Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base

Hypothesis Testing | A Step-by-Step Guide with Easy Examples
Published on November 8, 2019 by Rebecca Bevans . Revised on June 22, 2023.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics . It is most often used by scientists to test specific predictions, called hypotheses, that arise from theories.
There are 5 main steps in hypothesis testing:
- State your research hypothesis as a null hypothesis and alternate hypothesis (H o ) and (H a or H 1 ).
- Collect data in a way designed to test the hypothesis.
- Perform an appropriate statistical test .
- Decide whether to reject or fail to reject your null hypothesis.
- Present the findings in your results and discussion section.
Though the specific details might vary, the procedure you will use when testing a hypothesis will always follow some version of these steps.
Table of contents
Step 1: state your null and alternate hypothesis, step 2: collect data, step 3: perform a statistical test, step 4: decide whether to reject or fail to reject your null hypothesis, step 5: present your findings, other interesting articles, frequently asked questions about hypothesis testing.
After developing your initial research hypothesis (the prediction that you want to investigate), it is important to restate it as a null (H o ) and alternate (H a ) hypothesis so that you can test it mathematically.
The alternate hypothesis is usually your initial hypothesis that predicts a relationship between variables. The null hypothesis is a prediction of no relationship between the variables you are interested in.
- H 0 : Men are, on average, not taller than women. H a : Men are, on average, taller than women.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

For a statistical test to be valid , it is important to perform sampling and collect data in a way that is designed to test your hypothesis. If your data are not representative, then you cannot make statistical inferences about the population you are interested in.
There are a variety of statistical tests available, but they are all based on the comparison of within-group variance (how spread out the data is within a category) versus between-group variance (how different the categories are from one another).
If the between-group variance is large enough that there is little or no overlap between groups, then your statistical test will reflect that by showing a low p -value . This means it is unlikely that the differences between these groups came about by chance.
Alternatively, if there is high within-group variance and low between-group variance, then your statistical test will reflect that with a high p -value. This means it is likely that any difference you measure between groups is due to chance.
Your choice of statistical test will be based on the type of variables and the level of measurement of your collected data .
- an estimate of the difference in average height between the two groups.
- a p -value showing how likely you are to see this difference if the null hypothesis of no difference is true.
Based on the outcome of your statistical test, you will have to decide whether to reject or fail to reject your null hypothesis.
In most cases you will use the p -value generated by your statistical test to guide your decision. And in most cases, your predetermined level of significance for rejecting the null hypothesis will be 0.05 – that is, when there is a less than 5% chance that you would see these results if the null hypothesis were true.
In some cases, researchers choose a more conservative level of significance, such as 0.01 (1%). This minimizes the risk of incorrectly rejecting the null hypothesis ( Type I error ).
The results of hypothesis testing will be presented in the results and discussion sections of your research paper , dissertation or thesis .
In the results section you should give a brief summary of the data and a summary of the results of your statistical test (for example, the estimated difference between group means and associated p -value). In the discussion , you can discuss whether your initial hypothesis was supported by your results or not.
In the formal language of hypothesis testing, we talk about rejecting or failing to reject the null hypothesis. You will probably be asked to do this in your statistics assignments.
However, when presenting research results in academic papers we rarely talk this way. Instead, we go back to our alternate hypothesis (in this case, the hypothesis that men are on average taller than women) and state whether the result of our test did or did not support the alternate hypothesis.
If your null hypothesis was rejected, this result is interpreted as “supported the alternate hypothesis.”
These are superficial differences; you can see that they mean the same thing.
You might notice that we don’t say that we reject or fail to reject the alternate hypothesis . This is because hypothesis testing is not designed to prove or disprove anything. It is only designed to test whether a pattern we measure could have arisen spuriously, or by chance.
If we reject the null hypothesis based on our research (i.e., we find that it is unlikely that the pattern arose by chance), then we can say our test lends support to our hypothesis . But if the pattern does not pass our decision rule, meaning that it could have arisen by chance, then we say the test is inconsistent with our hypothesis .
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Descriptive statistics
- Measures of central tendency
- Correlation coefficient
Methodology
- Cluster sampling
- Stratified sampling
- Types of interviews
- Cohort study
- Thematic analysis
Research bias
- Implicit bias
- Cognitive bias
- Survivorship bias
- Availability heuristic
- Nonresponse bias
- Regression to the mean
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Null and alternative hypotheses are used in statistical hypothesis testing . The null hypothesis of a test always predicts no effect or no relationship between variables, while the alternative hypothesis states your research prediction of an effect or relationship.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bevans, R. (2023, June 22). Hypothesis Testing | A Step-by-Step Guide with Easy Examples. Scribbr. Retrieved August 13, 2024, from https://www.scribbr.com/statistics/hypothesis-testing/
Is this article helpful?

Rebecca Bevans
Other students also liked, choosing the right statistical test | types & examples, understanding p values | definition and examples, what is your plagiarism score.
- Skip to secondary menu
- Skip to main content
- Skip to primary sidebar
Statistics By Jim
Making statistics intuitive
Hypothesis Testing: Uses, Steps & Example
By Jim Frost 4 Comments
What is Hypothesis Testing?
Hypothesis testing in statistics uses sample data to infer the properties of a whole population . These tests determine whether a random sample provides sufficient evidence to conclude an effect or relationship exists in the population. Researchers use them to help separate genuine population-level effects from false effects that random chance can create in samples. These methods are also known as significance testing.

For example, researchers are testing a new medication to see if it lowers blood pressure. They compare a group taking the drug to a control group taking a placebo. If their hypothesis test results are statistically significant, the medication’s effect of lowering blood pressure likely exists in the broader population, not just the sample studied.
Using Hypothesis Tests
A hypothesis test evaluates two mutually exclusive statements about a population to determine which statement the sample data best supports. These two statements are called the null hypothesis and the alternative hypothesis . The following are typical examples:
- Null Hypothesis : The effect does not exist in the population.
- Alternative Hypothesis : The effect does exist in the population.
Hypothesis testing accounts for the inherent uncertainty of using a sample to draw conclusions about a population, which reduces the chances of false discoveries. These procedures determine whether the sample data are sufficiently inconsistent with the null hypothesis that you can reject it. If you can reject the null, your data favor the alternative statement that an effect exists in the population.
Statistical significance in hypothesis testing indicates that an effect you see in sample data also likely exists in the population after accounting for random sampling error , variability, and sample size. Your results are statistically significant when the p-value is less than your significance level or, equivalently, when your confidence interval excludes the null hypothesis value.
Conversely, non-significant results indicate that despite an apparent sample effect, you can’t be sure it exists in the population. It could be chance variation in the sample and not a genuine effect.
Learn more about Failing to Reject the Null .
5 Steps of Significance Testing
Hypothesis testing involves five key steps, each critical to validating a research hypothesis using statistical methods:
- Formulate the Hypotheses : Write your research hypotheses as a null hypothesis (H 0 ) and an alternative hypothesis (H A ).
- Data Collection : Gather data specifically aimed at testing the hypothesis.
- Conduct A Test : Use a suitable statistical test to analyze your data.
- Make a Decision : Based on the statistical test results, decide whether to reject the null hypothesis or fail to reject it.
- Report the Results : Summarize and present the outcomes in your report’s results and discussion sections.
While the specifics of these steps can vary depending on the research context and the data type, the fundamental process of hypothesis testing remains consistent across different studies.
Let’s work through these steps in an example!
Hypothesis Testing Example
Researchers want to determine if a new educational program improves student performance on standardized tests. They randomly assign 30 students to a control group , which follows the standard curriculum, and another 30 students to a treatment group, which participates in the new educational program. After a semester, they compare the test scores of both groups.
Download the CSV data file to perform the hypothesis testing yourself: Hypothesis_Testing .
The researchers write their hypotheses. These statements apply to the population, so they use the mu (μ) symbol for the population mean parameter .
- Null Hypothesis (H 0 ) : The population means of the test scores for the two groups are equal (μ 1 = μ 2 ).
- Alternative Hypothesis (H A ) : The population means of the test scores for the two groups are unequal (μ 1 ≠ μ 2 ).
Choosing the correct hypothesis test depends on attributes such as data type and number of groups. Because they’re using continuous data and comparing two means, the researchers use a 2-sample t-test .
Here are the results.

The treatment group’s mean is 58.70, compared to the control group’s mean of 48.12. The mean difference is 10.67 points. Use the test’s p-value and significance level to determine whether this difference is likely a product of random fluctuation in the sample or a genuine population effect.
Because the p-value (0.000) is less than the standard significance level of 0.05, the results are statistically significant, and we can reject the null hypothesis. The sample data provides sufficient evidence to conclude that the new program’s effect exists in the population.
Limitations
Hypothesis testing improves your effectiveness in making data-driven decisions. However, it is not 100% accurate because random samples occasionally produce fluky results. Hypothesis tests have two types of errors, both relating to drawing incorrect conclusions.
- Type I error: The test rejects a true null hypothesis—a false positive.
- Type II error: The test fails to reject a false null hypothesis—a false negative.
Learn more about Type I and Type II Errors .
Our exploration of hypothesis testing using a practical example of an educational program reveals its powerful ability to guide decisions based on statistical evidence. Whether you’re a student, researcher, or professional, understanding and applying these procedures can open new doors to discovering insights and making informed decisions. Let this tool empower your analytical endeavors as you navigate through the vast seas of data.
Learn more about the Hypothesis Tests for Various Data Types .
Share this:

Reader Interactions

June 10, 2024 at 10:51 am
Thank you, Jim, for another helpful article; timely too since I have started reading your new book on hypothesis testing and, now that we are at the end of the school year, my district is asking me to perform a number of evaluations on instructional programs. This is where my question/concern comes in. You mention that hypothesis testing is all about testing samples. However, I use all the students in my district when I make these comparisons. Since I am using the entire “population” in my evaluations (I don’t select a sample of third grade students, for example, but I use all 700 third graders), am I somehow misusing the tests? Or can I rest assured that my district’s student population is only a sample of the universal population of students?

June 10, 2024 at 1:50 pm
I hope you are finding the book helpful!
Yes, the purpose of hypothesis testing is to infer the properties of a population while accounting for random sampling error.
In your case, it comes down to how you want to use the results. Who do you want the results to apply to?
If you’re summarizing the sample, looking for trends and patterns, or evaluating those students and don’t plan to apply those results to other students, you don’t need hypothesis testing because there is no sampling error. They are the population and you can just use descriptive statistics. In this case, you’d only need to focus on the practical significance of the effect sizes.
On the other hand, if you want to apply the results from this group to other students, you’ll need hypothesis testing. However, there is the complicating issue of what population your sample of students represent. I’m sure your district has its own unique characteristics, demographics, etc. Your district’s students probably don’t adequately represent a universal population. At the very least, you’d need to recognize any special attributes of your district and how they could bias the results when trying to apply them outside the district. Or they might apply to similar districts in your region.
However, I’d imagine your 3rd graders probably adequately represent future classes of 3rd graders in your district. You need to be alert to changing demographics. At least in the short run I’d imagine they’d be representative of future classes.
Think about how these results will be used. Do they just apply to the students you measured? Then you don’t need hypothesis tests. However, if the results are being used to infer things about other students outside of the sample, you’ll need hypothesis testing along with considering how well your students represent the other students and how they differ.
I hope that helps!
June 10, 2024 at 3:21 pm
Thank you so much, Jim, for the suggestions in terms of what I need to think about and consider! You are always so clear in your explanations!!!!
June 10, 2024 at 3:22 pm
You’re very welcome! Best of luck with your evaluations!
Comments and Questions Cancel reply
Hypothesis Testing Framework
Now that we've seen an example and explored some of the themes for hypothesis testing, let's specify the procedure that we will follow.
Hypothesis Testing Steps
The formal framework and steps for hypothesis testing are as follows:
- Identify and define the parameter of interest
- Define the competing hypotheses to test
- Set the evidence threshold, formally called the significance level
- Generate or use theory to specify the sampling distribution and check conditions
- Calculate the test statistic and p-value
- Evaluate your results and write a conclusion in the context of the problem.
We'll discuss each of these steps below.
Identify Parameter of Interest
First, I like to specify and define the parameter of interest. What is the population that we are interested in? What characteristic are we measuring?
By defining our population of interest, we can confirm that we are truly using sample data. If we find that we actually have population data, our inference procedures are not needed. We could proceed by summarizing our population data.
By identifying and defining the parameter of interest, we can confirm that we use appropriate methods to summarize our variable of interest. We can also focus on the specific process needed for our parameter of interest.
In our example from the last page, the parameter of interest would be the population mean time that a host has been on Airbnb for the population of all Chicago listings on Airbnb in March 2023. We could represent this parameter with the symbol $\mu$. It is best practice to fully define $\mu$ both with words and symbol.
Define the Hypotheses
For hypothesis testing, we need to decide between two competing theories. These theories must be statements about the parameter. Although we won't have the population data to definitively select the correct theory, we will use our sample data to determine how reasonable our "skeptic's theory" is.
The first hypothesis is called the null hypothesis, $H_0$. This can be thought of as the "status quo", the "skeptic's theory", or that nothing is happening.
Examples of null hypotheses include that the population proportion is equal to 0.5 ($p = 0.5$), the population median is equal to 12 ($M = 12$), or the population mean is equal to 14.5 ($\mu = 14.5$).
The second hypothesis is called the alternative hypothesis, $H_a$ or $H_1$. This can be thought of as the "researcher's hypothesis" or that something is happening. This is what we'd like to convince the skeptic to believe. In most cases, the desired outcome of the researcher is to conclude that the alternative hypothesis is reasonable to use moving forward.
Examples of alternative hypotheses include that the population proportion is greater than 0.5 ($p > 0.5$), the population median is less than 12 ($M < 12$), or the population mean is not equal to 14.5 ($\mu \neq 14.5$).
There are a few requirements for the hypotheses:
- the hypotheses must be about the same population parameter,
- the hypotheses must have the same null value (provided number to compare to),
- the null hypothesis must have the equality (the equals sign must be in the null hypothesis),
- the alternative hypothesis must not have the equality (the equals sign cannot be in the alternative hypothesis),
- there must be no overlap between the null and alternative hypothesis.
You may have previously seen null hypotheses that include more than an equality (e.g. $p \le 0.5$). As long as there is an equality in the null hypothesis, this is allowed. For our purposes, we will simplify this statement to ($p = 0.5$).
To summarize from above, possible hypotheses statements are:
$H_0: p = 0.5$ vs. $H_a: p > 0.5$
$H_0: M = 12$ vs. $H_a: M < 12$
$H_0: \mu = 14.5$ vs. $H_a: \mu \neq 14.5$
In our second example about Airbnb hosts, our hypotheses would be:
$H_0: \mu = 2100$ vs. $H_a: \mu > 2100$.
Set Threshold (Significance Level)
There is one more step to complete before looking at the data. This is to set the threshold needed to convince the skeptic. This threshold is defined as an $\alpha$ significance level. We'll define exactly what the $\alpha$ significance level means later. For now, smaller $\alpha$s correspond to more evidence being required to convince the skeptic.
A few common $\alpha$ levels include 0.1, 0.05, and 0.01.
For our Airbnb hosts example, we'll set the threshold as 0.02.
Determine the Sampling Distribution of the Sample Statistic
The first step (as outlined above) is the identify the parameter of interest. What is the best estimate of the parameter of interest? Typically, it will be the sample statistic that corresponds to the parameter. This sample statistic, along with other features of the distribution will prove especially helpful as we continue the hypothesis testing procedure.
However, we do have a decision at this step. We can choose to use simulations with a resampling approach or we can choose to rely on theory if we are using proportions or means. We then also need to confirm that our results and conclusions will be valid based on the available data.
Required Condition
The one required assumption, regardless of approach (resampling or theory), is that the sample is random and representative of the population of interest. In other words, we need our sample to be a reasonable sample of data from the population.
Using Simulations and Resampling
If we'd like to use a resampling approach, we have no (or minimal) additional assumptions to check. This is because we are relying on the available data instead of assumptions.
We do need to adjust our data to be consistent with the null hypothesis (or skeptic's claim). We can then rely on our resampling approach to estimate a plausible sampling distribution for our sample statistic.
Recall that we took this approach on the last page. Before simulating our estimated sampling distribution, we adjusted the mean of the data so that it matched with our skeptic's claim, shown in the code below.
We'll see a few more examples on the next page.
Using Theory
On the other hand, we could rely on theory in order to estimate the sampling distribution of our desired statistic. Recall that we had a few different options to rely on:
- the CLT for the sampling distribution of a sample mean
- the binomial distribution for the sampling distribution of a proportion (or count)
- the Normal approximation of a binomial distribution (using the CLT) for the sampling distribution of a proportion
If relying on the CLT to specify the underlying sampling distribution, you also need to confirm:
- having a random sample and
- having a sample size that is less than 10% of the population size if the sampling is done without replacement
- having a Normally distributed population for a quantitative variable OR
- having a large enough sample size (usually at least 25) for a quantitative variable
- having a large enough sample size for a categorical variable (defined by $np$ and $n(1-p)$ being at least 10)
If relying on the binomial distribution to specify the underlying sampling distribution, you need to confirm:
- having a set number of trials, $n$
- having the same probability of success, $p$ for each observation
After determining the appropriate theory to use, we should check our conditions and then specify the sampling distribution for our statistic.
For the Airbnb hosts example, we have what we've assumed to be a random sample. It is not taken with replacement, so we also need to assume that our sample size (700) is less than 10% of our population size. In other words, we need to assume that the population of Chicago Airbnbs in March 2023 was at least 7000. Since we do have our (presumed) population data available, we can confirm that there were at least 7000 Chicago Airbnbs in the population in 2023.
Additionally, we can confirm that normality of the sampling distribution applies for the CLT to apply. Our sample size is more than 25 and the parameter of interest is a mean, so this meets our necessary criteria for the normality condition to be valid.
With the conditions now met, we can estimate our sampling distribution. From the CLT, we know that the distribution for the sample mean should be $\bar{X} \sim N(\mu, \frac{\sigma}{\sqrt{n}})$.
Now, we face our next challenge -- what to plug in as the mean and standard error for this distribution. Since we are adopting the skeptic's point of view for the purpose of this approach, we can plug in the value of $\mu_0 = 2100$. We also know that the sample size $n$ is 700. But what should we plug in for the population standard deviation $\sigma$?
When we don't know the value of a parameter, we will generally plug in our best estimate for the parameter. In this case, that corresponds to plugging in $\hat{\sigma}$, or our sample standard deviation.
Now, our estimated sampling distribution based on the CLT is: $\bar{X} \sim N(2100, 41.4045)$.
If we compare to our corresponding skeptic's sampling distribution on the last page, we can confirm that the theoretical sampling distribution is similar to the simulated sampling distribution based on resampling.
Assumptions not met
What do we do if the necessary conditions aren't met for the sampling distribution? Because the simulation-based resampling approach has minimal assumptions, we should be able to use this approach to produce valid results as long as the provided data is representative of the population.
The theory-based approach has more conditions, and we may not be able to meet all of the necessary conditions. For example, if our parameter is something other than a mean or proportion, we may not have appropriate theory. Additionally, we may not have a large enough sample size.
- First, we could consider changing approaches to the simulation-based one.
- Second, we might look at how we could meet the necessary conditions better. In some cases, we may be able to redefine groups or make adjustments so that the setup of the test is closer to what is needed.
- As a last resort, we may be able to continue following the hypothesis testing steps. In this case, your calculations may not be valid or exact; however, you might be able to use them as an estimate or an approximation. It would be crucial to specify the violation and approximation in any conclusions or discussion of the test.
Calculate the evidence with statistics and p-values
Now, it's time to calculate how much evidence the sample contains to convince the skeptic to change their mind. As we saw above, we can convince the skeptic to change their mind by demonstrating that our sample is unlikely to occur if their theory is correct.
How do we do this? We do this by calculating a probability associated with our observed value for the statistic.
For example, for our situation, we want to convince the skeptic that the population mean is actually greater than 2100 days. We do that by calculating the probability that a sample mean would be as large or larger than what we observed in our actual sample, which was 2188 days. Why do we need the larger portion? We use the larger portion because a sample mean of 2200 days also provides evidence that the population mean is larger than 2100 days; it isn't limited to exactly what we observed in our sample. We call this specific probability the p-value.
That is, the p-value is the probability of observing a test statistic as extreme or more extreme (as determined by the alternative hypothesis), assuming the null hypothesis is true.
Our observed p-value for the Airbnb host example demonstrates that the probability of getting a sample mean host time of 2188 days (the value from our sample) or more is 1.46%, assuming that the true population mean is 2100 days.
Test statistic
Notice that the formal definition of a p-value mentions a test statistic . In most cases, this word can be replaced with "statistic" or "sample" for an equivalent statement.
Oftentimes, we'll see that our sample statistic can be used directly as the test statistic, as it was above. We could equivalently adjust our statistic to calculate a test statistic. This test statistic is often calculated as:
$\text{test statistic} = \frac{\text{estimate} - \text{hypothesized value}}{\text{standard error of estimate}}$
P-value Calculation Options
Note also that the p-value definition includes a probability associated with a test statistic being as extreme or more extreme (as determined by the alternative hypothesis . How do we determine the area that we consider when calculating the probability. This decision is determined by the inequality in the alternative hypothesis.
For example, when we were trying to convince the skeptic that the population mean is greater than 2100 days, we only considered those sample means that we at least as large as what we observed -- 2188 days or more.
If instead we were trying to convince the skeptic that the population mean is less than 2100 days ($H_a: \mu < 2100$), we would consider all sample means that were at most what we observed - 2188 days or less. In this case, our p-value would be quite large; it would be around 99.5%. This large p-value demonstrates that our sample does not support the alternative hypothesis. In fact, our sample would encourage us to choose the null hypothesis instead of the alternative hypothesis of $\mu < 2100$, as our sample directly contradicts the statement in the alternative hypothesis.
If we wanted to convince the skeptic that they were wrong and that the population mean is anything other than 2100 days ($H_a: \mu \neq 2100$), then we would want to calculate the probability that a sample mean is at least 88 days away from 2100 days. That is, we would calculate the probability corresponding to 2188 days or more or 2012 days or less. In this case, our p-value would be roughly twice the previously calculated p-value.
We could calculate all of those probabilities using our sampling distributions, either simulated or theoretical, that we generated in the previous step. If we chose to calculate a test statistic as defined in the previous section, we could also rely on standard normal distributions to calculate our p-value.
Evaluate your results and write conclusion in context of problem
Once you've gathered your evidence, it's now time to make your final conclusions and determine how you might proceed.
In traditional hypothesis testing, you often make a decision. Recall that you have your threshold (significance level $\alpha$) and your level of evidence (p-value). We can compare the two to determine if your p-value is less than or equal to your threshold. If it is, you have enough evidence to persuade your skeptic to change their mind. If it is larger than the threshold, you don't have quite enough evidence to convince the skeptic.
Common formal conclusions (if given in context) would be:
- I have enough evidence to reject the null hypothesis (the skeptic's claim), and I have sufficient evidence to suggest that the alternative hypothesis is instead true.
- I do not have enough evidence to reject the null hypothesis (the skeptic's claim), and so I do not have sufficient evidence to suggest the alternative hypothesis is true.
The only decision that we can make is to either reject or fail to reject the null hypothesis (we cannot "accept" the null hypothesis). Because we aren't actively evaluating the alternative hypothesis, we don't want to make definitive decisions based on that hypothesis. However, when it comes to making our conclusion for what to use going forward, we frame this on whether we could successfully convince someone of the alternative hypothesis.
A less formal conclusion might look something like:
Based on our sample of Chicago Airbnb listings, it seems as if the mean time since a host has been on Airbnb (for all Chicago Airbnb listings) is more than 5.75 years.
Significance Level Interpretation
We've now seen how the significance level $\alpha$ is used as a threshold for hypothesis testing. What exactly is the significance level?
The significance level $\alpha$ has two primary definitions. One is that the significance level is the maximum probability required to reject the null hypothesis; this is based on how the significance level functions within the hypothesis testing framework. The second definition is that this is the probability of rejecting the null hypothesis when the null hypothesis is true; in other words, this is the probability of making a specific type of error called a Type I error.
Why do we have to be comfortable making a Type I error? There is always a chance that the skeptic was originally correct and we obtained a very unusual sample. We don't want to the skeptic to be so convinced of their theory that no evidence can convince them. In this case, we need the skeptic to be convinced as long as the evidence is strong enough . Typically, the probability threshold will be low, to reduce the number of errors made. This also means that a decent amount of evidence will be needed to convince the skeptic to abandon their position in favor of the alternative theory.
p-value Limitations and Misconceptions
In comparison to the $\alpha$ significance level, we also need to calculate the evidence against the null hypothesis with the p-value.
The p-value is the probability of getting a test statistic as extreme or more extreme (in the direction of the alternative hypothesis), assuming the null hypothesis is true.
Recently, p-values have gotten some bad press in terms of how they are used. However, that doesn't mean that p-values should be abandoned, as they still provide some helpful information. Below, we'll describe what p-values don't mean, and how they should or shouldn't be used to make decisions.
Factors that affect a p-value
What features affect the size of a p-value?
- the null value, or the value assumed under the null hypothesis
- the effect size (the difference between the null value under the null hypothesis and the true value of the parameter)
- the sample size
More evidence against the null hypothesis will be obtained if the effect size is larger and if the sample size is larger.
Misconceptions
We gave a definition for p-values above. What are some examples that p-values don't mean?
- A p-value is not the probability that the null hypothesis is correct
- A p-value is not the probability that the null hypothesis is incorrect
- A p-value is not the probability of getting your specific sample
- A p-value is not the probability that the alternative hypothesis is correct
- A p-value is not the probability that the alternative hypothesis is incorrect
- A p-value does not indicate the size of the effect
Our p-value is a way of measuring the evidence that your sample provides against the null hypothesis, assuming the null hypothesis is in fact correct.
Using the p-value to make a decision
Why is there bad press for a p-value? You may have heard about the standard $\alpha$ level of 0.05. That is, we would be comfortable with rejecting the null hypothesis once in 20 attempts when the null hypothesis is really true. Recall that we reject the null hypothesis when the p-value is less than or equal to the significance level.
Consider what would happen if you have two different p-values: 0.049 and 0.051.
In essence, these two p-values represent two very similar probabilities (4.9% vs. 5.1%) and very similar levels of evidence against the null hypothesis. However, when we make our decision based on our threshold, we would make two different decisions (reject and fail to reject, respectively). Should this decision really be so simplistic? I would argue that the difference shouldn't be so severe when the sample statistics are likely very similar. For this reason, I (and many other experts) strongly recommend using the p-value as a measure of evidence and including it with your conclusion.
Putting too much emphasis on the decision (and having a significant result) has created a culture of misusing p-values. For this reason, understanding your p-value itself is crucial.
Searching for p-values
The other concern with setting a definitive threshold of 0.05 is that some researchers will begin performing multiple tests until finding a p-value that is small enough. However, with a p-value of 0.05, we know that we will have a p-value less than 0.05 1 time out of every 20 times, even when the null hypothesis is true.
This means that if researchers start hunting for p-values that are small (sometimes called p-hacking), then they are likely to identify a small p-value every once in a while by chance alone. Researchers might then publish that result, even though the result is actually not informative. For this reason, it is recommended that researchers write a definitive analysis plan to prevent performing multiple tests in search of a result that occurs by chance alone.
Best Practices
With all of this in mind, what should we do when we have our p-value? How can we prevent or reduce misuse of a p-value?
- Report the p-value along with the conclusion
- Specify the effect size (the value of the statistic)
- Define an analysis plan before looking at the data
- Interpret the p-value clearly to specify what it indicates
- Consider using an alternate statistical approach, the confidence interval, discussed next, when appropriate
Hypothesis Testing
When you conduct a piece of quantitative research, you are inevitably attempting to answer a research question or hypothesis that you have set. One method of evaluating this research question is via a process called hypothesis testing , which is sometimes also referred to as significance testing . Since there are many facets to hypothesis testing, we start with the example we refer to throughout this guide.
An example of a lecturer's dilemma
Two statistics lecturers, Sarah and Mike, think that they use the best method to teach their students. Each lecturer has 50 statistics students who are studying a graduate degree in management. In Sarah's class, students have to attend one lecture and one seminar class every week, whilst in Mike's class students only have to attend one lecture. Sarah thinks that seminars, in addition to lectures, are an important teaching method in statistics, whilst Mike believes that lectures are sufficient by themselves and thinks that students are better off solving problems by themselves in their own time. This is the first year that Sarah has given seminars, but since they take up a lot of her time, she wants to make sure that she is not wasting her time and that seminars improve her students' performance.
The research hypothesis
The first step in hypothesis testing is to set a research hypothesis. In Sarah and Mike's study, the aim is to examine the effect that two different teaching methods – providing both lectures and seminar classes (Sarah), and providing lectures by themselves (Mike) – had on the performance of Sarah's 50 students and Mike's 50 students. More specifically, they want to determine whether performance is different between the two different teaching methods. Whilst Mike is skeptical about the effectiveness of seminars, Sarah clearly believes that giving seminars in addition to lectures helps her students do better than those in Mike's class. This leads to the following research hypothesis:
| Research Hypothesis: | When students attend seminar classes, in addition to lectures, their performance increases. |
Before moving onto the second step of the hypothesis testing process, we need to take you on a brief detour to explain why you need to run hypothesis testing at all. This is explained next.
Sample to population
If you have measured individuals (or any other type of "object") in a study and want to understand differences (or any other type of effect), you can simply summarize the data you have collected. For example, if Sarah and Mike wanted to know which teaching method was the best, they could simply compare the performance achieved by the two groups of students – the group of students that took lectures and seminar classes, and the group of students that took lectures by themselves – and conclude that the best method was the teaching method which resulted in the highest performance. However, this is generally of only limited appeal because the conclusions could only apply to students in this study. However, if those students were representative of all statistics students on a graduate management degree, the study would have wider appeal.
In statistics terminology, the students in the study are the sample and the larger group they represent (i.e., all statistics students on a graduate management degree) is called the population . Given that the sample of statistics students in the study are representative of a larger population of statistics students, you can use hypothesis testing to understand whether any differences or effects discovered in the study exist in the population. In layman's terms, hypothesis testing is used to establish whether a research hypothesis extends beyond those individuals examined in a single study.
Another example could be taking a sample of 200 breast cancer sufferers in order to test a new drug that is designed to eradicate this type of cancer. As much as you are interested in helping these specific 200 cancer sufferers, your real goal is to establish that the drug works in the population (i.e., all breast cancer sufferers).
As such, by taking a hypothesis testing approach, Sarah and Mike want to generalize their results to a population rather than just the students in their sample. However, in order to use hypothesis testing, you need to re-state your research hypothesis as a null and alternative hypothesis. Before you can do this, it is best to consider the process/structure involved in hypothesis testing and what you are measuring. This structure is presented on the next page .
- How it Works
Call us: +1 – 732 510 0607
Email: [email protected]
Linkedin / Twitter
Hypothesis Testing in Statistics: Step by Step with Examples
Hypothesis testing is the act of statistically evaluating a belief or theory. Hypothesis testing is the process of testing your theory using data from the real world obtained either through observation or experiments. Hypothesis testing is the step-by-step process of analyzing empirical data to check if it differs from the expected numbers if the belief or theory you started with was true.
This article walks you through the hypothesis testing concept and lists the process of hypothesis testing step by step.
To illustrate the concept and show you the hypothesis testing process with a example, we evaluate a belief that the companies in the Russell 3000 grow at a rate greater than 10% per year.
Here is a list of subtopics if you want to jump ahead:
Hypothesis Testing: Step by Step
Structuring the hypothesis test: the null and alternate hypothesis, the null hypothesis.
- The Alternate Hypthesis
- Significance level
- Sample Size and Sampling to get the test statistic
Setting up the Critical Value & Reject Regions
Computing the test statistic.
- Comparing the Test Statistic Vs. the Critical Values
Concluding the Hypothesis Test
A hypothesis test and a criminal trial: similarities, the sampling distribution, reject region in hypothesis testing, some facts on the null hypothesis, some facts on the alternate hypothesis.
If you already know the concept of hypothesis testing concept and you only need to follow the step-by-step process outlined below.
- State the null hypothesis
- State the alternate hypothesis
- Decide on the level of significance
- Choose the sample size
- Determine the statistical technique
- Set up the critical values to identify the reject region and non-reject region
- Collect the data sample and compute sample parameters & Test statistic
- Compare sample/test statistic with critical value/reject or non-reject region.
- Make your conclusion clear.
List of Topics
A hypothesis test starts with a hypothesis that you want to test. It is designed as a statement or belief that you are examining. This statement or belief is termed the null hypothesis. The null hypothesis is what the hypothesis test is evaluating.
The Alternate Hypothesis
The opposite of the null hypothesis is called an alternate hypothesis. We are not examining the alternate hypothesis. Instead, the alternate hypothesis is what remains if the null hypothesis is rejected after being examined.
We will talk more about designing the null and alternate hypotheses later. Remember that we place what we want to prove in the alternate hypothesis. And we put the opposite of what we want to prove in the null hypothesis.
To continue our example, we will place what we believe to be true (mean growth rate is great than 10%) in the alternate hypothesis. And the opposite of the alternate hypothesis (mean growth rate is less than or equal to 10%) in the null hypothesis. Accordingly, we will have the following null and alternate hypotheses for our example: Ho: Mean growth rate <= 10% Ha: Mean growth rate > 10%
If we reject the null hypothesis, we will be concluding that the alternate hypothesis stands. On the other hand, if the evidence does not provide evidence to reject the null hypothesis, we can only conclude that we cannot reject the null hypothesis. In other words, we have not proven the alternate hypothesis. We conclude that we cannot reject the null hypothesis and therefore make no claim to have proven the alternate hypothesis or our starting theory or belief!
Significance Level
In hypothesis testing, the evidence required is gathered from a sample of the relevant population. Then, the parameter of interest from the sample is computed and referred to as the test statistic. This test statistic informs us about the null hypothesis.
Even if the null hypothesis is true, the test statistic is unlikely to be exactly equal to the parameter of interest of the true population because we are basing our test statistic on a sample of the population! A sample is only an unbiased estimator and not the actual population parameter. However, if the null hypothesis is true, the test statistic is likely to be close to the null hypothesis value, and likely agree with the null hypothesis. How close should it be? Or how far away from the null hypothesis value should the test statistic be before we can conclude that the null hypothesis is not true and “can be rejected”?
This is where the significance level comes into play. The significance level is the level of certainty required to reject the null hypothesis. The most commonly used significance levels are 1%, 5%, or 10% in practice. The significance level should be determined by the type of errors we are willing to tolerate (type 1 or type 2 errors).
We will use a 5% level of significance in our example today.
Significance level helps us determine the point beyond which we say that the null hypothesis is not true and “can be rejected”!
Best practice dictates that the critical value must be set up at the design stage and before the hypothesis test is done. The critical value is based on two factors. 1) the sampling distribution and 2) significance levels.

The sampling distribution is a distribution of sample values we can expect if the null hypothesis were true. Theoretically, the sample distribution is the distribution we would get if we took all possible samples that covered the entire population. The reason the sample distribution is central to hypothesis testing is that the mean of the sample distribution will equal the mean of the true population. So we use the sample distribution to evaluate the sample test statistic and check if our data agree with the null hypothesis.
If our null hypothesis is true, the test statistic will lie close to the middle of the sampling distribution. However, if our null hypothesis is NOT true, the test statistic will likely be closer to the tails of the sampling distribution.
To make a firm decision, we need a point beyond which we say that the null hypothesis is not true. That point is referred to as the critical value. The region beyond the critical value is referred to as the critical region or the reject region. If the test statistic falls in this region, we reject the null hypothesis. We conclude that the alternate hypothesis is true.
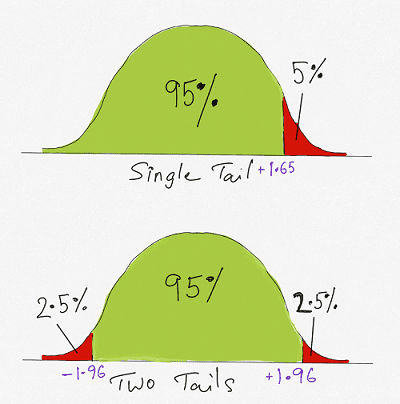
In our example, we are looking for a 5% confidence level. Therefore the critical value and reject region will be computed using a 5% confidence level. The critical value and reject region can be computed using the Z table, Microsoft Excel or another software program.
In Microsoft Excel we use the =NORM.S.INV(0.95) for a single tail critical value of 1.645 as the z value. We can use the Z table to arrive at the same value too.
Once we have the critical value, we run the experiment or gather sample data. Then, we analyze the sample data and compute the sample parameter of interest.
In our example, we randomly sample __ companies of the Russell 3000. We compute the average growth rates of the sample. We then compute the test statistic using this formula.
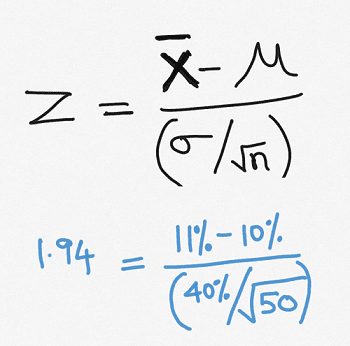
Comparing the Test Statistic and the Critical Value
We compare the sample parameter of interest with the critical value/critical region. We are essentially checking if the test statistic falls in the reject region.
We are ready to conclude the hypothesis test only when we have the sample parameter of interest and the critical value at hand. We check if the parameter of interest falls in the critical regions identified in the earlier step.
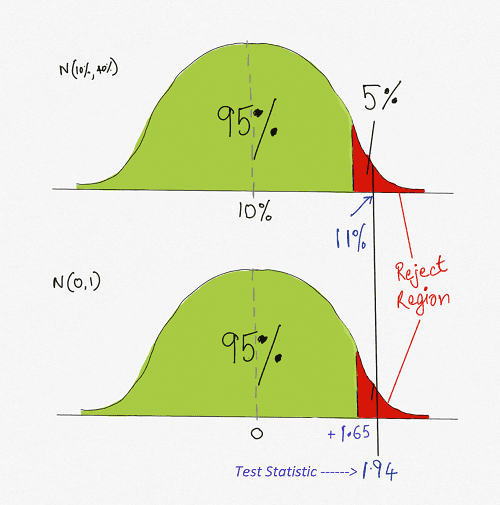
In our example, we can see that the test statistic falls in the reject region.
If the parameter of interest falls in the critical regions, we reject the null hypothesis. Only when we reject the null hypothesis can we conclude that we believe the alternate hypothesis!
In our example, we can conclude that we reject the null hypothesis as the test statistic falls in the reject region. Because we reject the null hypothesis, we can say we believe the alternate hypothesis is true. And we conclude that the growth rate of companies of the Russell 3000 is greater than 10% per year!
A hypothesis test is often compared to and explained as a criminal trial. In a criminal trial, we start with the belief “innocent until proven guilty.” Similarly, in hypothesis testing, we assume that the null hypothesis is true. Therefore, we need to present data to disprove the null hypothesis. That is why we say that hypothesis testing is a trial of the null hypothesis. It is not the alternate hypothesis we are testing! The null hypothesis is similar to the criminal defendant. The data scientist is similar to the prosecutor. It is the prosecutor’s job to prove that the criminal is guilty. The prosecutor or the data scientist/researcher examines the data to present evidence that the null hypothesis is not true. Only if the researcher presents data to prove the null hypothesis is not true, can we conclude that that alternate hypothesis is true. If we do not have evidence to prove the criminal is guilty, he escapes conviction. It does not mean he is truly innocent. It only means that he was not found guilty. Similarly, if we do not have evidence to reject the null hypothesis we can only conclude that we cannot reject the null hypothesis.
- The null hypothesis is the current belief.
- You are examining or testing the null hypothesis.
- The null hypothesis refers to a specific parameter/value of the true population (not the sample parameter)
- The null hypothesis contains the “equal to” parameter
- If you reject the null hypothesis, you have statistical proof that the alternate hypothesis is true.
- Failure to reject the null hypothesis does not mean you have statistical proof that the null hypothesis is true.
- The alternate hypothesis is what the researcher wants to prove statistically.
- The alternate hypothesis is the opposite of the null hypothesis.
- The failure to prove the alternate hypothesis does not mean that you have proven the null hypothesis.
- The alternate hypothesis usually does not contain the “equal to” parameter.
Sample Size and Sampling to get the Test Statistic
We are looking for evidence that the null hypothesis is not true and “can be rejected”. This evidence is provided by a sample. How should this sample be gathered? How large should the sample be to provide this evidence? The sample must be carefully selected to be representative of the true population of interest. A random sample is best. Other sampling methods include cluster sampling, cluster sampling, stratified sampling, convenience sampling, etc. Each has its advantages and disadvantages, which we will not go into here.
Selecting the sample size is important in hypothesis testing. The sample size chosen impacts the risk of Type I and Type 2 errors. The sample size also directly determines the confidence levels and the power of the test. The sample size formula can be resorted to arrive at the sample size.
Hypothesis Testing Tutoring
Please do let us know if we can help you with tutoring for hypothesis testing. Our statistics tutors will be happy to meet with you one on one to help you understand and design and perform a hypothesis test.
Sign Up Now
Recent Posts
- MBA Tutoring for Operations Management & Research at Chicago Booth School of Business
- Private Tutoring for Operations Management at the Darden Business School, UVA
- Private Tutoring for Financial Management and Policies I & II at Darden Business School, UVA
- Private Tutoring for Global Economies and Markets (GEM) at Darden Business School, UVA
- Tutoring for ‘Accounting for Managers’ at Darden Business School, UVA
GraduateTutor.com Forest View Drive Avenel, NJ 07001 Call us:+1 – (732) 510-0607, E-mail: [email protected] Privacy , FAQ
Core Areas of Tutoring
Sign up now.
6a.2 - Steps for Hypothesis Tests
The logic of hypothesis testing.
A hypothesis, in statistics, is a statement about a population parameter, where this statement typically is represented by some specific numerical value. In testing a hypothesis, we use a method where we gather data in an effort to gather evidence about the hypothesis.
How do we decide whether to reject the null hypothesis?
- If the sample data are consistent with the null hypothesis, then we do not reject it.
- If the sample data are inconsistent with the null hypothesis, but consistent with the alternative, then we reject the null hypothesis and conclude that the alternative hypothesis is true.
Six Steps for Hypothesis Tests
In hypothesis testing, there are certain steps one must follow. Below these are summarized into six such steps to conducting a test of a hypothesis.
- Set up the hypotheses and check conditions : Each hypothesis test includes two hypotheses about the population. One is the null hypothesis, notated as \(H_0 \), which is a statement of a particular parameter value. This hypothesis is assumed to be true until there is evidence to suggest otherwise. The second hypothesis is called the alternative, or research hypothesis, notated as \(H_a \). The alternative hypothesis is a statement of a range of alternative values in which the parameter may fall. One must also check that any conditions (assumptions) needed to run the test have been satisfied e.g. normality of data, independence, and number of success and failure outcomes.
- Decide on the significance level, \(\alpha \): This value is used as a probability cutoff for making decisions about the null hypothesis. This alpha value represents the probability we are willing to place on our test for making an incorrect decision in regards to rejecting the null hypothesis. The most common \(\alpha \) value is 0.05 or 5%. Other popular choices are 0.01 (1%) and 0.1 (10%).
- Calculate the test statistic: Gather sample data and calculate a test statistic where the sample statistic is compared to the parameter value. The test statistic is calculated under the assumption the null hypothesis is true and incorporates a measure of standard error and assumptions (conditions) related to the sampling distribution.
- Calculate probability value (p-value), or find the rejection region: A p-value is found by using the test statistic to calculate the probability of the sample data producing such a test statistic or one more extreme. The rejection region is found by using alpha to find a critical value; the rejection region is the area that is more extreme than the critical value. We discuss the p-value and rejection region in more detail in the next section.
- Make a decision about the null hypothesis: In this step, we decide to either reject the null hypothesis or decide to fail to reject the null hypothesis. Notice we do not make a decision where we will accept the null hypothesis.
- State an overall conclusion : Once we have found the p-value or rejection region, and made a statistical decision about the null hypothesis (i.e. we will reject the null or fail to reject the null), we then want to summarize our results into an overall conclusion for our test.
We will follow these six steps for the remainder of this Lesson. In the future Lessons, the steps will be followed but may not be explained explicitly.
Step 1 is a very important step to set up correctly. If your hypotheses are incorrect, your conclusion will be incorrect. In this next section, we practice with Step 1 for the one sample situations.
The 5 Easy Steps to Hypothesis Testing
I would like to make the process of understanding hypothesis testing much simpler for students need help learning statistics . Hypothesis testing is a five-step procedure. Let’s address the difficulties of students while they learn the topic of hypothesis testing.
Step 1: Identifying the claim and designing null and alternative hypothesis
Students should first identify the research claim: A research claim is a statement or condition that is being tested.
Now if the claim is to test that there is NO difference between or to test if the given value is EQUAL to any number, in this case, we consider the claim as a null hypothesis.
In contrast, if the claim is to test that there is a difference or to test if the given number is NOT equal to/greater than/less than any given number, in this case, we consider the claim as an alternative hypothesis.
We represent the Null hypothesis symbolically with H0 and the alternative hypothesis with Ha or H1
Step 2: Identifying the tail of the test and notifying the significance level if given
Here, students are posed with the question: how do I identify the tail of the f test?
- It is simple if the alternative hypothesis is directional with the statement (greater than or less than) then the claim is ONE tailed.
- If the claim is with the statement NOT equal to-it is TWO tailed.
So when the claim is directional, it is a one-tailed test and when the claim is non-directional, it is a two-tailed test!
Step 3: Identifying the type of statistical test to be identified and to compute test statistic
Well there are different test statistics we compute while working with test statistics.
To start off, if we are testing one sample mean when the sample size is small (less than 30) and the standard deviation is unknown, we compute test statistic t for the same condition. When the standard deviation is known, we compute test statistic Z. We have different formulas listed for computing the Z test for one sample proportion and the difference between means and then the difference between proportions, so here to compute the test statistic we must identify the type of statistical test to be performed.
Step 4: Writing decisions
This is again a very confusing part to most of the students. There are two methods to write decisions, so students should be familiar with the method taught in class.
The first method is: P-Value Approach In the p-value approach, we compare the p-value of the test statistic with the alpha/significance level.
- When the p-value is <(less than) Alpha we reject H0
- When the p-value is >(greater than) Alpha we fail to reject H0
The second method is: Critical Value Approach So in this method, we compare test statistics obtained with the critical value of the test conducted
- When the test statistic is less than (<) critical value of the test we fail to reject H0
- When the test statistic is greater than(>) critical value of the test we reject H0
Step 5: Drawing conclusions
Students should match the decision results while making conclusions when we reject the null hypothesis we conclude that we have enough evidence.
To support the claim (in this case the claim will be an alternative hypothesis), we say the test is statistically significant.
When we reject the null hypothesis and say that we do not have enough evidence to support the claim (in this case the null hypothesis is the claim), we say the test is not statistically significant.

Hi, I'm Naga! I am an expert statistics, algebra, and calculus tutor with TutorOcean.
- The Story of the Box Plot
Related Posts

What Is a Tutor?

Online Tutoring | Traditional to Transglobal

Here Are the Six Attributes That Make a Great Teacher
- Search Search Please fill out this field.
What Is Hypothesis Testing?
- How It Works
4 Step Process
The bottom line.
- Fundamental Analysis
Hypothesis Testing: 4 Steps and Example
:max_bytes(150000):strip_icc():format(webp)/ChristinaMajaski-5c9433ea46e0fb0001d880b1.jpeg "5 steps procedure for hypothesis testing")
Hypothesis testing, sometimes called significance testing, is an act in statistics whereby an analyst tests an assumption regarding a population parameter. The methodology employed by the analyst depends on the nature of the data used and the reason for the analysis.
Hypothesis testing is used to assess the plausibility of a hypothesis by using sample data. Such data may come from a larger population or a data-generating process. The word "population" will be used for both of these cases in the following descriptions.
Key Takeaways
- Hypothesis testing is used to assess the plausibility of a hypothesis by using sample data.
- The test provides evidence concerning the plausibility of the hypothesis, given the data.
- Statistical analysts test a hypothesis by measuring and examining a random sample of the population being analyzed.
- The four steps of hypothesis testing include stating the hypotheses, formulating an analysis plan, analyzing the sample data, and analyzing the result.
How Hypothesis Testing Works
In hypothesis testing, an analyst tests a statistical sample, intending to provide evidence on the plausibility of the null hypothesis. Statistical analysts measure and examine a random sample of the population being analyzed. All analysts use a random population sample to test two different hypotheses: the null hypothesis and the alternative hypothesis.
The null hypothesis is usually a hypothesis of equality between population parameters; e.g., a null hypothesis may state that the population mean return is equal to zero. The alternative hypothesis is effectively the opposite of a null hypothesis. Thus, they are mutually exclusive , and only one can be true. However, one of the two hypotheses will always be true.
The null hypothesis is a statement about a population parameter, such as the population mean, that is assumed to be true.
- State the hypotheses.
- Formulate an analysis plan, which outlines how the data will be evaluated.
- Carry out the plan and analyze the sample data.
- Analyze the results and either reject the null hypothesis, or state that the null hypothesis is plausible, given the data.
Example of Hypothesis Testing
If an individual wants to test that a penny has exactly a 50% chance of landing on heads, the null hypothesis would be that 50% is correct, and the alternative hypothesis would be that 50% is not correct. Mathematically, the null hypothesis is represented as Ho: P = 0.5. The alternative hypothesis is shown as "Ha" and is identical to the null hypothesis, except with the equal sign struck-through, meaning that it does not equal 50%.
A random sample of 100 coin flips is taken, and the null hypothesis is tested. If it is found that the 100 coin flips were distributed as 40 heads and 60 tails, the analyst would assume that a penny does not have a 50% chance of landing on heads and would reject the null hypothesis and accept the alternative hypothesis.
If there were 48 heads and 52 tails, then it is plausible that the coin could be fair and still produce such a result. In cases such as this where the null hypothesis is "accepted," the analyst states that the difference between the expected results (50 heads and 50 tails) and the observed results (48 heads and 52 tails) is "explainable by chance alone."
When Did Hypothesis Testing Begin?
Some statisticians attribute the first hypothesis tests to satirical writer John Arbuthnot in 1710, who studied male and female births in England after observing that in nearly every year, male births exceeded female births by a slight proportion. Arbuthnot calculated that the probability of this happening by chance was small, and therefore it was due to “divine providence.”
What are the Benefits of Hypothesis Testing?
Hypothesis testing helps assess the accuracy of new ideas or theories by testing them against data. This allows researchers to determine whether the evidence supports their hypothesis, helping to avoid false claims and conclusions. Hypothesis testing also provides a framework for decision-making based on data rather than personal opinions or biases. By relying on statistical analysis, hypothesis testing helps to reduce the effects of chance and confounding variables, providing a robust framework for making informed conclusions.
What are the Limitations of Hypothesis Testing?
Hypothesis testing relies exclusively on data and doesn’t provide a comprehensive understanding of the subject being studied. Additionally, the accuracy of the results depends on the quality of the available data and the statistical methods used. Inaccurate data or inappropriate hypothesis formulation may lead to incorrect conclusions or failed tests. Hypothesis testing can also lead to errors, such as analysts either accepting or rejecting a null hypothesis when they shouldn’t have. These errors may result in false conclusions or missed opportunities to identify significant patterns or relationships in the data.
Hypothesis testing refers to a statistical process that helps researchers determine the reliability of a study. By using a well-formulated hypothesis and set of statistical tests, individuals or businesses can make inferences about the population that they are studying and draw conclusions based on the data presented. All hypothesis testing methods have the same four-step process, which includes stating the hypotheses, formulating an analysis plan, analyzing the sample data, and analyzing the result.
Sage. " Introduction to Hypothesis Testing ," Page 4.
Elder Research. " Who Invented the Null Hypothesis? "
Formplus. " Hypothesis Testing: Definition, Uses, Limitations and Examples ."
:max_bytes(150000):strip_icc():format(webp)/null_hypothesis-finalE-56a4132b022f49f0a3d469c6882ddd99.jpg "5 steps procedure for hypothesis testing")
- Terms of Service
- Editorial Policy
- Privacy Policy
- Data Science
- Data Analysis
- Data Visualization
- Machine Learning
- Deep Learning
- Computer Vision
- Artificial Intelligence
- AI ML DS Interview Series
- AI ML DS Projects series
- Data Engineering
- Web Scrapping
Understanding Hypothesis Testing
Hypothesis testing involves formulating assumptions about population parameters based on sample statistics and rigorously evaluating these assumptions against empirical evidence. This article sheds light on the significance of hypothesis testing and the critical steps involved in the process.
What is Hypothesis Testing?
A hypothesis is an assumption or idea, specifically a statistical claim about an unknown population parameter. For example, a judge assumes a person is innocent and verifies this by reviewing evidence and hearing testimony before reaching a verdict.
Hypothesis testing is a statistical method that is used to make a statistical decision using experimental data. Hypothesis testing is basically an assumption that we make about a population parameter. It evaluates two mutually exclusive statements about a population to determine which statement is best supported by the sample data.
To test the validity of the claim or assumption about the population parameter:
- A sample is drawn from the population and analyzed.
- The results of the analysis are used to decide whether the claim is true or not.
Example: You say an average height in the class is 30 or a boy is taller than a girl. All of these is an assumption that we are assuming, and we need some statistical way to prove these. We need some mathematical conclusion whatever we are assuming is true.
Defining Hypotheses
- Null hypothesis (H 0 ): In statistics, the null hypothesis is a general statement or default position that there is no relationship between two measured cases or no relationship among groups. In other words, it is a basic assumption or made based on the problem knowledge. Example : A company’s mean production is 50 units/per da H 0 : [Tex]\mu [/Tex] = 50.
- Alternative hypothesis (H 1 ): The alternative hypothesis is the hypothesis used in hypothesis testing that is contrary to the null hypothesis. Example: A company’s production is not equal to 50 units/per day i.e. H 1 : [Tex]\mu [/Tex] [Tex]\ne [/Tex] 50.
Key Terms of Hypothesis Testing
- Level of significance : It refers to the degree of significance in which we accept or reject the null hypothesis. 100% accuracy is not possible for accepting a hypothesis, so we, therefore, select a level of significance that is usually 5%. This is normally denoted with [Tex]\alpha[/Tex] and generally, it is 0.05 or 5%, which means your output should be 95% confident to give a similar kind of result in each sample.
- P-value: The P value , or calculated probability, is the probability of finding the observed/extreme results when the null hypothesis(H0) of a study-given problem is true. If your P-value is less than the chosen significance level then you reject the null hypothesis i.e. accept that your sample claims to support the alternative hypothesis.
- Test Statistic: The test statistic is a numerical value calculated from sample data during a hypothesis test, used to determine whether to reject the null hypothesis. It is compared to a critical value or p-value to make decisions about the statistical significance of the observed results.
- Critical value : The critical value in statistics is a threshold or cutoff point used to determine whether to reject the null hypothesis in a hypothesis test.
- Degrees of freedom: Degrees of freedom are associated with the variability or freedom one has in estimating a parameter. The degrees of freedom are related to the sample size and determine the shape.
Why do we use Hypothesis Testing?
Hypothesis testing is an important procedure in statistics. Hypothesis testing evaluates two mutually exclusive population statements to determine which statement is most supported by sample data. When we say that the findings are statistically significant, thanks to hypothesis testing.
One-Tailed and Two-Tailed Test
One tailed test focuses on one direction, either greater than or less than a specified value. We use a one-tailed test when there is a clear directional expectation based on prior knowledge or theory. The critical region is located on only one side of the distribution curve. If the sample falls into this critical region, the null hypothesis is rejected in favor of the alternative hypothesis.
One-Tailed Test
There are two types of one-tailed test:
- Left-Tailed (Left-Sided) Test: The alternative hypothesis asserts that the true parameter value is less than the null hypothesis. Example: H 0 : [Tex]\mu \geq 50 [/Tex] and H 1 : [Tex]\mu < 50 [/Tex]
- Right-Tailed (Right-Sided) Test : The alternative hypothesis asserts that the true parameter value is greater than the null hypothesis. Example: H 0 : [Tex]\mu \leq50 [/Tex] and H 1 : [Tex]\mu > 50 [/Tex]
Two-Tailed Test
A two-tailed test considers both directions, greater than and less than a specified value.We use a two-tailed test when there is no specific directional expectation, and want to detect any significant difference.
Example: H 0 : [Tex]\mu = [/Tex] 50 and H 1 : [Tex]\mu \neq 50 [/Tex]
To delve deeper into differences into both types of test: Refer to link
What are Type 1 and Type 2 errors in Hypothesis Testing?
In hypothesis testing, Type I and Type II errors are two possible errors that researchers can make when drawing conclusions about a population based on a sample of data. These errors are associated with the decisions made regarding the null hypothesis and the alternative hypothesis.
- Type I error: When we reject the null hypothesis, although that hypothesis was true. Type I error is denoted by alpha( [Tex]\alpha [/Tex] ).
- Type II errors : When we accept the null hypothesis, but it is false. Type II errors are denoted by beta( [Tex]\beta [/Tex] ).
Null Hypothesis is True | Null Hypothesis is False | |
|---|---|---|
Null Hypothesis is True (Accept) | Correct Decision | Type II Error (False Negative) |
Alternative Hypothesis is True (Reject) | Type I Error (False Positive) | Correct Decision |
How does Hypothesis Testing work?
Step 1: define null and alternative hypothesis.
State the null hypothesis ( [Tex]H_0 [/Tex] ), representing no effect, and the alternative hypothesis ( [Tex]H_1 [/Tex] ), suggesting an effect or difference.
We first identify the problem about which we want to make an assumption keeping in mind that our assumption should be contradictory to one another, assuming Normally distributed data.
Step 2 – Choose significance level
Select a significance level ( [Tex]\alpha [/Tex] ), typically 0.05, to determine the threshold for rejecting the null hypothesis. It provides validity to our hypothesis test, ensuring that we have sufficient data to back up our claims. Usually, we determine our significance level beforehand of the test. The p-value is the criterion used to calculate our significance value.
Step 3 – Collect and Analyze data.
Gather relevant data through observation or experimentation. Analyze the data using appropriate statistical methods to obtain a test statistic.
Step 4-Calculate Test Statistic
The data for the tests are evaluated in this step we look for various scores based on the characteristics of data. The choice of the test statistic depends on the type of hypothesis test being conducted.
There are various hypothesis tests, each appropriate for various goal to calculate our test. This could be a Z-test , Chi-square , T-test , and so on.
- Z-test : If population means and standard deviations are known. Z-statistic is commonly used.
- t-test : If population standard deviations are unknown. and sample size is small than t-test statistic is more appropriate.
- Chi-square test : Chi-square test is used for categorical data or for testing independence in contingency tables
- F-test : F-test is often used in analysis of variance (ANOVA) to compare variances or test the equality of means across multiple groups.
We have a smaller dataset, So, T-test is more appropriate to test our hypothesis.
T-statistic is a measure of the difference between the means of two groups relative to the variability within each group. It is calculated as the difference between the sample means divided by the standard error of the difference. It is also known as the t-value or t-score.
Step 5 – Comparing Test Statistic:
In this stage, we decide where we should accept the null hypothesis or reject the null hypothesis. There are two ways to decide where we should accept or reject the null hypothesis.
Method A: Using Crtical values
Comparing the test statistic and tabulated critical value we have,
- If Test Statistic>Critical Value: Reject the null hypothesis.
- If Test Statistic≤Critical Value: Fail to reject the null hypothesis.
Note: Critical values are predetermined threshold values that are used to make a decision in hypothesis testing. To determine critical values for hypothesis testing, we typically refer to a statistical distribution table , such as the normal distribution or t-distribution tables based on.
Method B: Using P-values
We can also come to an conclusion using the p-value,
- If the p-value is less than or equal to the significance level i.e. ( [Tex]p\leq\alpha [/Tex] ), you reject the null hypothesis. This indicates that the observed results are unlikely to have occurred by chance alone, providing evidence in favor of the alternative hypothesis.
- If the p-value is greater than the significance level i.e. ( [Tex]p\geq \alpha[/Tex] ), you fail to reject the null hypothesis. This suggests that the observed results are consistent with what would be expected under the null hypothesis.
Note : The p-value is the probability of obtaining a test statistic as extreme as, or more extreme than, the one observed in the sample, assuming the null hypothesis is true. To determine p-value for hypothesis testing, we typically refer to a statistical distribution table , such as the normal distribution or t-distribution tables based on.
Step 7- Interpret the Results
At last, we can conclude our experiment using method A or B.
Calculating test statistic
To validate our hypothesis about a population parameter we use statistical functions . We use the z-score, p-value, and level of significance(alpha) to make evidence for our hypothesis for normally distributed data .
1. Z-statistics:
When population means and standard deviations are known.
[Tex]z = \frac{\bar{x} – \mu}{\frac{\sigma}{\sqrt{n}}}[/Tex]
- [Tex]\bar{x} [/Tex] is the sample mean,
- μ represents the population mean,
- σ is the standard deviation
- and n is the size of the sample.
2. T-Statistics
T test is used when n<30,
t-statistic calculation is given by:
[Tex]t=\frac{x̄-μ}{s/\sqrt{n}} [/Tex]
- t = t-score,
- x̄ = sample mean
- μ = population mean,
- s = standard deviation of the sample,
- n = sample size
3. Chi-Square Test
Chi-Square Test for Independence categorical Data (Non-normally distributed) using:
[Tex]\chi^2 = \sum \frac{(O_{ij} – E_{ij})^2}{E_{ij}}[/Tex]
- [Tex]O_{ij}[/Tex] is the observed frequency in cell [Tex]{ij} [/Tex]
- i,j are the rows and columns index respectively.
- [Tex]E_{ij}[/Tex] is the expected frequency in cell [Tex]{ij}[/Tex] , calculated as : [Tex]\frac{{\text{{Row total}} \times \text{{Column total}}}}{{\text{{Total observations}}}}[/Tex]
Real life Examples of Hypothesis Testing
Let’s examine hypothesis testing using two real life situations,
Case A: D oes a New Drug Affect Blood Pressure?
Imagine a pharmaceutical company has developed a new drug that they believe can effectively lower blood pressure in patients with hypertension. Before bringing the drug to market, they need to conduct a study to assess its impact on blood pressure.
- Before Treatment: 120, 122, 118, 130, 125, 128, 115, 121, 123, 119
- After Treatment: 115, 120, 112, 128, 122, 125, 110, 117, 119, 114
Step 1 : Define the Hypothesis
- Null Hypothesis : (H 0 )The new drug has no effect on blood pressure.
- Alternate Hypothesis : (H 1 )The new drug has an effect on blood pressure.
Step 2: Define the Significance level
Let’s consider the Significance level at 0.05, indicating rejection of the null hypothesis.
If the evidence suggests less than a 5% chance of observing the results due to random variation.
Step 3 : Compute the test statistic
Using paired T-test analyze the data to obtain a test statistic and a p-value.
The test statistic (e.g., T-statistic) is calculated based on the differences between blood pressure measurements before and after treatment.
t = m/(s/√n)
- m = mean of the difference i.e X after, X before
- s = standard deviation of the difference (d) i.e d i = X after, i − X before,
- n = sample size,
then, m= -3.9, s= 1.8 and n= 10
we, calculate the , T-statistic = -9 based on the formula for paired t test
Step 4: Find the p-value
The calculated t-statistic is -9 and degrees of freedom df = 9, you can find the p-value using statistical software or a t-distribution table.
thus, p-value = 8.538051223166285e-06
Step 5: Result
- If the p-value is less than or equal to 0.05, the researchers reject the null hypothesis.
- If the p-value is greater than 0.05, they fail to reject the null hypothesis.
Conclusion: Since the p-value (8.538051223166285e-06) is less than the significance level (0.05), the researchers reject the null hypothesis. There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different.
Python Implementation of Case A
Let’s create hypothesis testing with python, where we are testing whether a new drug affects blood pressure. For this example, we will use a paired T-test. We’ll use the scipy.stats library for the T-test.
Scipy is a mathematical library in Python that is mostly used for mathematical equations and computations.
We will implement our first real life problem via python,
import numpy as np from scipy import stats # Data before_treatment = np . array ([ 120 , 122 , 118 , 130 , 125 , 128 , 115 , 121 , 123 , 119 ]) after_treatment = np . array ([ 115 , 120 , 112 , 128 , 122 , 125 , 110 , 117 , 119 , 114 ]) # Step 1: Null and Alternate Hypotheses # Null Hypothesis: The new drug has no effect on blood pressure. # Alternate Hypothesis: The new drug has an effect on blood pressure. null_hypothesis = "The new drug has no effect on blood pressure." alternate_hypothesis = "The new drug has an effect on blood pressure." # Step 2: Significance Level alpha = 0.05 # Step 3: Paired T-test t_statistic , p_value = stats . ttest_rel ( after_treatment , before_treatment ) # Step 4: Calculate T-statistic manually m = np . mean ( after_treatment - before_treatment ) s = np . std ( after_treatment - before_treatment , ddof = 1 ) # using ddof=1 for sample standard deviation n = len ( before_treatment ) t_statistic_manual = m / ( s / np . sqrt ( n )) # Step 5: Decision if p_value <= alpha : decision = "Reject" else : decision = "Fail to reject" # Conclusion if decision == "Reject" : conclusion = "There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different." else : conclusion = "There is insufficient evidence to claim a significant difference in average blood pressure before and after treatment with the new drug." # Display results print ( "T-statistic (from scipy):" , t_statistic ) print ( "P-value (from scipy):" , p_value ) print ( "T-statistic (calculated manually):" , t_statistic_manual ) print ( f "Decision: { decision } the null hypothesis at alpha= { alpha } ." ) print ( "Conclusion:" , conclusion )
T-statistic (from scipy): -9.0 P-value (from scipy): 8.538051223166285e-06 T-statistic (calculated manually): -9.0 Decision: Reject the null hypothesis at alpha=0.05. Conclusion: There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different.
In the above example, given the T-statistic of approximately -9 and an extremely small p-value, the results indicate a strong case to reject the null hypothesis at a significance level of 0.05.
- The results suggest that the new drug, treatment, or intervention has a significant effect on lowering blood pressure.
- The negative T-statistic indicates that the mean blood pressure after treatment is significantly lower than the assumed population mean before treatment.
Case B : Cholesterol level in a population
Data: A sample of 25 individuals is taken, and their cholesterol levels are measured.
Cholesterol Levels (mg/dL): 205, 198, 210, 190, 215, 205, 200, 192, 198, 205, 198, 202, 208, 200, 205, 198, 205, 210, 192, 205, 198, 205, 210, 192, 205.
Populations Mean = 200
Population Standard Deviation (σ): 5 mg/dL(given for this problem)
Step 1: Define the Hypothesis
- Null Hypothesis (H 0 ): The average cholesterol level in a population is 200 mg/dL.
- Alternate Hypothesis (H 1 ): The average cholesterol level in a population is different from 200 mg/dL.
As the direction of deviation is not given , we assume a two-tailed test, and based on a normal distribution table, the critical values for a significance level of 0.05 (two-tailed) can be calculated through the z-table and are approximately -1.96 and 1.96.
The test statistic is calculated by using the z formula Z = [Tex](203.8 – 200) / (5 \div \sqrt{25}) [/Tex] and we get accordingly , Z =2.039999999999992.
Step 4: Result
Since the absolute value of the test statistic (2.04) is greater than the critical value (1.96), we reject the null hypothesis. And conclude that, there is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL
Python Implementation of Case B
import scipy.stats as stats import math import numpy as np # Given data sample_data = np . array ( [ 205 , 198 , 210 , 190 , 215 , 205 , 200 , 192 , 198 , 205 , 198 , 202 , 208 , 200 , 205 , 198 , 205 , 210 , 192 , 205 , 198 , 205 , 210 , 192 , 205 ]) population_std_dev = 5 population_mean = 200 sample_size = len ( sample_data ) # Step 1: Define the Hypotheses # Null Hypothesis (H0): The average cholesterol level in a population is 200 mg/dL. # Alternate Hypothesis (H1): The average cholesterol level in a population is different from 200 mg/dL. # Step 2: Define the Significance Level alpha = 0.05 # Two-tailed test # Critical values for a significance level of 0.05 (two-tailed) critical_value_left = stats . norm . ppf ( alpha / 2 ) critical_value_right = - critical_value_left # Step 3: Compute the test statistic sample_mean = sample_data . mean () z_score = ( sample_mean - population_mean ) / \ ( population_std_dev / math . sqrt ( sample_size )) # Step 4: Result # Check if the absolute value of the test statistic is greater than the critical values if abs ( z_score ) > max ( abs ( critical_value_left ), abs ( critical_value_right )): print ( "Reject the null hypothesis." ) print ( "There is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL." ) else : print ( "Fail to reject the null hypothesis." ) print ( "There is not enough evidence to conclude that the average cholesterol level in the population is different from 200 mg/dL." )
Reject the null hypothesis. There is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL.
Limitations of Hypothesis Testing
- Although a useful technique, hypothesis testing does not offer a comprehensive grasp of the topic being studied. Without fully reflecting the intricacy or whole context of the phenomena, it concentrates on certain hypotheses and statistical significance.
- The accuracy of hypothesis testing results is contingent on the quality of available data and the appropriateness of statistical methods used. Inaccurate data or poorly formulated hypotheses can lead to incorrect conclusions.
- Relying solely on hypothesis testing may cause analysts to overlook significant patterns or relationships in the data that are not captured by the specific hypotheses being tested. This limitation underscores the importance of complimenting hypothesis testing with other analytical approaches.
Hypothesis testing stands as a cornerstone in statistical analysis, enabling data scientists to navigate uncertainties and draw credible inferences from sample data. By systematically defining null and alternative hypotheses, choosing significance levels, and leveraging statistical tests, researchers can assess the validity of their assumptions. The article also elucidates the critical distinction between Type I and Type II errors, providing a comprehensive understanding of the nuanced decision-making process inherent in hypothesis testing. The real-life example of testing a new drug’s effect on blood pressure using a paired T-test showcases the practical application of these principles, underscoring the importance of statistical rigor in data-driven decision-making.
Frequently Asked Questions (FAQs)
1. what are the 3 types of hypothesis test.
There are three types of hypothesis tests: right-tailed, left-tailed, and two-tailed. Right-tailed tests assess if a parameter is greater, left-tailed if lesser. Two-tailed tests check for non-directional differences, greater or lesser.
2.What are the 4 components of hypothesis testing?
Null Hypothesis ( [Tex]H_o [/Tex] ): No effect or difference exists. Alternative Hypothesis ( [Tex]H_1 [/Tex] ): An effect or difference exists. Significance Level ( [Tex]\alpha [/Tex] ): Risk of rejecting null hypothesis when it’s true (Type I error). Test Statistic: Numerical value representing observed evidence against null hypothesis.
3.What is hypothesis testing in ML?
Statistical method to evaluate the performance and validity of machine learning models. Tests specific hypotheses about model behavior, like whether features influence predictions or if a model generalizes well to unseen data.
4.What is the difference between Pytest and hypothesis in Python?
Pytest purposes general testing framework for Python code while Hypothesis is a Property-based testing framework for Python, focusing on generating test cases based on specified properties of the code.
Please Login to comment...
Similar reads.
- data-science
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
- Anatomy & Physiology
- Astrophysics
- Earth Science
- Environmental Science
- Organic Chemistry
- Precalculus
- Trigonometry
- English Grammar
- U.S. History
- World History
... and beyond
- Socratic Meta
- Featured Answers

What is the five-step process for hypothesis testing?

Free Al Office Suite with PDF Editor
Edit Word, Excel, and PPT for FREE.
Read, edit, and convert PDFs with the powerful PDF toolkit.
Microsoft-like interface, easy to use.
Windows • MacOS • Linux • iOS • Android

- Articles of Word
How to Write a Hypothesis? [Tips with Examples]
Click here if you have ever found yourself in the position of having to wrestle with the development of a hypothesis for your research paper. As an expert writer, I have seen that this is where most students begin to sweat. It is a potpourri of theory and practice, hence rather intimidating. But not to worry because I have got your back. This guide is a pool of tips and tricks for writing a hypothesis to set the stage for compelling research.
What is a Hypothesis?
A hypothesis is a tentative statement, usually in the form of an educated guess, that provides a probable explanation for something either a phenomenon or a relationship between variables. This will, therefore, form a basis for conducting experiments and research studies, hence laying down the course of your investigation and mainly laying the ground for your conclusion.
A good hypothesis should be:
Specific and clear
Testable and falsifiable
Based upon existing knowledge
Logically consistent
Types of Hypothesis
There are different kinds of hypotheses used in research, all of which serve different purposes depending on the nature of the study. Here are eight common types:
1. The null hypothesis (H0): asserts that there is no effect or relationship between variables. This forms a baseline for comparison. Example: "There is no difference in test scores for students who study music and for those who do not."
2. Alternative Hypothesis (H1): The hypothesis that postulates some effect or relationship between variables; it is, therefore, the opposite of the null hypothesis. For instance, "Students who study with music have different test scores than those who study in silence."
3. Simple Hypothesis: The hypothesis that states a relationship between two variables: one independent and one dependent. For example, "More sunlight increases plant growth."
4. Complex Hypothesis: This hypothesis involves the relationship of more than one variable. For example, "More sunlight and water increase plant growth."
5. Directional Hypothesis: The hypothesis which specifies the direction of the effect between variables. For instance, "Students who study with music will have higher test scores than students who study in silence."
6. Non-Directional Hypothesis: This is a hypothesis used where the relationship is indicated, but the direction is not specified. For example, "There is a difference in test scores between students who study with music and those who study in silence."
7. Associative Hypothesis: This hypothesis merely states that the change in one variable is associated with a change in another. It does not indicate cause and effect. For example: "There is a relationship between study habits and academic performance."
8. Causal Hypothesis: This hypothesis states that one variable causes a change in another. For example: "Increased study time results in higher test scores."
Understanding such types of hypotheses will help in the selection of the correct hypothesis for your research and in making your analysis clear and effective.
5 Steps to Write a Good Hypothesis [With Examples]
An excellent hypothesis provides a backbone to any scientific research. Leave some help behind in writing one? Follow this easy guide:
Step 1: Ask a Question
First, you must understand what your research question is. Suppose you want to carry out an experiment on plant growth. Your question can be, "How does sunlight affect plant growth?"
Use WPS AI to help when you get stuck. Feed it a topic, and it will come up with related questions to ask.
Step 2: Do Preliminary Research
Do some research to see what's already known about your topic. That way, you can build upon existing knowledge.
Research information in journals, books and credible websites. Then summarize what you read. This will help you formulate your hypothesis.
Step 3: Define Variables
Identify your variables:
Independent Variable: What you manipulate. For example, the amount of sun.
Dependent Variable: What you measure. For example, plant growth rate.
Clearly defining these makes your hypothesis specific and testable.
Step 4: State Your Hypothesis
State your question in the form of a hypothesis. Here are some examples:
If then: "If plants receive more sunlight, then they will grow faster."
Comparative statements: "Plants receiving more sunlight grow faster than plants receiving less."
Correlation statements: "There is positive correlation between sunlight and plant growth." This kind of pattern makes your hypothesis easy to test.
Step 5: Refine Your Hypothesis
Revise your hypothesis to be clear and specific, and elicit feedback to improve it.
You will also need a null hypothesis, which says that there is no effect or relationship between variables. An example would be, "Sunlight has no effect on the growth of plants."
With these steps, you are now bound to come up with a testable hypothesis. WPS AI can help you in this process more efficiently.
Characteristics of a Good Hypothesis
A good hypothesis is seen as the backbone of doing effective research. Following are some key characteristics that define a good hypothesis:
A good hypothesis has to be testable either by experimentation or observation. The hypothesis should clearly predict what can be measured or observed. For example, "If it receives more sunlight, the plant will grow taller" is a testable hypothesis since it states what can be measured.
Falsifiable
A hypothesis has to be falsifiable: it should be able to prove it wrong. This feature is important because it accommodates testing in science. For example, the statement "All swans are white" is falsifiable since it just takes one black swan to disprove the claim.
A good hypothesis should be grounded in current knowledge and should be properly reasoned. It should be broad or reasonable within existing knowledge. For example, "Increasing the amount of sunlight will boost plant growth" makes sense, in that it tallies with generally known facts about photosynthesis.
Specific and Clear
What is needed is clarity and specificity. A hypothesis has to be brief, yet free from ambiguity. For instance, "Increased sunlight leads to taller plants" is clear and specific whereas "Sunlight affects plants" is too vague.
Built upon Prior Knowledge
A good hypothesis is informed by prior research and existing theories. The available knowledge enlightens it to build on what is known to find new relationships or effects. For example, "Given photosynthesis requires sunlight, increasing sunlight will enhance plant growth" is informed by available scientific understanding.
Ethical Considerations
Finally, a good hypothesis needs to consider the ethics involved. The research should not bring damage to participants or the environment. For instance, "How the new drug will affect a human when tested without testing it on animals" may present an ethical concern.
Checklist for Reviewing Your Hypothesis
To be certain that your hypothesis has the following characteristics, use this checklist to review your hypothesis:
1. Is the hypothesis testable through experimentation or observation?
2. Can the hypothesis be proven false?
3. Is the hypothesis logically deduced from known facts?
4. Is your hypothesis clear and specific?
5. Does your hypothesis relate to previous research or theories?
6. Will there be any ethical issues with the proposed research?
7. Are your independent and dependent variables well defined?
8. Is your hypothesis concise and ambiguity free?
9. Did you get feedback to help in refining your hypothesis?
10. Does your hypothesis contain a null hypothesis for comparison?
By making sure that your hypothesis has these qualities, you are much more likely to set yourself on the course of higher-quality research and larger impacts. WPS AI can help fine-tune a hypothesis to ensure it is well-structured and clear.
Using WPS to Perfect your Hypothesis
Drafting a good hypothesis is the real inception of any research project. WPS AI, with its advanced language functions, can very strongly improve this stage of your study. Here's how WPS AI can help you perfect your hypothesis:
Check Grammar and Syntax
Grammar and punctuation errors can make your hypothesis weak. WPS AI checks and corrects this with the assurance that your hypothesis is as clear as possible and professional in its presentation. For example, when your hypothesis is written, "If the temperature increases then plant growth will increases", WPS AI can correct it to "If the temperature increases, then plant growth will increase."
Rewrite Your Hypothesis for Clarity
There needs to be a clear hypothesis. WPS AI can suggest ways to reword your hypothesis so that it makes sense. If your original hypothesis is, "More sunlight will result in more significant plant growth due to photosynthesis," WPS AI can suggest, "Increased sunlight will lead to greater plant growth through enhanced photosynthesis."
Automatic Content Expansion
Sometimes, your hypothesis or the related paragraphs may require more detail. WPS AI's [Continue Writing] feature can help enlarge the content. For example, after having written, "This study will examine the effects of sunlight on plant growth", using [Continue Writing] it can enlarge it to, "This research paper is going to study how sunlight affects the growth of plants by measuring their height and their health under different amounts of sunlight over a period of six weeks."
WPS AI is a great tool that can help you in drafting a good hypothesis for your research. It will help you check grammar, syntax, clarity, and completeness. Using WPS AI , you will be assured that the results of your hypothesis will be well-written and clear to understand.
What is the difference between a hypothesis and a theory?
The hypothesis is one single testable prediction regarding some phenomenon. The theory is an explanation for some part of the natural world which is well-substantiated by a body of evidence, together with multiple hypotheses.
What do I do if my hypothesis isn't supported by my data?
If your results turn out not to support your hypothesis, analyze the data again to see why your result rejects your hypothesis. Do not manipulate the observations or experiment so that it leads to your hypothesis.
Can there be more than one hypothesis in a research study?
Yes, there may be more than one hypothesis, especially when one research study is examining several interrelated phenomena or variables. Each hypothesis has to be separately and clearly stated and tested.
Correct formulation of a strong, testable hypothesis is one of the most critical steps in the application of the scientific method and within academic research. The steps provided in this article will help you write a hypothesis that is clear, specific, and based on available knowledge. Give the tools and tips a try to elevate your academic writing and kick your research up a notch.
- 1. How to Write a Book Review [Tips with Examples]
- 2. How to Write a Call to Action - Steps with Examples
- 3. How to Write a Cover Letter [Tips with Examples]
- 4. How to Write a Bibliography [Tips with Examples]
- 5. How to Write a Cover Letter for Teaching Positions [Tips with Examples]
- 6. How to Write Modern Resume Examples Free 2022

15 years of office industry experience, tech lover and copywriter. Follow me for product reviews, comparisons, and recommendations for new apps and software.
New Decision Rules for Fuzzy Statistical Inferences
- Conference paper
- First Online: 10 August 2024
- Cite this conference paper

- Julien Rosset 21 &
- Laurent Donzé 21
Part of the book series: Advances in Intelligent Systems and Computing ((AISC,volume 1458))
Included in the following conference series:
- International Conference on Soft Methods in Probability and Statistics
17 Accesses
We profit from the concept of the fuzzy confidence interval to implement two decision rules based on two new measures called levels of acceptance and rejection, to perform fuzzy hypothesis testing. The procedure can make a decision when both the data and hypotheses are fuzzy. Through a numerical application, we illustrate our proposed method. We compare the levels of acceptance and rejection of different fuzzy null hypotheses at a 5% significant level for a confidence interval at a 95% confidence level.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Berkachy, R.: The Signed Distance Measure in Fuzzy Statistical Analysis. Some theoretical, empirical and programming advances. PhD thesis University of Fribourg (2020). https://folia.unifr.ch/unifr/documents/308986
Berkachy, R., Donzé, L.: Testing fuzzy hypotheses with fuzzy data and defuzzification of the fuzzy p-value by the signed distance method. In: Proceedings of the 9th International Joint Conference on Computational Intelligence, pp. 255–264 (2017). https://doi.org/10.5220/0006500602550264
Berkachy, R., Donzé, L.: Fuzzy confidence interval estimation by likelihood ratio. In: Proceedings of the 11th Conference of the European Society for Fuzzy Logic and Technology (EUSFLAT 2019). Atlantis Studies in Uncertainty Modelling Vol. 1., pp. 150–157. Atlantis Press (2019a). https://doi.org/10.2991/eusflat-19.2019.23
Berkachy, R., Donzé, L.: Testing hypotheses by fuzzy methods: a comparison with the classical approach. In: Meier, A., Portmann, E., Terán, L. (Eds.) Applying Fuzzy Logic for the Digital Economy and Society, pp. 1–22. Fuzzy Management Methods. Springer, Cham (2019b). https://doi.org/10.1007/978-3-030-03368-2_1
Berkachy, R., Donzé, L.: Fuzzy Confidence Intervals by the Likelihood Ratio with Bootstrapped Distribution. In: Proceedings of the 12th International Joint Conference on Computational Intelligence (IJCCI 2020) - Volume 1, , pp. 231–242. SciTePress (2020). https://doi.org/10.5220/0010023602310242
Chachi, J., Taheri, S.: Fuzzy confidence intervals for mean of Gaussian fuzzy random variables. Expert Syst. Appl. 38(5), 5240–5244 (2011). https://doi.org/10.1016/j.eswa.2010.10.034
Kahraman, C., Oztaysi, B., Onar, S.C. Interval-Valued Intuitionistic Fuzzy Confidence Intervals. J. Intell. Syst. 28 (2), 307–319 (2019). https://doi.org/10.1515/jisys-2017-0139
Kruse, R., Meyer, K.D.: Statistics with Vague Data. Theory and Decision Library, Series B: Mathematical and Statistical Methods. D. Reidel Publishing Company (1987). https://doi.org/10.1007/978-94-009-3943-1
Rosset, J., Donzé, L.: Fuzzy least squares and fuzzy orthogonal least squares linear regressions. In: Proceedings of the 15th International Joint Conference on Computational Intelligence - FCTA, pp. 359–368. SciTePress (2023). https://doi.org/10.5220/0012182700003595
Rosset, J., Donzé, L.: Fuzzy confidence intervals by bootstrapped fuzzy distributions. In: Proceedings of the 20th International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems (IPMU 2024, Lisboa, July 22–26, 2024) (2024)
Google Scholar
Viertl, R.: Statistical Methods for Fuzzy Data. John Wiley & Sons (2011). https://doi.org/10.1002/9780470974414
Download references
Author information
Authors and affiliations.
Department of Informatics, University of Fribourg, ASAM Group, Fribourg, Switzerland
Julien Rosset & Laurent Donzé
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Julien Rosset .
Editor information
Editors and affiliations.
Department of Artificial Intelligence and Human Interfaces, Paris Lodron Universität Salzburg, Salzburg, Austria
Jonathan Ansari
Sebastian Fuchs
Department of Artificial Intelligence and Human Interfaces,, Paris Lodron Universität Salzburg, Salzburg, Austria
Wolfgang Trutschnig
Department of Statistics and Operational Research and Mathematics Didactics, University of Oviedo, Oviedo, Spain
María Asunción Lubiano
María Ángeles Gil
Faculty of Mathematics and Information Science, Warsaw University of Technology, Warsaw, Poland
Przemyslaw Grzegorzewski
Systems Research Institute, Polish Academy of Sciences, Warsaw, Poland
Olgierd Hryniewicz
Rights and permissions
Reprints and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper
Cite this paper.
Rosset, J., Donzé, L. (2024). New Decision Rules for Fuzzy Statistical Inferences. In: Ansari, J., et al. Combining, Modelling and Analyzing Imprecision, Randomness and Dependence. SMPS 2024. Advances in Intelligent Systems and Computing, vol 1458. Springer, Cham. https://doi.org/10.1007/978-3-031-65993-5_50
Download citation
DOI : https://doi.org/10.1007/978-3-031-65993-5_50
Published : 10 August 2024
Publisher Name : Springer, Cham
Print ISBN : 978-3-031-65992-8
Online ISBN : 978-3-031-65993-5
eBook Packages : Intelligent Technologies and Robotics Intelligent Technologies and Robotics (R0)
Share this paper
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
IMAGES
COMMENTS
Hypothesis Testing | A Step-by-Step Guide with Easy Examples Published on November 8, 2019 by Rebecca Bevans . Revised on June 22, 2023. Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is most often used by scientists to test specific predictions, called hypotheses, that arise from theories.
11.2.1 - Five Step Hypothesis Testing Procedure The examples on the following pages use the five step hypothesis testing procedure outlined below. This is the same procedure that we used to conduct a hypothesis test for a single mean, single proportion, difference in two means, and difference in two proportions.
Below these are summarized into six such steps to conducting a test of a hypothesis. Set up the hypotheses and check conditions: Each hypothesis test includes two hypotheses about the population. One is the null hypothesis, notated as H 0, which is a statement of a particular parameter value.
Step 7: Based on steps 5 and 6, draw a conclusion about H0. If the F\calculated from the data is larger than the Fα, then you are in the rejection region and you can reject the null hypothesis with (1 − α) level of confidence. Note that modern statistical software condenses steps 6 and 7 by providing a p -value.
5 Steps of Significance Testing. Hypothesis testing involves five key steps, each critical to validating a research hypothesis using statistical methods: Formulate the Hypotheses: Write your research hypotheses as a null hypothesis (H 0) and an alternative hypothesis (H A ). Data Collection: Gather data specifically aimed at testing the ...
The examples on the following pages use the five step hypothesis testing procedure outlined below. This is the same procedure that we used to conduct a hypothesis test for a single mean, single proportion, difference in two means, and difference in two proportions. Step 1: Check assumptions and write hypotheses
To perform a hypothesis test, a statistician will: Set up two contradictory hypotheses. Collect sample data (in homework problems, the data or summary statistics will be given to you). Determine the correct distribution to perform the hypothesis test. Analyze sample data by performing the calculations that ultimately will allow you to reject or ...
The process of testing hypotheses follows a simple four-step procedure. This process will be what we use for the remainder of the textbook and course, and though the hypothesis and statistics we use will change, this process will not. Step 1: State the Hypotheses. Your hypotheses are the first thing you need to lay out.
Hypothesis Testing Steps The formal framework and steps for hypothesis testing are as follows: Identify and define the parameter of interest Define the competing hypotheses to test Set the evidence threshold, formally called the significance level Generate or use theory to specify the sampling distribution and check conditions Calculate the test statistic and p-value Evaluate your results and ...
The Process of Hypothesis Testing Hypothesis testing is a systematic process involving several key steps. By following these steps, researchers can make informed decisions based on statistical ...
Understand the structure of hypothesis testing and how to understand and make a research, null and alterative hypothesis for your statistical tests.
When we know the mean and standard deviation in a single population, we can use the one-independent sample z test, which we will use in this section to illustrate the four steps of hypothesis testing.
STEPS IN HYPOTHESIS TESTING. Step 1: State the Hypotheses. Null Hypothesis (H0) in the general population there is no change, no difference, or no relationship; the independent variable will have no effect on the dependent variable. Example.
Typical values are 0.05 0.05 and 0.01 0.01. The third step is to compute the probability value (also known as the p p value). This is the probability of obtaining a sample statistic as different or more different from the parameter specified in the null hypothesis given that the null hypothesis is true.
5 Basic Steps in Any Hypothesis Test. Step 1: Determine. hypotheses (H0 and Ha). Ha: μd > 0 (μ1 -μ2>0) Ha: : μd ≠ 0 (μ1 -μ2≠0) Ha: μd <0 (μ1 -μ2<0) upper-sided two-sided lower-sided. Step 2: Verify necessary conditions, compute an appropriate test statistic. Step 3: Assuming H0 is true, find Decision Rule Step 4: Decide ...
Hypothesis testing is the step-by-step process of analyzing empirical data to check if it differs from the expected numbers if the belief or theory you started with was true. This article walks you through the hypothesis testing concept and lists the process of hypothesis testing step by step.
Below these are summarized into six such steps to conducting a test of a hypothesis. Set up the hypotheses and check conditions: Each hypothesis test includes two hypotheses about the population. One is the null hypothesis, notated as \ (H_0 \), which is a statement of a particular parameter value. This hypothesis is assumed to be true until ...
I would like to make the process of understanding hypothesis testing much simpler for students need help learning statistics. Hypothesis testing is a five-step procedure. Let's address the difficulties of students while they learn the … The 5 Easy Steps to Hypothesis Testing Read More »
Hypothesis testing is an act in statistics whereby an analyst tests an assumption regarding a population parameter. The methodology employed by the analyst depends on the nature of the data used ...
Hypothesis testing involves formulating assumptions about population parameters based on sample statistics and rigorously evaluating these assumptions against empirical evidence. This article sheds light on the significance of hypothesis testing and the critical steps involved in the process.
The process of testing hypotheses follows a simple four-step procedure. This process will be what we use for the remained of the textbook and course, and though the hypothesis and statistics we use will change, this process will not.
Dec 20, 2015. There are five steps in hypothesis testing: Making assumptions. Stating the research and null hypotheses and selecting (setting) alpha. Selecting the sampling distribution and specifying the test statistic. Computing the test statistic. Making a decision and interpreting the results. Answer link.
Learn how to formulate a good, testable hypothesis for your research paper or science project, with real examples and practical advice. Enhance your academic writing with WPS AI.
Definition: statistical procedure. Hypothesis testing is a statistical procedure in which a choice is made between a null hypothesis and an alternative hypothesis based on information in a sample. The end result of a hypotheses testing procedure is a choice of one of the following two possible conclusions:
WeRosset, J. Donzé, L. profit from the concept of the fuzzy confidence interval to implement two decision rules based on two new measures called levels of acceptance and rejection, to perform fuzzy hypothesis testing. The procedure can make a decision when...