E_{ij}}\]
where \(O\) represents the observed frequencies and \(E\) the expected frequencies. We use the square of the differences between the observed and expected frequencies to make sure that negative differences are not compensated by positive differences. The formula looks more complex than what it really is, so let’s illustrate it with our example. We first compute the difference in each subgroup one by one according to the formula:
- in the subgroup of athlete and non-smoker: \(\frac{(14 - 9)^2}{9} = 2.78\)
- in the subgroup of non-athlete and non-smoker: \(\frac{(0 - 5)^2}{5} = 5\)
- in the subgroup of athlete and smoker: \(\frac{(4 - 9)^2}{9} = 2.78\)
- in the subgroup of non-athlete and smoker: \(\frac{(10 - 5)^2}{5} = 5\)
and then we sum them all to obtain the test statistic:
\[\chi^2 = 2.78 + 5 + 2.78 + 5 = 15.56\]
The test statistic alone is not enough to conclude for independence or dependence between the two variables. As previously mentioned, this test statistic (which in some sense is the difference between the observed and expected frequencies) must be compared to a critical value to determine whether the difference is large or small. One cannot tell that a test statistic is large or small without putting it in perspective with the critical value.
If the test statistic is above the critical value, it means that the probability of observing such a difference between the observed and expected frequencies is unlikely. On the other hand, if the test statistic is below the critical value, it means that the probability of observing such a difference is likely. If it is likely to observe this difference, we cannot reject the hypothesis that the two variables are independent, otherwise we can conclude that there exists a relationship between the variables.
The critical value can be found in the statistical table of the Chi-square distribution and depends on the significance level, denoted \(\alpha\) , and the degrees of freedom, denoted \(df\) . The significance level is usually set equal to 5%. The degrees of freedom for a Chi-square test of independence is found as follow:
\[df = (\text{number of rows} - 1) \cdot (\text{number of columns} - 1)\]
In our example, the degrees of freedom is thus \(df = (2 - 1) \cdot (2 - 1) = 1\) since there are two rows and two columns in the contingency table (totals do not count as a row or column).
We now have all the necessary information to find the critical value in the Chi-square table ( \(\alpha = 0.05\) and \(df = 1\) ). To find the critical value we need to look at the row \(df = 1\) and the column \(\chi^2_{0.050}\) (since \(\alpha = 0.05\) ) in the picture below. The critical value is \(3.84146\) . 1

Chi-square table - Critical value for alpha = 5% and df = 1
Now that we have the test statistic and the critical value, we can compare them to check whether the null hypothesis of independence of the variables is rejected or not. In our example,
\[\text{test statistic} = 15.56 > \text{critical value} = 3.84146\]
Like for many statistical tests , when the test statistic is larger than the critical value, we can reject the null hypothesis at the specified significance level.
In our case, we can therefore reject the null hypothesis of independence between the two categorical variables at the 5% significance level.
\(\Rightarrow\) This means that there is a significant relationship between the smoking habit and being an athlete or not. Knowing the value of one variable helps to predict the value of the other variable.
Thanks for reading.
I hope the article helped you to perform the Chi-square test of independence by hand and interpret its results. If you would like to learn how to do this test in R, read the article “ Chi-square test of independence in R ”.
As always, if you have a question or a suggestion related to the topic covered in this article, please add it as a comment so other readers can benefit from the discussion.
For readers that prefer to check the \(p\) -value in order to reject or not the null hypothesis, I also created a Shiny app to help you compute the \(p\) -value given a test statistic. ↩︎
Related articles
- Wilcoxon test in R: how to compare 2 groups under the non-normality assumption?
- Correlation coefficient and correlation test in R
- One-proportion and chi-square goodness of fit test
- How to do a t-test or ANOVA for more than one variable at once in R?
Liked this post?
- Get updates every time a new article is published (no spam and unsubscribe anytime):
Yes, receive new posts by email
- Support the blog
FAQ Contribute Sitemap
User Preferences
Content preview.
Arcu felis bibendum ut tristique et egestas quis:
- Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris
- Duis aute irure dolor in reprehenderit in voluptate
- Excepteur sint occaecat cupidatat non proident
Keyboard Shortcuts
3.3 - test for independence.
Two-way contingency tables show the behavior (distribution) of two discrete variables. Given an \(I\times J\) table, it is therefore natural to ask if and how are \(Y\) and \(Z\) related?
Suppose for the moment that there is no relationship between \(Y\) and \(Z\), i.e., they are independent.
By statistical independence, we mean that the joint probabilities are equal to the product of the marginal probabilities:
\(\pi_{ij}=P(Y=i,Z=j)=P(Y=i)P(Z=j)\) \(\pi_{ij}=\pi_{i+}\pi_{+j}\)
for all pairs of \(i, j\). If the data are independent and we know the marginal totals, then we can determine the exact probabilities for each of the cells. Independence may be expressed in other forms also, but for now, we will use this definition. Intuitively, independence means that the behavior of one variable, say \(Y\), will not be impacted by the behavior of \(Z\). In the Vitamin C example, independence means that whether or not a skier takes vitamin C has nothing to do with whether or not he/she has a cold.
Chi-Squared Test of Independence Section
The hypothesis of independence can be tested using the general method of goodness-of-fit test described earlier.
\(H_0\): the independence model is true i.e. \(\pi_{ij} = \pi_{i+}\pi_{+j}\) for all pairs of \((i, j)\)
versus the alternative
\(H_A\): the saturated model is true, i.e. \(\pi_{ij} \ne \pi_{i+}\pi_{+j}\) for at least one pair of \((i, j)\)
calculate expected counts under the independence model
compare the expected counts \(E_{ij}\) to the observed counts \(O_{ij}\)
calculate \(X^2\) and/or \(G^2\) for testing the hypothesis of independence, and compare the values to the appropriate chi-squared distribution with correct df \((I-1)(J-1)\)
Before we see how to do this in R and SAS, let's see more about the saturated model and independence model in \(I\times J\) tables.
Saturated Model Section
Suppose that the cell counts \(n_{11}, \dots , n_{IJ}\) have a multinomial distribution with index \(n_{++} = n\) and parameters
\(\pi=(\pi_{11},\ldots,\pi_{IJ})\)
(these results also work for Poisson or product-multinomial sampling). If the saturated model is true, the number of unknown parameters we need to estimate is maximal (just like in one-way tables) and it is equal to the number of cells in the table. But because the elements of \(\pi\) must sum to one, the saturated model actually has \(IJ − 1\) free parameters. For example if we had a \(3\times5\) table, we would have \(15 - 1 = 14\) unique parameters \(\pi_{ij}\)s that need to be estimated.
Independence Model Section
If the two variables Y and Z are independent, then \(\pi\) has a special form. Let
\(\pi_{i+} = P(Y = i), i = 1, 2, \ldots , I \) \(\pi_{+j} = P(Z = j), j = 1, 2, \ldots, J\)
Note that \(\sum\limits_{i=1}^I \pi_{i+}=\sum\limits_{j=1}^J \pi_{+j}=1\), so the vectors \(\pi_{i+} = (\pi_{1+}, \pi_{2+}, . . . , \pi_{I+})\) and \(\pi_{+j} = (\pi_{+1}, \pi_{+2}, \ldots , \pi_{+J} )\) representing the marginal distributions (row probabilities and column probabilities) containing \( I − 1\) and \(J − 1\) unknown parameters, respectively.
If \(Y\) and \(Z\) are independent, then any element of \(\pi\) can be expressed as
\(\pi_{ij}=P(Y=i)P(Z=j)=\pi_{i+}\pi_{+j}\)
Thus, under independence, \(\pi\) is a function of \((I − 1) + (J − 1)\) unknown parameters.
The parameters under the independence model can be estimated as follows. Note that the vector of row sums (observed marginal counts for the row variable \(Y\)), \((n_{1+},n_{2+},\ldots,n_{I+})\) has a multinomial distribution with index \(n\) and parameter \(\pi_{i+}\). The vector of column sums (observed marginal counts for the column variable \(Z\)), \((n_{+1},n_{+2},\ldots,n_{+J})\) has a multinomial distribution with index \(n = n_{++}\) and parameter \(\pi_{+j}\). The elements of \(\pi_{i+}\) and \(\pi_{+j}\) can thus be estimated by the sample proportions in each margin:
\(\hat{\pi}_{i+}=n_{i+}/n_{++},\qquad i=1,2,\ldots,I\)
\(\hat{\pi}_{+j}=n_{+j}/n_{++},\qquad j=1,2,\ldots,J\)
respectively.
Then, the estimated expected cell frequencies under the independence model are
\(E_{ij}=n\hat{\pi}_{ij}=n\hat{\pi}_{i+}\hat{\pi}_{+j}=\dfrac{n_{i+}n_{+j}}{n_{++}}\)
which can be remembered as
expected frequency = row total × column total / grand total .
Pearson and Deviance Statistics Section
Since for jointly observed \((Y,Z)\) the two-way table counts can be viewed as a single multinomial distribution with \(IJ\) categories, we can apply the chi-square approximation in the same way we applied it for the goodness-of-fit tests; we just need to adapt to the double index and sum over all cells in both dimensions. That is, the quantity
\(\sum\limits_{i=1}^I \sum\limits_{j=1}^J \dfrac{(n_{ij}-n\pi_{ij})^2}{n\pi_{ij}}\)
is approximately chi-squared with degrees of freedom equal to \(\nu=IJ-1\). And if we have a null hypothesis in mind, say for independence, we can use the estimated probabilities under that hypothesis to construct both the Pearson and likelihood ratio test statistics. The degrees of freedom would be reduced by the number of estimated parameters as well. In what follows below, we assume the null hypothesis (reduced model) to be tested is that of independence, but other hypotheses could also be considered.
\(X^2=\sum\limits_{i=1}^I \sum\limits_{j=1}^J \dfrac{(n_{ij}-n\hat{\pi}_{ij})^2}{n\hat{\pi}_{ij}}\)
where \(\hat{\pi}_{ij}=(n_{i+}/n)(n_{+j}/n)\) under the independence model. Note that this expression still corresponds to
\(X^2=\sum\limits_{i=1}^I \sum\limits_{j=1}^J \dfrac{(O_{ij}-E_{ij})^2}{E_{ij}}\)
where \(O_{ij} = n_{ij}\) is the observed count and \(E_{ij} = E(n_{ij})\) is the expected count under the null hypothesis.
The deviance statistic can similarly be calculated for two-way tables:
\(G^2=2\sum\limits_{i=1}^I \sum\limits_{j=1}^J n_{ij}\log\left(\dfrac{n_{ij}}{n\hat{\pi}_{ij}}\right) = 2\sum\limits_{i=1}^I \sum\limits_{j=1}^J O_{ij}\log\left(\dfrac{O_{ij}}{E_{ij}}\right)\)
\(G^2\) is also called the likelihood-ratio test statistic or likelihood-ratio chi-squared test statistic . Recall from the discussion on one-way tables that we are comparing the likelihoods of the assumed model under \(H_0\) and some alternative model, \(H_A\), typically the saturated model (i.e., the observed data) by default. More generally, the likelihood-ratio test statistic can be described as follows:
Let max \(L(H_0)\) be the maximum of the likelihood when parameters satisfy \(H_0; H_0\) usually has more restrictions on the parameters.
Let max \(L(H_A)\) be the maximum of the likelihood when parameters satisfy \(H_A; H_A\) usually has no or fewer restrictions on the parameters.
Then the likelihood-ratio statistic would be:
\(\Lambda=\dfrac{\max L(H_0)}{\max L(H_A)}\)
and the deviance \(G^2 = −2\log(\Lambda)\).
The smaller the likelihood under \(H_0\) (less chance of the restricted model to hold given the data), the more evidence you would have against \(H_0\), that is, the smaller \(\Lambda\) and greater \(G^2\).
What are the degrees of freedom for this test? Section
The general rule for df.
DF are equal to the number of parameters specified (estimated) under the alternative model (hypothesis) minus the number of parameters estimated under the null model (hypothesis).
Computing Degrees of Freedom
Recall, under the saturated model, \(\pi\) contains \(IJ-1\) free (unique) parameters. And under the independence model, \(\pi\) is a function of \((I-1)+(J-1)\) parameters since each joint probability \(\pi_{ij}\) can be written as the product of the marginals \(\pi_{i+}\pi_{+j}\), each of which has the sum-to-one constraint. The degrees of freedom are therefore
\(\nu=(IJ-1)-(I-1)-(J-1)=(I-1)(J-1)\)
For \(2\times2\) tables, this reduces to \((2 - 1)(2 - 1) = 1\).
A large value of \(X^2\) or \(G^2\) indicates that the independence model is not plausible and that \(Y\) and \(Z\) are related. Under the null hypothesis, \(X^2\) and \(G^2\) are approximately distributed as a chi-squared distribution with \(\nu= (I − 1)(J − 1)\) degrees of freedom, provided that (a) the \(n\) sample units are iid (i.e., there is no clustering), and (b) the expected counts \(E_{ij}\) are sufficiently large (recall the discussion in one-way tables) At a minimum we'd like to have all \(E_{ij}\ge1\) with at least 80% of them 5 or more.
For \(2\times2\) tables, the 95th percentile of \(\chi^2_1\) is 3.84, so an observed value of \(X^2\) or \(G^2\) greater than 3.84 means that we can reject the null hypothesis of independence at the .05 level.
Example: Vitamin C Section

How can we do the test of independence computationally? Let's illustrate this first using the Vitamin C example, which is the \(2\times2\) case. We're interested in whether the treatment type and contracting cold are associated.
Here is an example in SAS using the program code VitaminC.sas ; see the R tab for the R code.
Let's look at different parts of the output. SAS output for this program.
Table of treatment by response section produces the table with observed, expected values, sample proportions, and conditional probabilities.
The FREQ Procedure
Heading II:Statistics for Table of treatment by response section produces various test statistics, such as \(X^2\) and \(G^2\). Statistics for Table of treatment by response
\(X^2 = 4.8114\) and \(G^2 = 4.8717\), with df=1, indicate strong evidence for rejecting the independence model. Continuity Adj. Chi-Square = 4.1407 with \(p\)-value = 0.0419, is the Pearson's \(X^2\) adjusted slightly for small cell counts. The adjustment is to subtract 0.5 from a difference between the observed and the expected counts in the formula for the \(X^2\) statistic, i.e., \({O_{ij}-n_{ij}}-0.5\). The \(X^2\) statistic with this adjustment gives conservative inference; that is, it gives a bigger \(p\)-value than the usual Pearson \(X^2\) statistic without the correction. But since SAS can produce exact tests we won't need to consider this statistic. Here is the test of independence for Vitamin C example, also found in the section with R files VitaminC.R and its output, VitaminC.out . Notice that by default chisq.test() function in R will give us the \(X^2\) statistic with a slight adjustment for small cell counts. The adjustment is to subtract 0.5 from a difference between the observed and the expected counts in the formula for the \(X^2\) statistic, i.e., \({O_{ij}-n_{ij}}-0.5\). The \(X^2\) statistic with this adjustment gives conservative inference; that is, it gives a bigger \(p\)-value than the usual Pearson \(X^2\) statistic without the correction. To get the usual \(X^2\), we need to invoke an option correct = FALSE. To compute the deviance statistic for two-way tables, we can use the function LRstats.R or one of the R packages, such as VCD . Example: Coronary Heart Disease SectionNext, we return to the Coronary Heart Disease example from the introduction and ask "Is having coronary heart disease independent of the cholesterol level in ones body? Is there any evidence of a relationship/association between cholesterol and heart disease?" Test of Independence in SAS - Coronary Heart Disease ExampleLet's see the same calculation using the SAS code below: HeartDisease.sas See the complete SAS output: HeartDisease SAS Output . Here is a portion of the output from SAS with the Pearson chi-square statistic and Deviance (likelihood-ratio chi-square) statistic: Statistics for Table of CHD by serum
Test of Independence in R - Coronary Heart Disease ExampleTwo different computations are done in HeartDisease.R file using the function chisq.test() . Here is the first: You will notice in the file that unlike for \(2\times 2\) tables where we had to worry about R the continuity correction, there is no such thing for \( I \times J\) tables. It doesn't matter, in this example, if you call the function chisq.test(heart, correct=TRUE) or chisq.test(heart, correct=FALSE) because the results are the same. \(X^2= 35.0285\), df = 3, \(p\)-value = 1.202e-07 and the likelihood-ratio test statistic is \(G^2= 31.9212\), df = 3, \(p\)-value = 5.43736e-07 Notice that the chisq.test() function does not compute \(G^2\), but we included extra code to do that. For the complete output file, see the HeartDisease.out file. Here is also a more general function LRstats.R for computing the \(G^2\) for two-way tables. The results are discussed further below. We reject the null hypothesis of independence because of the big values of the chi-square statistics. Notice the degrees of freedom are equal to \(3 = (4-1)(2-1)\), and thus the \(p\)-value is very low. Therefore, through the \(X^2\) test for independence, we have demonstrated beyond a reasonable doubt that a relationship exists between cholesterol and CHD. A good statistical analysis, however, should not end with the rejection of a null hypothesis. Once we have demonstrated that a relationship exists, we may be interested in which cells were particularly revealing. To do this we consider computing and evaluating the residuals. Pardon Our InterruptionAs you were browsing something about your browser made us think you were a bot. There are a few reasons this might happen:
To regain access, please make sure that cookies and JavaScript are enabled before reloading the page. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
COMMENTS
A Chi-Square test of independence uses the following null and alternative hypotheses: H0: (null hypothesis) The two variables are independent. H1: (alternative hypothesis) The two variables are not independent. (i.e. they are associated) We use the following formula to calculate the Chi-Square test statistic X2: X2 = Σ (O-E)2 / E.
A chi-square (Χ 2) test of independence is a nonparametric hypothesis test. You can use it to test whether two categorical variables are related to each other. Example: Chi-square test of independence. Imagine a city wants to encourage more of its residents to recycle their household waste.
The Chi-square test of independence assesses the relationship between categorical variables. ... was "do gold shirts die more frequently than other colours" the answer would be that the data does not rule out the null hypothesis. For blue shirts this test would suggest that the data can rule out the null hypothesis yet in the full three ...
Under the null hypothesis and certain conditions (discussed below), the test statistic follows a Chi-Square distribution with degrees of freedom equal to \((r-1)(c-1)\), where \(r\) is the number of rows and \(c\) is the number of columns. ... Let's apply the Chi-Square Test of Independence to our example where we have a random sample of 500 U ...
The chi-square (\(\chi^2\)) test of independence is used to test for a relationship between two categorical variables. Recall that if two categorical variables are independent, then \(P(A) = P(A \mid B)\). ... Null hypothesis: Seat location and cheating are not related in the population. Alternative hypothesis: ...
Under the null hypothesis and certain conditions (discussed below), the test statistic follows a Chi-Square distribution with degrees of freedom equal to \((r-1)(c-1)\), where \(r\) is the number of rows and \(c\) is the number of columns. ... Let's apply the Chi-Square Test of Independence to our example where we have a random sample of 500 U ...
Let's look at the movie-snack data and the Chi-square test of independence using statistical terms. Our null hypothesis is that the type of movie and snack purchases are independent. The null hypothesis is written as: $ H_0: \text{Movie Type and Snack purchases are independent} $ The alternative hypothesis is the opposite.
Example: Chi-square test of independence. Null hypothesis (H 0): The proportion of people who are left-handed is the same for Americans and Canadians. Alternative hypothesis ... You should reject the null hypothesis if the chi-square value is greater than the critical value. If you reject the null hypothesis, you can conclude that your data are ...
The chi-squared test of independence compares our sample data in the contingency table to the distribution of values we'd expect if the null hypothesis is correct. ... Larger values represent a greater difference between your sample data and the null hypothesis. Chi-squared tests are one-tailed tests rather than the more familiar two-tailed ...
A chi-square test can be used to evaluate the hypothesis that two random variables or factors are independent. This page titled 11.1: Chi-Square Tests for Independence is shared under a CC BY-NC-SA 3.0 license and was authored, remixed, and/or curated by Anonymous via source content that was edited to the style and standards of the LibreTexts ...
Applying the chi-square test for independence to sample data, we compute the degrees of freedom, the expected frequency counts, and the chi-square test statistic. Based on the chi-square statistic and the degrees of freedom, we determine the P-value . DF = (r - 1) * (c - 1) = (2 - 1) * (3 - 1) = 2.
The null hypothesis in the χ 2 test of independence is often stated in words as: H 0: ... The chi-square test of independence can also be used with a dichotomous outcome and the results are mathematically equivalent. In the prior module, we considered the following example. Here we show the equivalence to the chi-square test of independence.
The degrees of freedom for the chi-square are calculated using the following formula: df = (r-1)(c-1) where r is the number of rows and c is the number of columns. If the observed chi-square test statistic is greater than the critical value, the null hypothesis can be rejected. Related Pages: Conduct and Interpret the Chi-Square Test of ...
The Chi-Square Test of Independence determines whether there is an association between categorical variables (i.e., whether the variables are independent or related). ... The null hypothesis (H 0) and alternative hypothesis (H 1) of the Chi-Square Test of Independence can be expressed in two different but equivalent ways:
#Perform Chi-Square Test of Independence chisq.test(data) Pearson's Chi-squared test data: data X-squared = 0.86404 , df = 2 ... Since the p-value (0.6492) of the test is not less than 0.05, we fail to reject the null hypothesis. This means we do not have sufficient evidence to say that there is an association between gender and political party ...
The chi-square (\(\chi^2\)) test of independence is used to test for a relationship between two categorical variables. Recall that if two categorical variables are independent, then \(P(A) = P(A \mid B)\). ... the null hypothesis is true). Even if two variables are independent in the population, samples will vary due to random sampling ...
The chi-square independence test evaluates if. two categorical variables are related in some population. Example: a scientist wants to know if education level and marital status are related for all people in some country. He collects data on a simple random sample of n = 300 people, part of which are shown below.
The Chi-square test of independence (also known as the Pearson Chi-square test, or simply the Chi-square) is one of the most useful statistics for testing hypotheses when the variables are nominal, as often happens in clinical research. ... As the P-value of the table is less than P < 0.05, the researcher rejects the null hypothesis and accepts ...
To meet the condition of Large counts for any X^2 Statistic. When specifically does one use a T-test and a chi-square test. A t-test is used to determine the difference between two sets of data. A chi-square test involves looking for a relationship (homogeneity, independence, or goodness-of-fit.)
The third table shows the results of the Chi-Square Test of Independence. The test statistic is .864 and the corresponding two-sided p-value is .649. The null hypothesis for the Chi-Square Test of Independence is that the two variables are independent. In this case, our null hypothesis is that gender and political party preference are independent.
Hypotheses. The Chi-square test of independence is a hypothesis test so it has a null (\(H_0\)) and an alternative hypothesis (\(H_1\)): \(H_0\): the variables are independent, there is no relationship between the two categorical variables. Knowing the value of one variable does not help to predict the value of the other variable
A chi-squared test (also chi-square or ... If the test statistic is improbably large according to that chi-squared distribution, then one rejects the null hypothesis of independence. Here we have a chi-squared value of 24.57, which is quite large, and therefore we have some evidence to reject the null hypothesis(H0). This means each person's ...
You could do the same kind of calculation for each of the cells in this 2 × 2 2 × 2 table of numbers. Once you have each of the four expected numbers, you could compare them to the observed numbers using the chi-square test, just like you did for the chi-square test of goodness-of-fit. The result is chi-square = 2.04 chi-square = 2.04.
Step 1. calculate expected counts under the independence model. Step 2. compare the expected counts E i j to the observed counts O i j. Step 3. calculate X 2 and/or G 2 for testing the hypothesis of independence, and compare the values to the appropriate chi-squared distribution with correct df ( I − 1) ( J − 1)
The sum of the chi-square subtotals, Σ (O − E) 2 /E = 6.529 Q2: Violent Crimes We can now complete the hypothesis test introduced in Example 13.2. Table 13.5 repeats the relative-frequency distribution for violent crimes in the United States in 2010.
View Chi-Square Test for Independence: Understanding & Application from MATH 200 at North Tonawanda High School. Module 12 Section 12.2 Chi Square Statistic Test for Independence 2 2 What is ? ... The idea behind testing these types of claims is to compare actual counts to the counts we would expect if the null hypothesis were true (if the ...